
Learning Methods of Deep Learning
create by Deepfinder
 Agenda
Agenda
- 师徒相授:有监督学习(Supervised Learning)
- 见微知著:无监督学习(Un-supervised Learning)
- 无师自通:自监督学习(Self-supervised Learning)
- 以点带面:半监督学习(Semi-supervised learning)
- 明辨是非:对比学习(Contrastive Learning)
- 举一反三:迁移学习(Transfer Learning)
- 针锋相对:对抗学习(Adversarial Learning)
- 众志成城:集成学习(Ensemble Learning)
- 殊途同归:联邦学习(Federated Learning)
- 百折不挠:强化学习(Reinforcement Learning)
- 求知若渴:主动学习(Active Learning)
- 万法归宗:元学习(Meta-Learning)
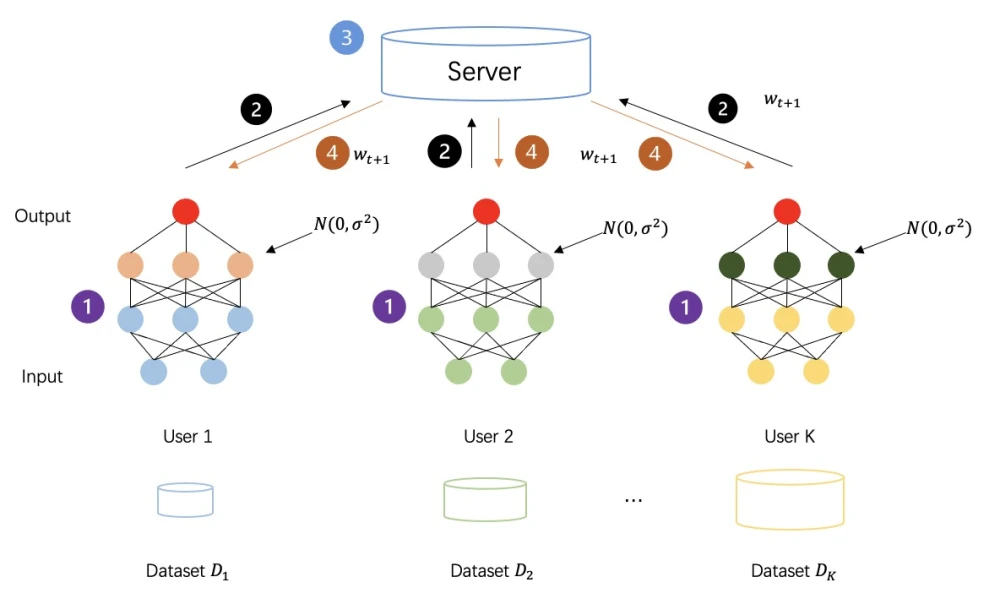
Tutorial 09 - 殊途同归:联邦学习(Federated Learning)
在当今大数据时代,数据是驱动人工智能(AI)和机器学习(ML)发展的核心资源。然而,数据的分散性和隐私保护需求对传统的集中式机器学习方法提出了巨大挑战。集中式机器学习通常需要将所有数据上传到中央服务器进行训练,这不仅带来了数据隐私泄露的风险,还可能导致数据传输和存储的高成本。为了解决这些问题,联邦学习(Federated Learning, FL) 应运而生。
联邦学习是一种分布式机器学习框架,允许多个参与方(如移动设备、企业或机构)在不共享原始数据的情况下,协同训练一个全局模型。这种方法不仅保护了数据隐私,还充分利用了分散的计算资源。本文将介绍联邦学习的基本概念、技术优势,并通过一个基于MNIST数据集的联邦学习项目,展示其实际应用。
 联邦学习的基本概念
联邦学习的基本概念
联邦学习的核心思想是数据不动,模型动。具体来说,联邦学习包括以下几个关键步骤:
- 本地训练:
-
每个参与方(客户端)在本地使用自己的数据训练模型。
-
训练完成后,客户端将模型更新(如权重或梯度)发送给中央服务器。
- 模型聚合:
- 中央服务器收集所有客户端的模型更新,并通过聚合算法(如联邦平均,FedAvg)生成一个全局模型。
- 模型分发:
-
中央服务器将更新后的全局模型分发给所有客户端。
-
客户端使用新的全局模型继续本地训练。
通过多次迭代,全局模型逐渐收敛,最终达到与集中式训练相当的性能。
 联邦学习的技术优势
联邦学习的技术优势
- 隐私保护:
-
联邦学习不需要将原始数据上传到中央服务器,避免了数据泄露的风险。
-
通过差分隐私、同态加密等技术,可以进一步增强隐私保护。
- 数据分布多样性:
- 联邦学习能够处理非独立同分布(Non-IID)数据,适应现实世界中数据的多样性。
- 资源高效利用:
- 联邦学习充分利用了客户端的计算资源,减轻了中央服务器的负担。
- 合规性:
- 联邦学习符合数据隐私保护法规(如GDPR),适用于医疗、金融等对数据隐私要求严格的领域。
 联邦学习的应用场景
联邦学习的应用场景
联邦学习在许多领域具有广泛的应用前景,包括但不限于:
-
医疗健康: 不同医院可以在不共享患者数据的情况下,协同训练疾病诊断模型。
-
金融风控: 银行和金融机构可以联合训练信用评分模型,同时保护客户隐私。
-
智能设备: 智能手机、智能家居设备可以在本地训练个性化模型,提升用户体验。
-
智慧城市: 城市中的传感器和设备可以协同训练交通流量预测、环境监测等模型。
 基于MNIST数据集的联邦学习项目
基于MNIST数据集的联邦学习项目
为了帮助读者更好地理解联邦学习的实现过程,我实现了一个基于MNIST数据集的联邦学习项目。MNIST是一个经典的手写数字识别数据集,包含60,000张训练图像和10,000张测试图像。在该项目中,我们模拟了多个客户端(如移动设备或机构)协同训练一个手写数字识别模型的过程。
项目特点:
-
数据分布: 将MNIST数据集划分为多个子集,每个子集分配给一个客户端,模拟现实中的数据分布。
-
本地训练: 每个客户端在本地使用自己的数据训练模型,并将模型更新发送给中央服务器。
-
模型聚合: 中央服务器使用联邦平均算法聚合客户端的模型更新,生成全局模型。
-
模型评估: 在每次联邦学习迭代后,评估全局模型在测试集上的性能。
技术实现:
-
使用PyTorch框架构建神经网络模型。
-
使用联邦平均算法实现模型聚合。
-
通过多次迭代,逐步提升全局模型的准确率。
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
from torchvision import datasets, transforms
# 加载 MNIST 数据集
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transforms.ToTensor())
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transforms.ToTensor())
# 转换为 NumPy 数组
xTrain = train_dataset.data.numpy().reshape(-1, 784) / 255.0
yTrain = train_dataset.targets.numpy() # 已经是类别索引
xTest = test_dataset.data.numpy().reshape(-1, 784) / 255.0
yTest = test_dataset.targets.numpy() # 已经是类别索引
# 全局参数
batch_size = 64
epochs = 5
# 将数据转换为 PyTorch 张量
xTrain_tensor = torch.tensor(xTrain, dtype=torch.float32)
yTrain_tensor = torch.tensor(yTrain, dtype=torch.long) # 使用 torch.long 表示类别索引
xTest_tensor = torch.tensor(xTest, dtype=torch.float32)
yTest_tensor = torch.tensor(yTest, dtype=torch.long) # 使用 torch.long 表示类别索引
# 创建 DataLoader
train_dataset = TensorDataset(xTrain_tensor, yTrain_tensor)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_dataset = TensorDataset(xTest_tensor, yTest_tensor)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 模型定义
class DeepModel(nn.Module):
def __init__(self):
super(DeepModel, self).__init__()
self.fc1 = nn.Linear(784, 64)
self.fc2 = nn.Linear(64, 10)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.fc2(x)
return x
# 训练函数
def train(model, train_loader, criterion, optimizer, epochs):
history = {'accuracy': [], 'val_accuracy': [], 'loss': [], 'val_loss': []}
for epoch in range(epochs):
model.train()
running_loss = 0.0
correct = 0
total = 0
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels) # labels 是类别索引
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1) # predicted 是类别索引
total += labels.size(0)
correct += (predicted == labels).sum().item() # 直接比较类别索引
epoch_loss = running_loss / len(train_loader)
epoch_accuracy = correct / total
history['loss'].append(epoch_loss)
history['accuracy'].append(epoch_accuracy)
print(f'Epoch {epoch + 1}, Loss: {epoch_loss}, Accuracy: {epoch_accuracy}')
return history
# 初始化模型、损失函数和优化器
nonFmodel = DeepModel()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(nonFmodel.parameters(), lr=0.0001)
# 训练模型
history = train(nonFmodel, train_loader, criterion, optimizer, epochs)Epoch 1, Loss: 1.0643141178179905, Accuracy: 0.7744
Epoch 2, Loss: 0.4311890813238077, Accuracy: 0.8908833333333334
Epoch 3, Loss: 0.3416135678889909, Accuracy: 0.9067833333333334
Epoch 4, Loss: 0.3032634595532153, Accuracy: 0.9153333333333333
Epoch 5, Loss: 0.2790384936148424, Accuracy: 0.9215333333333333
numOfClients = 5 # 客户端数量
numOfIterations = 5 # 联邦学习迭代次数
clientDataInterval = len(xTrain) // numOfClients # 每个客户端的数据量
xClientsList = []
yClientsList = []
for clientID in range(numOfClients):
start = clientID * clientDataInterval
end = start + clientDataInterval
xClientsList.append(xTrain_tensor[start:end])
yClientsList.append(yTrain_tensor[start:end])import matplotlib.pyplot as plt
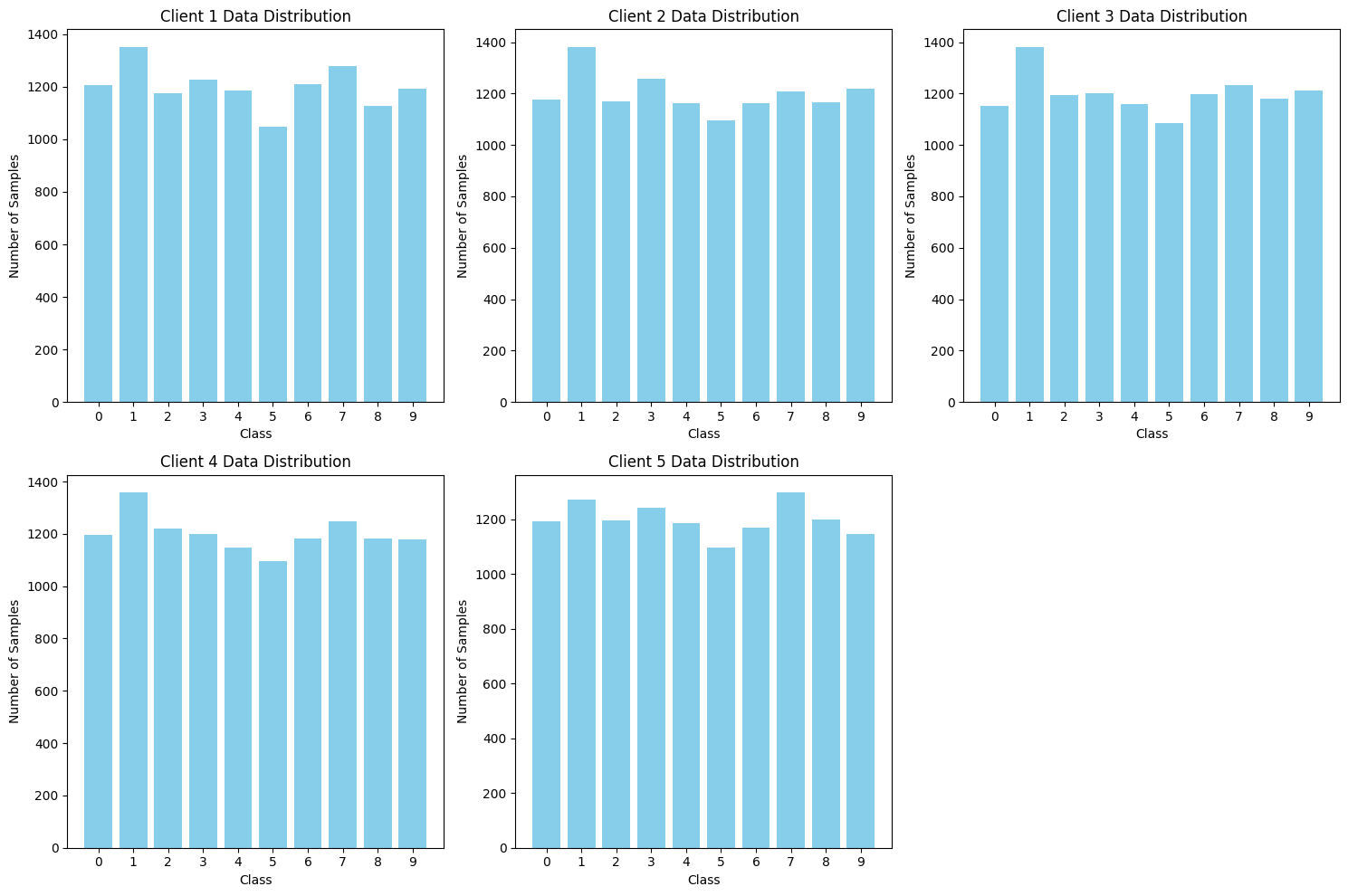
def plot_client_data_distribution(yClientsList, numOfClients):
plt.figure(figsize=(15, 10))
for clientID in range(numOfClients):
# 统计每个类别的样本数量
class_counts = np.bincount(yClientsList[clientID].numpy(), minlength=10)
# 绘制柱状图
plt.subplot(2, 3, clientID + 1) # 2 行 3 列的子图布局
plt.bar(range(10), class_counts, color='skyblue')
plt.title(f'Client {clientID + 1} Data Distribution')
plt.xlabel('Class')
plt.ylabel('Number of Samples')
plt.xticks(range(10)) # 设置 x 轴刻度为 0-9
plt.tight_layout()
plt.show()
# 划分客户端数据
xClientsList = []
yClientsList = []
for clientID in range(numOfClients):
start = clientID * clientDataInterval
end = start + clientDataInterval
xClientsList.append(xTrain_tensor[start:end])
yClientsList.append(yTrain_tensor[start:end])
# 可视化客户端数据分布
plot_client_data_distribution(yClientsList, numOfClients)
clientsModelList = []
for clientID in range(numOfClients):
model = DeepModel()
model.load_state_dict(nonFmodel.state_dict()) # 加载服务器的初始权重
clientsModelList.append(model)
def federated_learning(server_model, clientsModelList, xClientsList, yClientsList, numOfIterations, batch_size, criterion):
for iteration in range(numOfIterations):
print(f"Iteration {iteration + 1}/{numOfIterations}")
# 客户端本地训练
client_weights = []
for clientID in range(numOfClients):
print(f"Training client {clientID + 1}/{numOfClients}")
client_model = clientsModelList[clientID]
client_model.train() # 设置模型为训练模式
# 为每个客户端创建独立的优化器
client_optimizer = optim.Adam(client_model.parameters(), lr=0.0001)
# 创建客户端的数据加载器
client_dataset = TensorDataset(xClientsList[clientID], yClientsList[clientID])
client_loader = DataLoader(client_dataset, batch_size=batch_size, shuffle=True)
# 客户端本地训练
for epoch in range(10): # 每个客户端训练 10 个 epoch
running_loss = 0.0
correct = 0
total = 0
for inputs, labels in client_loader:
client_optimizer.zero_grad()
outputs = client_model(inputs)
loss = criterion(outputs, labels)
loss.backward()
client_optimizer.step()
# 计算训练指标
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 打印客户端训练结果
epoch_loss = running_loss / len(client_loader)
epoch_accuracy = correct / total
print(f"Client {clientID + 1}, Epoch {epoch + 1}, Loss: {epoch_loss}, Accuracy: {epoch_accuracy}")
# 保存客户端的权重
client_weights.append(client_model.state_dict())
# 服务器聚合权重(FedAvg)
print("Aggregating client weights...")
avg_weights = {}
for key in client_weights[0].keys():
avg_weights[key] = torch.stack([client_weights[i][key] for i in range(numOfClients)]).mean(0)
# 更新服务器模型
server_model.load_state_dict(avg_weights)
# 更新客户端模型
for clientID in range(numOfClients):
clientsModelList[clientID].load_state_dict(server_model.state_dict())
# 在测试集上评估服务器模型
server_model.eval()
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in test_loader:
outputs = server_model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = correct / total
print(f"Server model accuracy after iteration {iteration + 1}: {accuracy:.4f}")
# 初始化服务器模型
server_model = DeepModel()
server_model.load_state_dict(nonFmodel.state_dict())
# 运行联邦学习
federated_learning(server_model, clientsModelList, xClientsList, yClientsList, numOfIterations, batch_size, criterion, optimizer)Iteration 1/5
Training client 1/5
Client 1, Epoch 1, Loss: 0.25442665502270484, Accuracy: 0.9296666666666666
Client 1, Epoch 2, Loss: 0.24710868604164174, Accuracy: 0.9306666666666666
Client 1, Epoch 3, Loss: 0.2416693331237803, Accuracy: 0.93275
Client 1, Epoch 4, Loss: 0.23599671370330008, Accuracy: 0.9344166666666667
Client 1, Epoch 5, Loss: 0.23226321789812535, Accuracy: 0.9355833333333333
Client 1, Epoch 6, Loss: 0.22663887760582122, Accuracy: 0.9370833333333334
Client 1, Epoch 7, Loss: 0.22229622411442565, Accuracy: 0.9388333333333333
Client 1, Epoch 8, Loss: 0.21833917011130363, Accuracy: 0.9390833333333334
Client 1, Epoch 9, Loss: 0.21452935036034027, Accuracy: 0.9404166666666667
Client 1, Epoch 10, Loss: 0.21081844095061433, Accuracy: 0.9420833333333334
Training client 2/5
Client 2, Epoch 1, Loss: 0.2733165322545361, Accuracy: 0.92425
Client 2, Epoch 2, Loss: 0.2656372262838673, Accuracy: 0.9265
Client 2, Epoch 3, Loss: 0.2590672530709429, Accuracy: 0.9293333333333333
Client 2, Epoch 4, Loss: 0.25394435714375463, Accuracy: 0.9298333333333333
Client 2, Epoch 5, Loss: 0.24873139519006648, Accuracy: 0.9321666666666667
Client 2, Epoch 6, Loss: 0.24368406511209112, Accuracy: 0.9338333333333333
Client 2, Epoch 7, Loss: 0.23849685680358967, Accuracy: 0.9346666666666666
Client 2, Epoch 8, Loss: 0.2351764801572612, Accuracy: 0.9356666666666666
Client 2, Epoch 9, Loss: 0.22973585976882183, Accuracy: 0.9376666666666666
Client 2, Epoch 10, Loss: 0.22543375182183498, Accuracy: 0.9383333333333334
Training client 3/5
Client 3, Epoch 1, Loss: 0.2700467231742879, Accuracy: 0.92275
Client 3, Epoch 2, Loss: 0.26203744765371084, Accuracy: 0.9248333333333333
Client 3, Epoch 3, Loss: 0.25573475979902643, Accuracy: 0.9265
Client 3, Epoch 4, Loss: 0.2504164947870564, Accuracy: 0.9281666666666667
Client 3, Epoch 5, Loss: 0.24430735924459518, Accuracy: 0.931
Client 3, Epoch 6, Loss: 0.23942389398654726, Accuracy: 0.93175
Client 3, Epoch 7, Loss: 0.23514361727110883, Accuracy: 0.9331666666666667
Client 3, Epoch 8, Loss: 0.23075153888698588, Accuracy: 0.9346666666666666
Client 3, Epoch 9, Loss: 0.2257772829145827, Accuracy: 0.9359166666666666
Client 3, Epoch 10, Loss: 0.22238441370427608, Accuracy: 0.9375833333333333
Training client 4/5
Client 4, Epoch 1, Loss: 0.2802324682236352, Accuracy: 0.91925
Client 4, Epoch 2, Loss: 0.2726831494414426, Accuracy: 0.9224166666666667
Client 4, Epoch 3, Loss: 0.26736432238620644, Accuracy: 0.9245833333333333
Client 4, Epoch 4, Loss: 0.2624769541335867, Accuracy: 0.9251666666666667
Client 4, Epoch 5, Loss: 0.2568098053415405, Accuracy: 0.92675
Client 4, Epoch 6, Loss: 0.25263245514732724, Accuracy: 0.928
Client 4, Epoch 7, Loss: 0.24686859892879395, Accuracy: 0.9305
Client 4, Epoch 8, Loss: 0.24287960662486704, Accuracy: 0.93125
Client 4, Epoch 9, Loss: 0.23832704166465618, Accuracy: 0.9328333333333333
Client 4, Epoch 10, Loss: 0.23368976726890245, Accuracy: 0.934
Training client 5/5
Client 5, Epoch 1, Loss: 0.2474874449457894, Accuracy: 0.93275
Client 5, Epoch 2, Loss: 0.2405232391221092, Accuracy: 0.9339166666666666
Client 5, Epoch 3, Loss: 0.235105116118459, Accuracy: 0.93575
Client 5, Epoch 4, Loss: 0.22996057994029623, Accuracy: 0.9363333333333334
Client 5, Epoch 5, Loss: 0.2248192489979432, Accuracy: 0.939
Client 5, Epoch 6, Loss: 0.22043576741472204, Accuracy: 0.9399166666666666
Client 5, Epoch 7, Loss: 0.21599398069876305, Accuracy: 0.9408333333333333
Client 5, Epoch 8, Loss: 0.212206183318445, Accuracy: 0.9423333333333334
Client 5, Epoch 9, Loss: 0.20817280465618093, Accuracy: 0.9435833333333333
Client 5, Epoch 10, Loss: 0.2040201946300395, Accuracy: 0.94375
Aggregating client weights...
Server model accuracy after iteration 1: 0.9333
Iteration 2/5
Training client 1/5
Client 1, Epoch 1, Loss: 0.2245550649835074, Accuracy: 0.937
Client 1, Epoch 2, Loss: 0.21859113547079106, Accuracy: 0.9384166666666667
Client 1, Epoch 3, Loss: 0.21327925455617777, Accuracy: 0.9403333333333334
Client 1, Epoch 4, Loss: 0.20996919222810168, Accuracy: 0.9416666666666667
Client 1, Epoch 5, Loss: 0.20513910768513985, Accuracy: 0.9428333333333333
Client 1, Epoch 6, Loss: 0.200950890343557, Accuracy: 0.9446666666666667
Client 1, Epoch 7, Loss: 0.19713345411768618, Accuracy: 0.9455
Client 1, Epoch 8, Loss: 0.19456246620083742, Accuracy: 0.9464166666666667
Client 1, Epoch 9, Loss: 0.1904639073033282, Accuracy: 0.9464166666666667
Client 1, Epoch 10, Loss: 0.18692744266677727, Accuracy: 0.949
Training client 2/5
Client 2, Epoch 1, Loss: 0.24080706754342673, Accuracy: 0.93275
Client 2, Epoch 2, Loss: 0.23518067392263006, Accuracy: 0.9343333333333333
Client 2, Epoch 3, Loss: 0.229269724299616, Accuracy: 0.937
Client 2, Epoch 4, Loss: 0.22364443861582178, Accuracy: 0.9390833333333334
Client 2, Epoch 5, Loss: 0.21968471776059967, Accuracy: 0.9405833333333333
Client 2, Epoch 6, Loss: 0.21481007690283846, Accuracy: 0.9416666666666667
Client 2, Epoch 7, Loss: 0.2107157273653974, Accuracy: 0.943
Client 2, Epoch 8, Loss: 0.20644662140848788, Accuracy: 0.9444166666666667
Client 2, Epoch 9, Loss: 0.20390446634685738, Accuracy: 0.946
Client 2, Epoch 10, Loss: 0.19998429164765996, Accuracy: 0.9465
Training client 3/5
Client 3, Epoch 1, Loss: 0.2376840992414571, Accuracy: 0.931
Client 3, Epoch 2, Loss: 0.23073043036175536, Accuracy: 0.9335
Client 3, Epoch 3, Loss: 0.2251918563975933, Accuracy: 0.9354166666666667
Client 3, Epoch 4, Loss: 0.22021012024042455, Accuracy: 0.9363333333333334
Client 3, Epoch 5, Loss: 0.216222530983864, Accuracy: 0.93825
Client 3, Epoch 6, Loss: 0.21245101407328817, Accuracy: 0.94025
Client 3, Epoch 7, Loss: 0.20791046107386021, Accuracy: 0.9410833333333334
Client 3, Epoch 8, Loss: 0.2038806156116597, Accuracy: 0.9411666666666667
Client 3, Epoch 9, Loss: 0.1996750899174429, Accuracy: 0.94225
Client 3, Epoch 10, Loss: 0.19675296338948797, Accuracy: 0.94375
Training client 4/5
Client 4, Epoch 1, Loss: 0.2494982845605688, Accuracy: 0.9278333333333333
Client 4, Epoch 2, Loss: 0.24326234833991273, Accuracy: 0.9310833333333334
Client 4, Epoch 3, Loss: 0.23730852664943705, Accuracy: 0.9320833333333334
Client 4, Epoch 4, Loss: 0.23344911202946875, Accuracy: 0.93325
Client 4, Epoch 5, Loss: 0.22863681875961891, Accuracy: 0.9339166666666666
Client 4, Epoch 6, Loss: 0.22455686259459942, Accuracy: 0.936
Client 4, Epoch 7, Loss: 0.22062719137744702, Accuracy: 0.9373333333333334
Client 4, Epoch 8, Loss: 0.21771507274280202, Accuracy: 0.9378333333333333
Client 4, Epoch 9, Loss: 0.21245987919416834, Accuracy: 0.9398333333333333
Client 4, Epoch 10, Loss: 0.21053638400391061, Accuracy: 0.9401666666666667
Training client 5/5
Client 5, Epoch 1, Loss: 0.21783870391230634, Accuracy: 0.9395
Client 5, Epoch 2, Loss: 0.21219479023142063, Accuracy: 0.94175
Client 5, Epoch 3, Loss: 0.2078793477861488, Accuracy: 0.9428333333333333
Client 5, Epoch 4, Loss: 0.2033630972133672, Accuracy: 0.944
Client 5, Epoch 5, Loss: 0.19981738498949625, Accuracy: 0.9454166666666667
Client 5, Epoch 6, Loss: 0.19510637055289873, Accuracy: 0.9460833333333334
Client 5, Epoch 7, Loss: 0.19138122813657243, Accuracy: 0.94775
Client 5, Epoch 8, Loss: 0.18793742850105813, Accuracy: 0.948
Client 5, Epoch 9, Loss: 0.1842302670900492, Accuracy: 0.9501666666666667
Client 5, Epoch 10, Loss: 0.18058367008145185, Accuracy: 0.9510833333333333
Aggregating client weights...
Server model accuracy after iteration 2: 0.9389
Iteration 3/5
Training client 1/5
Client 1, Epoch 1, Loss: 0.20072802946843366, Accuracy: 0.9433333333333334
Client 1, Epoch 2, Loss: 0.19523284259311696, Accuracy: 0.9449166666666666
Client 1, Epoch 3, Loss: 0.1907785619668504, Accuracy: 0.9460833333333334
Client 1, Epoch 4, Loss: 0.18718989110214912, Accuracy: 0.9473333333333334
Client 1, Epoch 5, Loss: 0.1834891686176366, Accuracy: 0.9486666666666667
Client 1, Epoch 6, Loss: 0.17927925534387854, Accuracy: 0.9499166666666666
Client 1, Epoch 7, Loss: 0.17652998454472485, Accuracy: 0.9508333333333333
Client 1, Epoch 8, Loss: 0.1733978860119873, Accuracy: 0.9509166666666666
Client 1, Epoch 9, Loss: 0.1697270419607137, Accuracy: 0.9535833333333333
Client 1, Epoch 10, Loss: 0.1681383055971658, Accuracy: 0.9544166666666667
Training client 2/5
Client 2, Epoch 1, Loss: 0.2165118505028968, Accuracy: 0.9409166666666666
Client 2, Epoch 2, Loss: 0.20965290901825784, Accuracy: 0.9415833333333333
Client 2, Epoch 3, Loss: 0.2045787629532687, Accuracy: 0.9438333333333333
Client 2, Epoch 4, Loss: 0.20037631987732776, Accuracy: 0.94475
Client 2, Epoch 5, Loss: 0.1965011071334494, Accuracy: 0.9459166666666666
Client 2, Epoch 6, Loss: 0.19215396948238003, Accuracy: 0.9475833333333333
Client 2, Epoch 7, Loss: 0.18841116536567185, Accuracy: 0.9483333333333334
Client 2, Epoch 8, Loss: 0.18482514050729731, Accuracy: 0.9500833333333333
Client 2, Epoch 9, Loss: 0.18158305036102204, Accuracy: 0.9501666666666667
Client 2, Epoch 10, Loss: 0.17805842421156295, Accuracy: 0.9510833333333333
Training client 3/5
Client 3, Epoch 1, Loss: 0.21235425552313633, Accuracy: 0.9388333333333333
Client 3, Epoch 2, Loss: 0.2068075367269364, Accuracy: 0.9404166666666667
Client 3, Epoch 3, Loss: 0.20202833548822302, Accuracy: 0.94275
Client 3, Epoch 4, Loss: 0.19758986047607788, Accuracy: 0.9435833333333333
Client 3, Epoch 5, Loss: 0.19325346590832193, Accuracy: 0.9450833333333334
Client 3, Epoch 6, Loss: 0.18987077813437012, Accuracy: 0.9454166666666667
Client 3, Epoch 7, Loss: 0.18642294735826076, Accuracy: 0.9474166666666667
Client 3, Epoch 8, Loss: 0.1833710680577032, Accuracy: 0.9479166666666666
Client 3, Epoch 9, Loss: 0.17899490708604138, Accuracy: 0.9490833333333333
Client 3, Epoch 10, Loss: 0.17610458298487233, Accuracy: 0.9495833333333333
Training client 4/5
Client 4, Epoch 1, Loss: 0.2249332496777494, Accuracy: 0.9351666666666667
Client 4, Epoch 2, Loss: 0.2192696023217224, Accuracy: 0.9378333333333333
Client 4, Epoch 3, Loss: 0.21398302702669134, Accuracy: 0.9386666666666666
Client 4, Epoch 4, Loss: 0.20985325259414125, Accuracy: 0.9398333333333333
Client 4, Epoch 5, Loss: 0.20572651407503068, Accuracy: 0.9406666666666667
Client 4, Epoch 6, Loss: 0.20195866883435148, Accuracy: 0.942
Client 4, Epoch 7, Loss: 0.19861821798568077, Accuracy: 0.9433333333333334
Client 4, Epoch 8, Loss: 0.19404628456748546, Accuracy: 0.9439166666666666
Client 4, Epoch 9, Loss: 0.1925215980315462, Accuracy: 0.9455
Client 4, Epoch 10, Loss: 0.1880613338558915, Accuracy: 0.9474166666666667
Training client 5/5
Client 5, Epoch 1, Loss: 0.19557195037920425, Accuracy: 0.9460833333333334
Client 5, Epoch 2, Loss: 0.19003618328257443, Accuracy: 0.9485
Client 5, Epoch 3, Loss: 0.18576712578416188, Accuracy: 0.9485
Client 5, Epoch 4, Loss: 0.18181784708607704, Accuracy: 0.9504166666666667
Client 5, Epoch 5, Loss: 0.17832311876910797, Accuracy: 0.9510833333333333
Client 5, Epoch 6, Loss: 0.1748609929444625, Accuracy: 0.9520833333333333
Client 5, Epoch 7, Loss: 0.1714997968458115, Accuracy: 0.9528333333333333
Client 5, Epoch 8, Loss: 0.16825064208279264, Accuracy: 0.9541666666666667
Client 5, Epoch 9, Loss: 0.16515613157064357, Accuracy: 0.9548333333333333
Client 5, Epoch 10, Loss: 0.16213883511087995, Accuracy: 0.95525
Aggregating client weights...
Server model accuracy after iteration 3: 0.9424
Iteration 4/5
Training client 1/5
Client 1, Epoch 1, Loss: 0.182429523088355, Accuracy: 0.9478333333333333
Client 1, Epoch 2, Loss: 0.17713796456364242, Accuracy: 0.9498333333333333
Client 1, Epoch 3, Loss: 0.1725572363691444, Accuracy: 0.9515
Client 1, Epoch 4, Loss: 0.1691359833992542, Accuracy: 0.95275
Client 1, Epoch 5, Loss: 0.1652309938353744, Accuracy: 0.9541666666666667
Client 1, Epoch 6, Loss: 0.16237769654377343, Accuracy: 0.955
Client 1, Epoch 7, Loss: 0.15893117510812713, Accuracy: 0.9565833333333333
Client 1, Epoch 8, Loss: 0.15686692723489187, Accuracy: 0.95725
Client 1, Epoch 9, Loss: 0.15326355835621028, Accuracy: 0.9585833333333333
Client 1, Epoch 10, Loss: 0.1505941345574374, Accuracy: 0.9595
Training client 2/5
Client 2, Epoch 1, Loss: 0.1952190003060597, Accuracy: 0.9456666666666667
Client 2, Epoch 2, Loss: 0.18929978812787127, Accuracy: 0.9479166666666666
Client 2, Epoch 3, Loss: 0.18436487199381946, Accuracy: 0.94925
Client 2, Epoch 4, Loss: 0.1802316410268875, Accuracy: 0.9505833333333333
Client 2, Epoch 5, Loss: 0.17599707110685872, Accuracy: 0.9511666666666667
Client 2, Epoch 6, Loss: 0.17309348406071992, Accuracy: 0.9530833333333333
Client 2, Epoch 7, Loss: 0.16917347275909592, Accuracy: 0.9535833333333333
Client 2, Epoch 8, Loss: 0.16606444897169761, Accuracy: 0.9543333333333334
Client 2, Epoch 9, Loss: 0.16287051163058966, Accuracy: 0.9555
Client 2, Epoch 10, Loss: 0.15984033815007895, Accuracy: 0.95725
Training client 3/5
Client 3, Epoch 1, Loss: 0.1918950032323916, Accuracy: 0.9446666666666667
Client 3, Epoch 2, Loss: 0.18673791805718173, Accuracy: 0.9458333333333333
Client 3, Epoch 3, Loss: 0.18174212433873338, Accuracy: 0.9470833333333334
Client 3, Epoch 4, Loss: 0.17863007559579738, Accuracy: 0.94825
Client 3, Epoch 5, Loss: 0.1742238389486645, Accuracy: 0.9494166666666667
Client 3, Epoch 6, Loss: 0.17105837629989107, Accuracy: 0.95125
Client 3, Epoch 7, Loss: 0.16747696741305768, Accuracy: 0.9511666666666667
Client 3, Epoch 8, Loss: 0.16476664832852622, Accuracy: 0.95275
Client 3, Epoch 9, Loss: 0.1621082168706554, Accuracy: 0.9535
Client 3, Epoch 10, Loss: 0.15942862239527575, Accuracy: 0.9545
Training client 4/5
Client 4, Epoch 1, Loss: 0.20403501960112058, Accuracy: 0.9411666666666667
Client 4, Epoch 2, Loss: 0.19888011227421304, Accuracy: 0.9438333333333333
Client 4, Epoch 3, Loss: 0.19454329952280572, Accuracy: 0.944
Client 4, Epoch 4, Loss: 0.19040773374999456, Accuracy: 0.945
Client 4, Epoch 5, Loss: 0.18615327030420303, Accuracy: 0.9461666666666667
Client 4, Epoch 6, Loss: 0.18328818088357754, Accuracy: 0.94825
Client 4, Epoch 7, Loss: 0.17990211914590698, Accuracy: 0.9493333333333334
Client 4, Epoch 8, Loss: 0.17674055487472326, Accuracy: 0.94975
Client 4, Epoch 9, Loss: 0.17322728331101703, Accuracy: 0.9515833333333333
Client 4, Epoch 10, Loss: 0.17024758610715893, Accuracy: 0.9529166666666666
Training client 5/5
Client 5, Epoch 1, Loss: 0.1773396316677966, Accuracy: 0.9505833333333333
Client 5, Epoch 2, Loss: 0.17325909413952142, Accuracy: 0.952
Client 5, Epoch 3, Loss: 0.16790582005806426, Accuracy: 0.953
Client 5, Epoch 4, Loss: 0.16528973227089389, Accuracy: 0.9545
Client 5, Epoch 5, Loss: 0.1612872869925613, Accuracy: 0.955
Client 5, Epoch 6, Loss: 0.15799647805459321, Accuracy: 0.9560833333333333
Client 5, Epoch 7, Loss: 0.15557134692418448, Accuracy: 0.9565833333333333
Client 5, Epoch 8, Loss: 0.15191104774303893, Accuracy: 0.9580833333333333
Client 5, Epoch 9, Loss: 0.15004502205138512, Accuracy: 0.9583333333333334
Client 5, Epoch 10, Loss: 0.14679565506571152, Accuracy: 0.9599166666666666
Aggregating client weights...
Server model accuracy after iteration 4: 0.9472
Iteration 5/5
Training client 1/5
Client 1, Epoch 1, Loss: 0.1652052229904431, Accuracy: 0.9528333333333333
Client 1, Epoch 2, Loss: 0.16066185163056595, Accuracy: 0.9540833333333333
Client 1, Epoch 3, Loss: 0.1566948471392723, Accuracy: 0.9555
Client 1, Epoch 4, Loss: 0.15346477715734472, Accuracy: 0.9573333333333334
Client 1, Epoch 5, Loss: 0.15127332187554937, Accuracy: 0.9585833333333333
Client 1, Epoch 6, Loss: 0.1475321408757504, Accuracy: 0.9589166666666666
Client 1, Epoch 7, Loss: 0.1447430395600485, Accuracy: 0.9606666666666667
Client 1, Epoch 8, Loss: 0.14162614368932677, Accuracy: 0.9623333333333334
Client 1, Epoch 9, Loss: 0.13970148359286658, Accuracy: 0.96325
Client 1, Epoch 10, Loss: 0.13666962443831118, Accuracy: 0.9638333333333333
Training client 2/5
Client 2, Epoch 1, Loss: 0.1775019117135634, Accuracy: 0.95025
Client 2, Epoch 2, Loss: 0.1722347265545358, Accuracy: 0.9523333333333334
Client 2, Epoch 3, Loss: 0.1675563465130139, Accuracy: 0.9541666666666667
Client 2, Epoch 4, Loss: 0.1636965499913439, Accuracy: 0.9555833333333333
Client 2, Epoch 5, Loss: 0.16058857798417833, Accuracy: 0.95625
Client 2, Epoch 6, Loss: 0.1565185741303449, Accuracy: 0.95775
Client 2, Epoch 7, Loss: 0.15363066159981362, Accuracy: 0.9580833333333333
Client 2, Epoch 8, Loss: 0.15052510630042154, Accuracy: 0.95925
Client 2, Epoch 9, Loss: 0.14807047367967824, Accuracy: 0.9601666666666666
Client 2, Epoch 10, Loss: 0.14536668780319234, Accuracy: 0.9609166666666666
Training client 3/5
Client 3, Epoch 1, Loss: 0.17489542960724297, Accuracy: 0.9485833333333333
Client 3, Epoch 2, Loss: 0.169963705095839, Accuracy: 0.95025
Client 3, Epoch 3, Loss: 0.16578015096564877, Accuracy: 0.9523333333333334
Client 3, Epoch 4, Loss: 0.1619015270844102, Accuracy: 0.9533333333333334
Client 3, Epoch 5, Loss: 0.15859658156145126, Accuracy: 0.9540833333333333
Client 3, Epoch 6, Loss: 0.1554605971744403, Accuracy: 0.9546666666666667
Client 3, Epoch 7, Loss: 0.15221528948700808, Accuracy: 0.9549166666666666
Client 3, Epoch 8, Loss: 0.14939277788544905, Accuracy: 0.9568333333333333
Client 3, Epoch 9, Loss: 0.1468444204829792, Accuracy: 0.9566666666666667
Client 3, Epoch 10, Loss: 0.1444110000268259, Accuracy: 0.9573333333333334
Training client 4/5
Client 4, Epoch 1, Loss: 0.18703835338671157, Accuracy: 0.947
Client 4, Epoch 2, Loss: 0.18203374030108146, Accuracy: 0.9478333333333333
Client 4, Epoch 3, Loss: 0.17748043935825217, Accuracy: 0.9488333333333333
Client 4, Epoch 4, Loss: 0.17399417218613497, Accuracy: 0.9513333333333334
Client 4, Epoch 5, Loss: 0.16971268447393434, Accuracy: 0.9515
Client 4, Epoch 6, Loss: 0.1669555729294711, Accuracy: 0.95325
Client 4, Epoch 7, Loss: 0.1633991839047125, Accuracy: 0.95525
Client 4, Epoch 8, Loss: 0.16083770197756747, Accuracy: 0.9554166666666667
Client 4, Epoch 9, Loss: 0.15794647431516268, Accuracy: 0.9563333333333334
Client 4, Epoch 10, Loss: 0.15579183895061624, Accuracy: 0.9580833333333333
Training client 5/5
Client 5, Epoch 1, Loss: 0.16196638664745905, Accuracy: 0.954
Client 5, Epoch 2, Loss: 0.15741348214090822, Accuracy: 0.9563333333333334
Client 5, Epoch 3, Loss: 0.1541800645199862, Accuracy: 0.95725
Client 5, Epoch 4, Loss: 0.14980401459367984, Accuracy: 0.9586666666666667
Client 5, Epoch 5, Loss: 0.1487972610729172, Accuracy: 0.9594166666666667
Client 5, Epoch 6, Loss: 0.14405786252005937, Accuracy: 0.96075
Client 5, Epoch 7, Loss: 0.14075000449380975, Accuracy: 0.9608333333333333
Client 5, Epoch 8, Loss: 0.13871056750971586, Accuracy: 0.9618333333333333
Client 5, Epoch 9, Loss: 0.13590463492623034, Accuracy: 0.9630833333333333
Client 5, Epoch 10, Loss: 0.13408878715114392, Accuracy: 0.9641666666666666
Aggregating client weights...
Server model accuracy after iteration 5: 0.9516作者
arwin.yu.98@gmail.com





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}