
当解决房价预测问题时,首先制作一个训练数据集,在房价的例子中,收集了过去两年的房子交易记录。房子的数据(面积、地域、采光等)作为训练集,对应的房子成交价格作为真实值。这些训练数据会随着时间的积累越来越多。然后可以创建一个神经网络模型或其他机器学习模型,先随机初始化其中的权重和偏置,再将训练数据送进模型,得到一个计算结果,即估计值。此时,由于参数是随机初始化的,这个预估值大概率不准确;接下来使用损失函数进行真实值与预估值的比较,根据比较的结果反馈,来更新新的模型权重,这个更新权重的方法被称为优化算法。
优化算法是机器学习领域的一个核心任务,简单说就是通过调整模型的参数来最小化或最大化某个目标函数(通常是损失函数或效用函数)。为了实现这一目标,研究人员和工程师们开发了多种优化算法,这些算法可以大致分为几个类别,包括梯度下降及其变体、进化算法、以及基于统计的方法。这些算法在不同的情境和对不同类型的问题中各有优势。
进化算法,如遗传算法、免疫算法、鸟群算法、鲸鱼算法、灰狼算法、蝙蝠算法、蚁群算法、模拟退火等等。这些算法一般模仿生物进化过程中的自然选择、遗传、变异等机制来迭代地改进模型参数。这些算法属于启发式搜索算法,一般用于全局优化问题。
基于统计的优化算法,如期望最大化(EM)、马尔可夫链蒙特卡罗(MCMC)方法等等,采用统计学原理来引导优化过程。例如,EM算法通过交替计算期望和最大化步骤来估计模型参数,尤其适用于包含隐变量的情况。MCMC通过构造马尔可夫链生成符合目标分布的样本序列,广泛应用于贝叶斯统计中后验分布的估计。这些算法在处理高维空间和存在多个局部最优解的复杂问题时特别有用,但是计算复杂度一般非常昂贵。
在深度学习领域,最常用的优化算法实际上是梯度下降及其变体。梯度下降是一种求解可微分函数局部最小值的迭代算法。简单说,它的工作原理是计算目标函数关于参数的梯度(即斜率),然后沿着梯度下降的方向调整参数,逐步逼近最小值点。由于其简单、高效且易于理解的特点,梯度下降成为了深度学习和其他机器学习领域中最基础和最广泛使用的优化算法。梯度下降及其变体之所以在机器学习中至关重要,是因为它们为如何有效地训练模型提供了可行的路径,特别是在处理非常大的数据集和非常复杂的模型结构时。这些算法的进一步发展和改进将继续是机器学习和人工智能领域研究的一个活跃方向。下面将重点对梯度下降算法进行展开讲解。
1、梯度下降算法
在深度学习领域使用的优化算法一般是梯度下降算法,具体解释如下:
从某种程度上,读者可以把梯度理解成某函数偏导数的集合,例如函数\(f(x,y)\)的梯度为:
\(\mathrm{grad}f(x,y)=\left(\frac{\partial f}{\partial x},\frac{\partial f}{\partial y}\right)\)
当某函数只有一个自变量时,梯度实际上就是导数的概念。
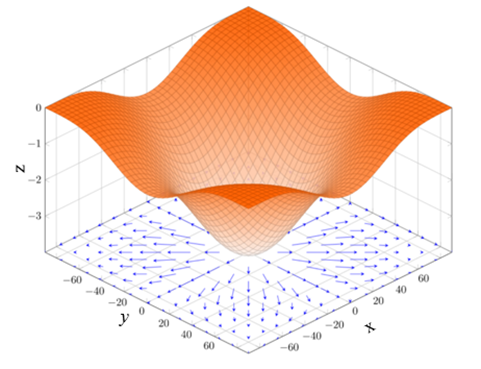
需要注意的是,梯度是一个向量,既有大小又有方向。梯度的方向是最大方向导数的方向,而梯度的模是最大方向导数的值。另外,梯度在几何上的含义是函数变化率最大的方向。沿着梯度向量的方向前进,更容易找到函数的最大值,反过来说,沿着梯度向量相反的方向前进是梯度减少最快的方向,也就是说更容易找到函数的最小值。 例如,维基百科上用来说明梯度的图片特别典型,说明非常形象,所以引来供读者学习。
【例1】设函数\(f(x,y)=-(\cos2x+\cos2y)^{2}\),则梯度\(\mathrm{grad}f(x,y)\)的几何意义可以描述为在底部平面上的矢量投影。每个点的梯度是一个矢量,其长度代表了此点的变化速度,而方向表示了其函数增长速率最快的方向。通过梯度图可以很清楚地看到,在矢量长的地方,函数增长速度就快,而其方向代表了增长最快的方向,梯度图如图1所示。
现在回到损失\(\ell\)的概念,\(\ell\)也是一种函数(例如平方差损失函数),因此要求\(\ell\)的最小值,实际上只需要沿着\(\ell\)梯度的反方向寻找即可,这就是梯度下降的概念。其公式表示为:
\(\mathrm{grad}=\frac{\partial\ell}{\partial\boldsymbol{\omega}_{t-1}}\)
\(\omega_t=\omega_{t\cdot1}-\eta\times\mathrm{grad}\)
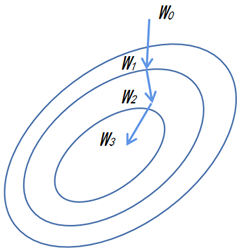
上式中-grad表示梯度的反方向,新的权重\(\boldsymbol{\omega}_{t}\)等于之前的权重\(\boldsymbol{\omega}_{t-1}\)向梯度的反方向前进\(\eta\times\mathrm{grad}\)的量。图1中的函数平面化后表示的梯度下降过程如图2所示。
(1)随机初始化一个初始值\(\omega_{_0}\)。
(2)重复迭代梯度下降算法,即\(\boldsymbol{\omega}_{t}=\boldsymbol{\omega}_{t-1}-\eta\times\mathrm{grad}(t=1,2,3)\)。
(3)此时,更新后的权重会比之前的权重得到一个更小的函数值,即\(\ell(\omega_0)>\ell(\omega_1)>\ell(\omega_2)\cdots\approx\ell_{\min}\)。
(4)\(\eta\)是学习率的意思,表征参数更新的快慢,通过\(\eta\times\mathrm{grad}\)直接影响参数的更新速度。
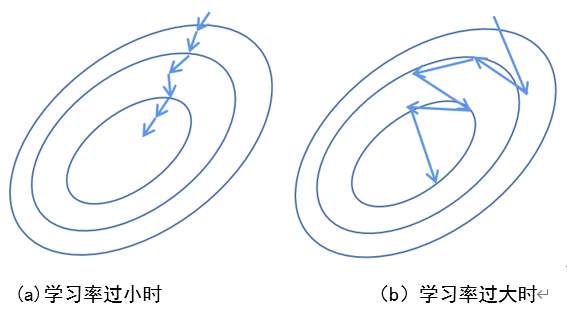
当学习率过小时,更新速度太慢,如图3(a)所示;当学习率过大时,容易出现梯度震荡,如图3(b)所示,这些都是不好的影响。
需要注意的是,学习率是直接决定深度学习模型训练成功与否的关键因素。当一个深度学习模型效果不好或者训练失败时,不一定是模型设计的原因,也可能是训练策略所导致,其中学习率就是训练策略的主要因素之一。在训练时往往会先选择一个较小的学习率(例如0.0001)进行训练,再逐步调大学习率来观察模型的训练结果。此外,训练数据集也会直接影响模型的效果,即模型的效果=训练集+模型设计+训练策略。
最后,在有监督训练深度学习模型时,往往不会在一次计算中使用全部的数据集,因为训练数据集往往很大,全部使用时计算资源和内存会不够用。因此,一般情况下会采用一种被称为小批量随机梯度下降的算法。具体的方法是从训练数据集中随机采用\(\text{b}\)个样本\(i_{1},i_{2},\cdots,i_{b}\)来近似损失,此时损失的表示如下:
\(\frac{1}{b}\sum_{i\in I_b}\ell(x_i,y_i,\omega)\)
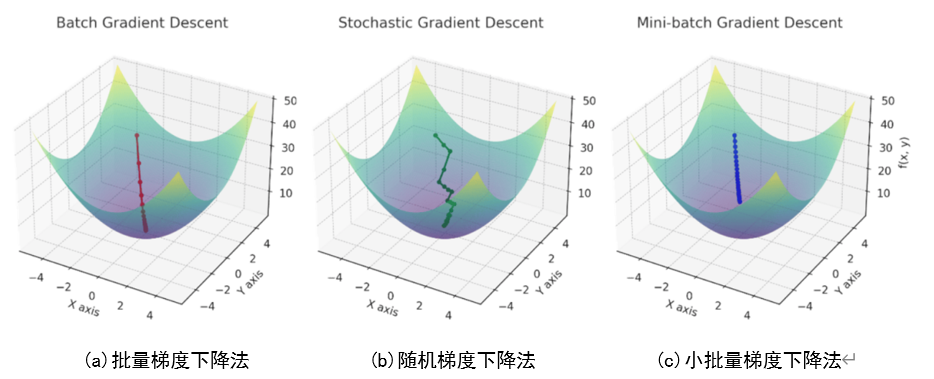
其中\(\text{b}\)代表批量大小,是一个深度学习训练过程中重要的超参数。当\(\text{b}\)太小时,每次计算量太小,不适合最大程度利用并行资源;更重要的是,\(\text{b}\)太小意味着从训练数据集中抽样的样本子集数量少,此时子集的数据分布可能与原始数据集相差较大,并不能很好地代替原始数据集。当\(\text{b}\)太大时,可能会导致存储或计算资源不足。根据\(\text{b}\)的大小,梯度下降算法可以分为批量梯度下降法(Batch Gradient Descent,BGD)、随机梯度下降法(Stochastic Gradient Descent,SGD), 以及小批量梯度下降法(Mini-batch Gradient Descent,MBGD)。
批量梯度下降法是梯度下降法常用的形式,具体做法是在更新参数时使用所有的样本来进行更新。由于需要计算整个数据集的梯度,将导致梯度下降法的速度可能非常缓慢,且对于内存小而数据集庞大的情况十分棘手。而批量梯度下降法的优点是理想状态下,经过足够多的迭代后可以达到全局最优。
随机梯度下降法和批量梯度下降法原理类似,区别在于随机梯度下降法在求梯度时没有用所有的样本数据,而是仅仅选取一个样本来求梯度。正是为了加快收敛速度,并且解决大数据量无法一次性塞入内存的问题。但是由于每次只用一个样本来更新参数,随机梯度下降法会导致不稳定。每次更新的方向,不像批量梯度下降法那样每次都朝着最优点的方向逼近,而是会在最优点附近震荡。
其实,批量梯度下降法与随机梯度下降法是两个极端,前者采用所有数据来进行梯度下降,如图4(a)所示;后者采用一个样本来进行梯度下降,如图4(b)所示。两种方法的优缺点都非常突出,对于训练速度来说,随机梯度下降法由于每次仅仅采用一个样本来迭代,训练速度很快;而批量梯度下降法在样本量很大的时候,训练速度不能让人满意。对于准确度来说,随机梯度下降法仅仅用一个样本决定梯度方向,导致有可能不是最优解。对于收敛速度来说,由于随机梯度下降法一次迭代一个样本,导致迭代方向变化很大,不能很快地收敛到局部最优解。那么,有没有一个办法能够结合两种方法的优点呢?
这就是小批量梯度下降法,如图4(c)所示。即每次训练从整个数据集中随机选取一个小批量样本用于模型训练,这个小批量样本的大小是超参数,一般来说越大越准,当然训练也会越慢。
2、反向传播算法
梯度下降和反向传播是神经网络训练过程中两个非常重要的概念,它们密切相关。梯度下降是一种常用的优化算法,它的目标是找到一个函数的最小值或最大值。在神经网络中,梯度下降算法通过调整每个神经元的权重,以最小化网络的损失函数。损失函数是用来衡量网络的输出与真实值之间的误差。梯度下降算法的核心思想是计算损失函数对权重的偏导数,然后按照这个偏导数的反方向调整权重。
反向传播是一种有效的计算梯度的方法,它可以快速计算网络中每个神经元的偏导数。反向传播通过先正向传播计算网络的输出,然后从输出层到输入层反向传播误差,最后根据误差计算每个神经元的偏导数。反向传播算法的核心思想是通过链式法则将误差向后传递,计算每个神经元对误差的贡献。
综上所述,梯度下降和反向传播是神经网络训练过程中两个重要的概念,梯度下降算法用于优化网络的权重,反向传播算法用于计算每个神经元的偏导数。它们密切相关,并在神经网络的训练中起着重要的作用。
【例2】神经网络层参数更新的完整过程。
(1)初始化网络,构建一个只有一层的神经网络,如图5所示。
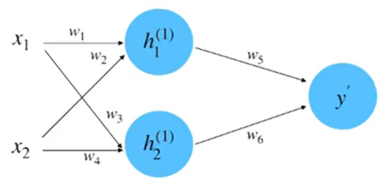
假设图5中神经网络的输入和输出的初始化为:\(x_{1}=0.5,x_{2}=1.0,y=0.8\)。参数的初始化为:\(w_{1}=1.0,w_{2}=0.5,w_{3}=0.5,w_{4}=0.7,w_{5}=1.0,w_{6}=2.0\)。
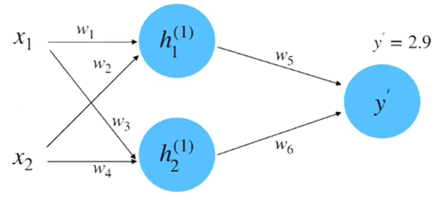
(2)前向计算,如图6所示。
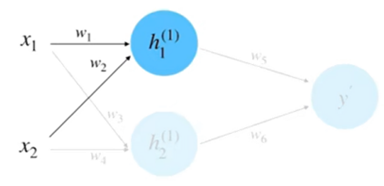
根据输入和权重计算\(h_{1}\)得:
\(\begin{aligned}h_{1}^{(1)}&=w_1\cdot x_1+w_2\cdot x_2\\&=1.0\cdot0.5+0.5\cdot1.0\\&=1.0\end{aligned}\)
同理,计算\(h_{2}\)等于0.95。将\(h_{1}\)和\(h_{2}\)相乘求和到前向传播的计算结果,如图7所示。
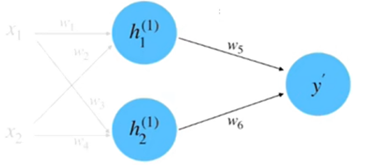
\(\begin{aligned}y^{\prime}&=w_{5}\cdot h_{1}^{(1)}+w_{6}\cdot h_{2}^{(1)}\\&=1.0\cdot1.0+2.0\cdot0.95\\&=2.9\end{aligned}\)
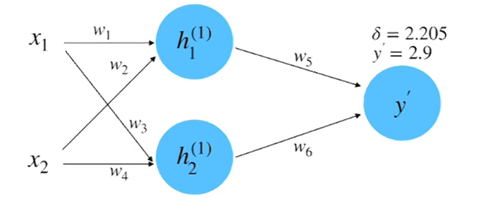
(3)计算损失:根据数据真实值\(y=0.8\)和平方差损失函数来计算损失,如图8所示。
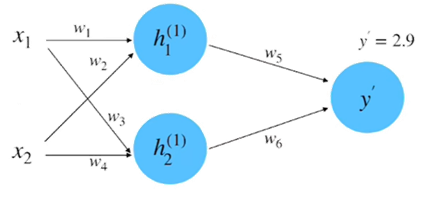
\(\begin{aligned}\delta&=\frac{1}{2}(y-y^{\prime})^{2}\\&=0.5(0.8-2.9)^{2}\\&=2.205\end{aligned}\)
(4)计算梯度:此过程实际上就是计算偏微分的过程,以参数\(w_{5}\)的偏微分计算为例,如图9所示。
根据链式法则:
\(\frac{\partial\delta}{\partial w_5}=\frac{\partial\delta}{\partial y^{\prime}}\cdot\frac{\partial y^{\prime}}{\partial w_5}\)
其中:
\(\begin{aligned}\frac{\partial\delta}{\partial y^{\prime}}&=2\cdot\frac{1}{2}\cdot(y-y^{\prime})(-1)\\&=y^{\prime}-y\\&=2.9-0.8\\&=\begin{array}{c}{2.1}\end{array}\end{aligned}\)
\(y^{\prime}=w_5\cdot h_1^{(1)}+w_6\cdot h_2^{(1)}\)
\(\begin{aligned}\frac{\partial y^{\prime}}{\partial w_{5}}&=h_{1}^{(1)}+0\\&=1.0\end{aligned}\)
所以:
\(\frac{\partial\delta}{\partial w_5}=\frac{\partial\delta}{\partial y^{\prime}}\cdot\frac{\partial y^{\prime}}{\partial w_5}=2.1\times1.0=2.1\)
(5)反向传播计算梯度:在第4步中是以参数\(w_{5}\)为例子来计算偏微分的。如果以参数\(w_{1}\)为例子,它的偏微分计算就需要用到链式法则,过程如图10所示。
\(\frac{\partial\delta}{\partial w_{1}}=\frac{\partial\delta}{\partial y^{\prime}}\cdot\frac{\partial y^{\prime}}{\partial h_{1}^{(1)}}\cdot\frac{\partial h_{1}^{(1)}}{\partial w_{1}}\)
\(y^{\prime}=w_5\cdot h_1^{(1)}+w_6\cdot h_2^{(1)}\)
\(\begin{aligned}\frac{\partial y^{\prime}}{\partial h_1^{(1)}}&=w_5+0\\&=1.0\end{aligned}\)
\(h_1^{(1)}=w_1\cdot x_1+w_2\cdot x_2\)
\(\begin{aligned}\frac{\partial h_1^{(1)}}{\partial w_1}&=x_1+0\\&=0.5\end{aligned}\)
\(\frac{\partial\delta}{\partial w_1}=\frac{\partial\delta}{\partial y^{\prime}}\cdot\frac{\partial y^{\prime}}{\partial h_1^{(1)}}\cdot\frac{\partial h_1^{(1)}}{\partial w_1}=2.1\times1.0\times0.5=1.05\)
(6)梯度下降更新网络参数
假设这里的超参数“学习速率”的初始值为0.1,根据梯度下降的更新公式,\(w_{1}\)参数的更新计算如下所示:
\(w_1^{(\mathrm{update})}=w_1-\eta\cdot\frac{\partial\delta}{\partial w_1}=1.0-0.1\times1.05=0.895\)
同理,可以计算得到其他的更新后的参数:
\(w_1=0.895,w_2=0.895,w_3=0.29,w_4=0.28,w_5=0.79,w_6=1.8005\)
到此为止,我们就完成了参数迭代的全部过程。可以计算一下损失看看是否有减小,计算如下:
\(\begin{aligned}\delta=&\frac{1}{2}(y-y^{\prime})^{2}\\&=0.5(0.8-1.3478)^{2}\\&=0.15\end{aligned}\)
此结果相比较于之前计算的前向传播的结果2.205,是有明显的减小的。
SGD优化器
随机梯度下降(SGD)是一种广泛用于训练机器学习模型的优化算法,其核心思想是通过计算损失函数关于模型参数的梯度,并沿着梯度的反方向更新参数,以最小化损失函数。SGD每次更新仅使用一个或一小批样本,计算效率高,但可能面临收敛慢和振荡问题。为了解决这些问题,动量(Momentum)成为SGD的关键技术点之一。动量通过引入历史梯度信息,累积之前的更新方向,从而加速收敛并减少振荡,使优化过程更加稳定和高效。
梯度下降过程中,用指数移动平均融合历史的梯度,收敛速度和稳定性都有显著收益,其中历史梯度被称为动量项(Momentum)。带动量的SGD优化步骤如下:
\(m_t=\beta m_{t-1}+(1-\beta)g_t\)
\(\omega_{t}=\omega_{t-1}-\eta m_{t}\)
其中,\(m_{_{t-1}}\)是上一时刻的梯度,\(m_{_{t}}\)是用EMA融合历史梯度后的梯度,\(\mathbf{g}_{t}\)是当前时刻的梯度。\(\mathrm{β}\)是一个超参数,\(\beta m_{_{t-1}}\)被称为动量项。由EMA的原理可知,虽然上式里只用到了上一时刻的梯度,但其实是当前时刻之前的所有历史梯度的指数平均。
加入动量项后进行模型权重的更新,比直接用原始梯度值,抖动更小更加稳定,也可以快速冲过误差曲面(Error Surface)上的鞍点等比较平坦的区域。其原理可以想象成滑雪运动,当前的运动趋势总会受到之前动能的影响,所以滑雪的曲线才比较优美平滑,不可能划出90°这样陡峭的直角弯;当滑到谷底时,虽然地势平坦,但是由于之前动能的影响,也会继续往前滑,有可能借助动量冲出谷底。
小结一下,加入动量项的好处如下:
(1)在下降初期时,动量方向与当前梯度方向一致,能够进行很好的收敛加速效果。
(2)在下降后期时,梯度可能在局部最小值附近震荡,动量可能帮助跳出局部最小值。
(3)在梯度改变方向时,动量能够抵消方向相对的梯度,抑制振荡,从而加快收敛。
加入动量的梯度下降公式还有另一种简单的实现,即:
\(g_{i}=\beta g_{i-1}+g(\theta_{i-1})\)
\(\theta_i=\theta_{i-1}-\alpha\boldsymbol{g}_i\)
AdaGrad优化器
动量是优化小批量梯度下降算法的方法之一。另一个方法被称为AdaGrad算法,主要是对学习率做了进一步的优化。其参数更新的公式如下:
\(r_{_k}\leftarrow r_{_{k-1}}+g\odot g\)
\(\theta_{_k}\leftarrow\theta_{_{k-1}}-\frac{\eta}{\sqrt{r_{_k}+\sigma}}\odot g\)
从上式可以看出,与普通的梯度下降公式相比,$\eta$ 变成了\(\frac{\eta}{\sqrt{r_i+\sigma}}\),其中\(\sigma\)是一个值极小的实数,防止除零的情况。而\(r_{k}\)是之前时刻梯度平方的累加值,这里考虑两个问题:
- 梯度为什么要平方?
- 以及为什么要做累加?
梯度平方的作用是为了平滑当前的梯度,如果\(\mathrm{g}\)比较小,\(g\odot g\)就会更小,\(r_{k}\)就会小, \(\frac{1}{\sqrt{r_{i}+\sigma}}\)就会相对较大,这时候起到了放大学习率\(\eta\)的作用。反之,如果\(\mathrm{g}\)比较大,学习率\(\eta\)就会减小。
累加历史梯度是为了让学习率随着训练的进行逐渐减小。由于累加的作用,\(r_{k}\)会越来越大,\(\frac{\eta}{\sqrt{r_k+\sigma}}\)就会随着训练越来越小。这是一个合适的学习率调节策略,就像打高尔夫球一样,可以把学习率看作挥球杆的力度,刚开始打球的时候肯定是大力,希望快速接近球洞;打球后期的时候需要用小力,将球慢慢打进洞。
当然,AdaGrad算法也有缺点。首先由公式可以看出,它仍依赖于人工设置一个全局学习率。其次\(\eta\)设置过大的话,会使\(\sqrt{r_{k}+\sigma}\)过于敏感,对梯度的调节太大。最后在训练中后期,分母上梯度平方的累加将会越来越大,使\(\mathrm{gradient}\to0\),可能会使训练提前结束。
RMSprop优化器
RMSprop算法是AdaGrad算法的一种发展,对于循环神经网络效果很好,本质上就是在\(r_{k}\)中融入EMA的思想,公式如下:
\(r_{_k}\leftarrow\beta r_{_{k-1}}+(1-\beta)g\odot g\)
\(\theta_{_k}\leftarrow\theta_{_{k-1}}-\frac{\eta}{\sqrt{r_{_k}+\sigma}}\odot g\)
目的是在累加历史梯度平方时,给近期的梯度以更大的权重,而不是一味地累积,最后导致梯度为0。虽然RMSprop可以更好地自动调节学习率,但其实依然依赖于全局学习率的初值设置。
Adam优化器
最后,Adam算法可以说是深度学习领域中最常用的优化算法,因为它融合了其他优化算法的优点,可以看作是带有动量项的RMSprop优化器,并在此基础上还做了进一步的优化,避免了冷启动的问题。它的计算过程如下:
输入:学习率\(\varepsilon\),初始参数\(\theta\),小常数\(\mathrm{σ}\),累计梯度\(_{\nu}\),累计平方梯度\(\mathrm{r}\),衰减系数\(\rho\),动量参数\(\alpha\)。
从训练集中采集\(\mathrm{m}\)个样本$\lbrace{x^1, x^2, \ldots, x^m} \rbrace$ ,其中数据\(x^{(i)}\)和对应目标\(y^{(i)}\)计算梯度:
\(g\leftarrow\frac{1}{m}\nabla_{\theta_{k-1}}L(f(x^{(i)},\theta_{_{k-1}}),y^{(i)})\)
计算累计梯度:\(v_{t}=\alpha v{_{t-1}}+(1-\alpha)g\)(即,加入动量项);
计算累计平方梯度:\(r_{t}=\rho r_{t-1}+(1-\rho)g\odot g\)(即,通过RMSprop算法实现学习率的调节);
修正:\(\hat{\nu}{t}=\frac{\nu{t}}{1-\alpha}\),\(\hat{r}{t}=\frac{r{t}}{1-\rho}\)。
更新参数:\(\theta_{k}\leftarrow\theta{{k-1}}-\varepsilon\frac{\hat{v}{t}}{\sqrt{\hat{r}{_t}+\sigma}}\)
这里解释一下什么叫冷启动,假设:衰减系数= 0.999,动量参数= 0.9。
那么,当训练刚开始的时候:
\(v=0.9\times0+0.1\times g=0.1g\)
\(r=0.999\times0+0.001\times g^2=0.001g^2\)
\(\text{r}\)和\(\nu\)在初始训练时都很小,意味着初始训练时梯度很小,参数更新很慢。而修正后:
\(V=\frac{v}{1-0.9}=\frac{0.1\boldsymbol{g}}{0.1}=\boldsymbol{g}\)
\(R=\frac{r}{1-0.999}=\frac{0.001\boldsymbol{g}^2}{0.001}=\boldsymbol{g}^2\)
通过这样的方法可以一定程度的避免冷启动的问题。
作者
arwin.yu.98@gmail.com





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}