
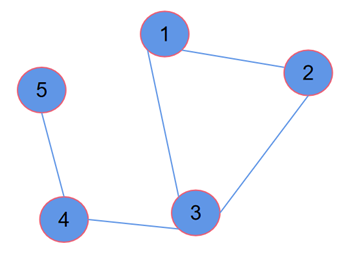
在讲解Graph Isomorphism Network(GIN)之前,有必要先学习了解一下GNN模型的表达能力(Expressive Power),即GNN将不同图数据表示为不同嵌入向量的能力。这里会涉及一个被称为计算图的概念,图神经网络(GNN)的计算图是一种数据结构,它表示图中的节点以及它们之间的连接关系,用于有效地实施图数据上的学习算法。在这种结构中,每个节点聚合其邻居节点的信息,通过多次迭代更新其状态,从而捕捉和利用图的局部连接性质。为了研究GNN模型的表达能力,先来了解一下图数据的局部信息结构,如图1所示。
考虑图1两跳(2-hop)范围内计算图的几个特殊情况:
(1)节点1和节点4,具有相同度数,但到其两跳(2-hop)邻居的信息上度数不同,导致计算图结构不同,因此可以区分这两个节点,如图2所示。
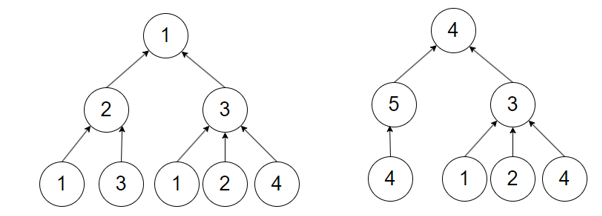
(2)节点1和节点5,因其自身度数不同而具有不同的局部结构信息,如图3所示。
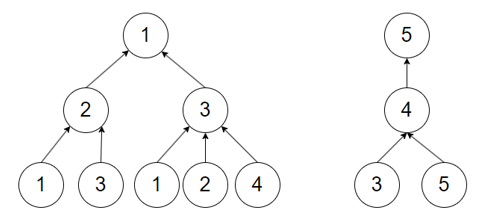
(3)节点1和节点2,具有相同度数,也具有相同的邻居结构,在两跳邻居上,都具有相同的局部结构,如图4所示。

在图4的情况下,假设所有节点的初始化特征向量相同,且聚合节点信息时仅考虑两跳范围内的信息,那么节点1和节点2将被嵌入到同一个表示向量,GNN无法区分这两个节点。相比之下节点3、4、5由于计算图不同,理论上是可能由GNN区分开的。GNN模型应该有将不同的计算图映射到不同的节点向量的能力。想要区分不同的计算图,聚合的方式是关键,聚合函数表达能力越强,GNN表达能力越强。
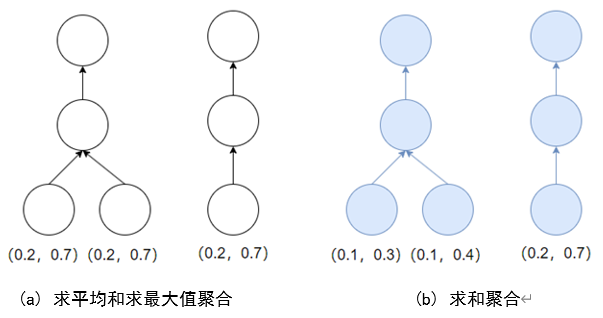
然而,不管是求和、求平均,还是求最大值这些广泛被使用的聚合方式,都不是最佳的选择,如图5所示,两种图数据的计算图是不同的。但针对图5 (a)的初始化节点向量,求平均和求最大值的聚合方式都不能有效的区分出不同的计算图。类似的,对于图5(b)的初始化节点向量,求和的聚合方式也不能有效区分这两种计算图。这是因为图通过聚合节点向量后却得到了相同的新的节点向量。
从数学的角度上来讲,希望GNN的聚合函数是一种单射函数(Injective Function),即可把不同的元素映射成不同输出。换句话说,希望GNN的聚合函数能把不同的计算图映射生成不同的节点向量。显然,求和函数、求平均函数、求最大值函数都不是单射函数。根据Xu et al. 在论文Graph Wavelet Neural Network中得到定理可知:任一单射函数都可以表示为:
\(\phi(\sum_{x\in S}f(x))\)
其中,\(\phi\)和\(\mathrm{f}\)表示某种非线性函数,\(\mathrm{S}\)是输入信息\(\mathrm{x}\)的集合。问题的关键是这个非线性函数\(\phi\)和\(\mathrm{f}\)该怎么求解?此时深度学习的魅力来了,对于神经网络模型而言,理论上它可以拟合任意任何连续函数,所以既然不清楚要求解的函数\(\phi\)和\(\mathrm{f}\)是什么,可以直接通过神经网络让它自己学,通过定义损失,使用梯度下降更新网络的参数就好。此时,这个单射函数的形式变成了:
\(\mathrm{MLP}_\phi(\sum_{xinS}\mathrm{MLP}_f(x))\)
使用上式的函数作为聚合函数的图神经网络被称为Graph Isomorphism Network(GIN)。在GIN的实际实现中,\(\phi\)和\(\mathrm{f}\)两个非线性函数是通过一个MLP实现的,因为MLP本身可以表示函数的组合。在第一次迭代中,如果输入特征是独热编码形式,在求和之前不需要MLP,因为独热编码求和本身是单射的,最后,使用一个可学习参数\(\epsilon\)(也可以是一个固定的缩放因子)来决定聚合节点自身向量时的比重。完整的GIN层公式如下:
\(h_{\nu}^{(k)}=\mathrm{MLP}^{(k)}((1+\epsilon^{(k)})\cdot h_{\nu}^{(k-1)}+\sum_{u\in N_{(v)}}h_{u}^{(k-1)})\)
在上式中,每个节点\(\nu\)的新表示\(h_{v}^{(k)}\)在第\(\mathrm{k}\)轮迭代中是通过以下步骤计算得出的:首先进行邻居信息的聚合,对节点\(\nu\)的所有邻居节点\(\mathrm{u}\)的当前表示\(h_{u}^{(k-1)}\)进行求和聚合,这表示为\(\sum_{u\in N(\nu)}h_{u}^{(k-1)}\),其中\(N(\nu)\)是节点\(\nu\)的邻居节点集合。然后加上节点\(\nu\)自身在上一轮迭代中的信息\(h_{v}^{(k-1)}\),并将其乘以一个权重\(1+\epsilon^{(k)}\)。这里的\(\epsilon^{(k)}\)是在第\(\mathrm{k}\)轮迭代中一个可学习的参数,它允许模型调整自身节点信息与邻居信息的相对重要性。最后,将上述两部分的和作为输入传递给一个多层感知器\(MLP^{(k)}\),这是一个可学习的非线性函数,用来生成节点\(\nu\)的新表示 。如果输入特征不是独热编码形式,存在重复的特征向量表示,GIN的形式可以写成:
\(h_{\nu}^{(k)}=\mathrm{MLP}^{(k)}((1+\epsilon^{(k)})\cdot h_{\nu}^{(k-1)}+\sum_{u\in N_{(\nu)}}\mathrm{MLP}(h_{u}^{(k-1)}))\)
从上式可以看出,如果输入特征可能存在重复的特征向量表示,那么只需要在聚合完节点\(\nu\)的邻居信息之后,在与节点\(\nu\)自身信息求和之前,对每个邻居节点的表示先进行一个MLP变换即可。
作者
arwin.yu.98@gmail.com
相关文章

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}