
Learning Methods of Deep Learning
create by Deepfinder
 Agenda
Agenda
- 师徒相授:有监督学习(Supervised Learning)
- 见微知著:无监督学习(Un-supervised Learning)
- 无师自通:自监督学习(Self-supervised Learning)
- 以点带面:半监督学习(Semi-supervised learning)
- 明辨是非:对比学习(Contrastive Learning)
- 举一反三:迁移学习(Transfer Learning)
- 针锋相对:对抗学习(Adversarial Learning)
- 众志成城:集成学习(Ensemble Learning)
- 殊途同归:联邦学习(Federated Learning)
- 百折不挠:强化学习(Reinforcement Learning)
- 求知若渴:主动学习(Active Learning)
- 万法归宗:元学习(Meta-Learning)
Tutorial 08 - 众志成城:集成学习(Ensemble Learning)
在机器学习和深度学习中,单一模型的性能往往受到模型复杂度、数据质量以及训练方法等诸多因素的限制。
为了解决这些问题,集成学习(Ensemble Learning)提供了一种强大的方法,将多个模型的预测结果结合起来,从而提升模型的整体性能、鲁棒性和泛化能力。
集成学习在传统机器学习中有着广泛应用,比如随机森林(Random Forest)和梯度提升树(Gradient Boosting Trees)。近年来,随着深度学习的快速发展,集成学习的思想也被成功引入到深度学习中,为解决复杂任务(如图像分类、自然语言处理等)带来了更优的表现。
 集成学习的核心概念
集成学习的核心概念
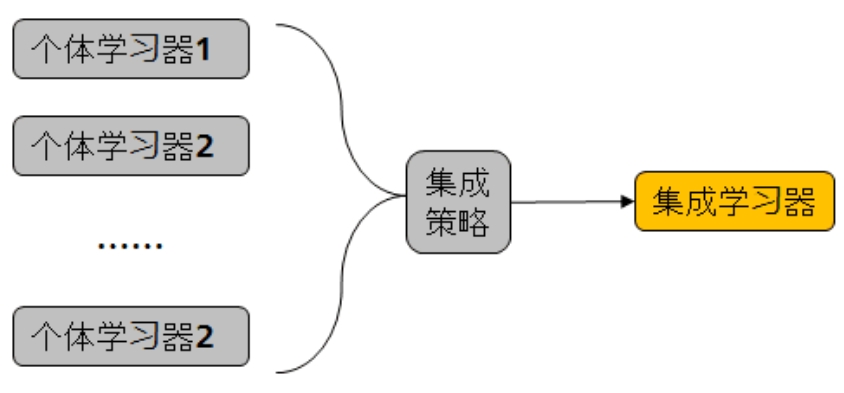
集成学习的基本思想是通过组合多个基模型(Base Model)的预测结果,达到“众人拾柴火焰高”的效果。其核心包括以下几点:
- 基模型(Base Model)
基模型是参与集成的单一模型。对于深度学习而言,基模型可以是卷积神经网络(CNN)、循环神经网络(RNN)等。
- 集成策略
- Bagging(Bootstrap Aggregating):通过对数据集进行重采样,训练多个独立的基模型(如随机森林)。
- Boosting:通过加权学习,逐步优化每个基模型,使其在上一轮中表现较差的数据上改进(如 AdaBoost 和梯度提升)。
- Stacking(堆叠泛化):使用一个元学习器(Meta-Learner)结合多个基模型的输出。
- 投票机制
- 硬投票:基于每个模型的分类结果进行多数投票。
- 软投票:结合每个模型的预测概率,取加权平均或最高概率值。
- 通过以上策略,集成学习能够有效减少单一模型的过拟合风险,同时利用不同模型的互补优势来提升整体性能。
 深度学习中的集成学习
深度学习中的集成学习
结合深度学习,集成学习在以下几个方面具有独特的价值:
- 模型平均:多个模型的预测结果通过简单平均或加权平均融合,能够缓解单个模型的预测偏差。
- 模型堆叠:多个模型的输出作为特征输入,利用轻量级学习器(如逻辑回归或浅层神经网络)学习更好的预测规则。
- 模型多样性:不同网络架构、训练策略和数据增强技术的使用,有助于提高集成模型的鲁棒性。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import numpy as np
# 检查 GPU 是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 数据预处理
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
train_dataset = datasets.CIFAR10(root='datasets', train=True, download=True, transform=transform)
test_dataset = datasets.CIFAR10(root='datasets', train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
# 定义简单的 CNN 模型
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(64 * 16 * 16, 128) # 修正全连接层输入大小
self.fc2 = nn.Linear(128, 10)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.conv1(x))
x = self.pool(self.relu(self.conv2(x)))
x = x.view(x.size(0), -1) # 展平为 [batch_size, features]
x = self.relu(self.fc1(x))
x = self.fc2(x)
return x
# 定义元模型(神经网络)
class MetaModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(MetaModel, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.fc2(x)
return xFiles already downloaded and verified
Files already downloaded and verified# 模型训练函数
def train_model(model, train_loader, epochs=10):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
model.to(device) # 将模型移动到 GPU
for epoch in range(epochs):
model.train()
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device) # 将数据移动到 GPU
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 测试集评估
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device) # 将数据移动到 GPU
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
return correct / total
# 获取基模型的输出
def get_predictions(models, loader):
outputs_list = []
labels_list = []
with torch.no_grad():
for images, labels in loader:
images, labels = images.to(device), labels.to(device) # 将数据移动到 GPU
# 获取所有基模型的输出
model_outputs = [model(images) for model in models]
outputs_list.append(torch.cat(model_outputs, dim=1)) # 将基模型的输出拼接在一起
labels_list.append(labels) # 获取标签
return torch.cat(outputs_list, dim=0), torch.cat(labels_list, dim=0)# 集成学习(Bagging)
def bagging_ensemble(models, test_loader):
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device) # 将数据移动到 GPU
# 获取所有基模型的预测结果
outputs = torch.stack([model(images) for model in models], dim=0)
# 对多个模型的输出取平均
avg_outputs = torch.mean(outputs, dim=0)
_, predicted = torch.max(avg_outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
return correct / total# Boosting 的训练与集成
def boosting_ensemble(models, train_loader, test_loader, num_epochs=10):
model_weights = np.ones(len(models)) # 初始化每个模型的权重为1
model_accuracies = [] # 保存每个模型的准确率
# 训练每个模型并计算其准确率
for model in models:
accuracy = train_model(model, train_loader, epochs=num_epochs)
model_accuracies.append(accuracy)
# 调整模型的权重,根据准确率调整
total_accuracy = np.sum(model_accuracies)
model_weights = model_accuracies / total_accuracy # 根据准确率计算权重
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device) # 将数据移动到 GPU
# 获取所有基模型的预测结果
outputs = torch.stack([model(images) for model in models], dim=0)
# 将权重转换为 tensor 并确保其在相同设备上
weighted_outputs = torch.sum(outputs * torch.tensor(model_weights, device=device).view(-1, 1, 1), dim=0)
_, predicted = torch.max(weighted_outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
return correct / total# Stacking 集成方法
def stacking_ensemble(models, meta_model, train_loader, test_loader, epochs=20):
# 获取训练集和测试集的基模型输出
X_train, y_train = get_predictions(models, train_loader)
X_test, y_test = get_predictions(models, test_loader)
# 对基模型的输出进行 softmax 归一化
X_train = torch.softmax(X_train, dim=1)
X_test = torch.softmax(X_test, dim=1)
# 训练元模型
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(meta_model.parameters(), lr=0.001, weight_decay=1e-4) # 增加权重衰减正则化
meta_model.to(device) # 将元模型移动到 GPU
X_train, y_train = X_train.to(device), y_train.to(device)
X_test, y_test = X_test.to(device), y_test.to(device)
# 划分训练集和验证集
dataset_size = X_train.size(0)
indices = torch.randperm(dataset_size)
split = int(dataset_size * 0.8) # 80% 训练,20% 验证
train_indices, val_indices = indices[:split], indices[split:]
X_train_split, y_train_split = X_train[train_indices], y_train[train_indices]
X_val, y_val = X_train[val_indices], y_train[val_indices]
best_accuracy = 0.0
for epoch in range(epochs):
meta_model.train()
optimizer.zero_grad()
outputs = meta_model(X_train_split)
loss = criterion(outputs, y_train_split)
loss.backward()
optimizer.step()
# 验证集评估
meta_model.eval()
with torch.no_grad():
val_outputs = meta_model(X_val)
_, val_predicted = torch.max(val_outputs, 1)
val_accuracy = (val_predicted == y_val).float().mean().item()
# 保存最佳模型
if val_accuracy > best_accuracy:
best_accuracy = val_accuracy
torch.save(meta_model.state_dict(), 'best_meta_model.pth')
# 加载最佳模型
meta_model.load_state_dict(torch.load('best_meta_model.pth', weights_only=True))
# 测试集评估
meta_model.eval()
with torch.no_grad():
outputs = meta_model(X_test)
_, predicted = torch.max(outputs, 1)
accuracy = (predicted == y_test).float().mean().item()
return accuracy
# 基线模型:训练一个单一的网络
def baseline_model(train_loader, test_loader):
model = SimpleCNN().to(device)
accuracy = train_model(model, train_loader)
return accuracy
# 训练基线模型
baseline_accuracy = baseline_model(train_loader, test_loader)
print(f"Baseline model accuracy: {baseline_accuracy * 100:.2f}%")Baseline model accuracy: 68.07%# 主程序
num_models = 3 # 假设我们训练3个模型
models = [SimpleCNN() for _ in range(num_models)]
# 训练所有模型(Bagging 和 Boosting 需要)
for model in models:
train_model(model, train_loader, epochs=5)
# 使用 Bagging 方法进行模型集成
bagging_accuracy = bagging_ensemble(models, test_loader)
print(f"Bagging accuracy: {bagging_accuracy * 100:.2f}%")
# 使用 Boosting 方法进行模型训练
boosting_accuracy = boosting_ensemble(models, train_loader, test_loader, num_epochs=5)
print(f"Boosting accuracy: {boosting_accuracy * 100:.2f}%")
# 使用 Stacking 方法进行模型集成
input_size = 10 * num_models # 每个基模型输出10个类别,拼接后的输入大小
meta_model = MetaModel(input_size, hidden_size=64, output_size=10) # 使用神经网络作为元模型
stacking_accuracy = stacking_ensemble(models, meta_model, train_loader, test_loader, epochs=100)
print(f"Stacking accuracy: {stacking_accuracy * 100:.2f}%")
Bagging accuracy: 73.26%
Boosting accuracy: 73.35%
Stacking accuracy: 71.43%作者
arwin.yu.98@gmail.com





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}