
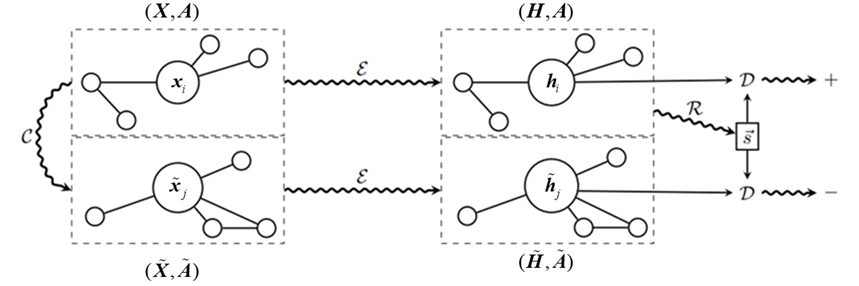
Deep Graph Infomax(DGI)是一种基于图的无监督学习方法,其主要目标是学习图中节点的有效表示,即图数据的Embedding。DGI由Petar Veličković等人在2019年的论文中提出,这种方法通过最大化局部图结构(节点)和全局图结构(整个图)之间的互信息来学习节点表示,DGI整体的模型计算流程如图1所示。
从图1可以看出,第一步,算法需要一个正常图\((X,A)\)的扰动版本\((\widetilde{X},\widetilde{A})\),扰动版本通过负样本操作\(\mathrm{C}\)来实现。负样本操作可以通过多种方式实现,本质是一个函数。这个函数会接受图的节点特征\(\mathbf{X}\)和邻接矩阵\(\mathrm{A}\)作为输入,然后对原图结构进行变换,比如随机打乱节点的特征,或者在邻接矩阵中随机重排列边。目的是创建一个与原始图在统计特性上有显著区别的样本,这个负样本在后续步骤中用来帮助判别器学习如何区分图的正样本表示和与图不相关的表示。
第二步使用编码器函数\(\varepsilon(X,A)\)处理原始图的每个节点,从而得到每个节点的向量表示。这里的编码器\(\mathcal{E}\)通常是一个图神经网络(如GCN),它能够考虑节点的特征以及节点之间的连接(通过邻接矩阵\(\mathrm{A}\))来产生一个低维而信息丰富的特征向量\(\boldsymbol{h}_i\)。编码器的目的是捕获节点的局部图结构和节点特征,生成的集合\((H,A)=h_1,h_2,\cdots,h_n\)包含了输入图所有节点的这些表示。同理,在上一步中采样的负样本也需要经过编码器\(\boldsymbol{\varepsilon}\)的处理得到对应的\((\widetilde{H},\widetilde{A})\)。
第三步,算法需要从整个输入图的节点表示中提取一个单一的图级别的表示\(\mathbf{s}\)。这通常通过一个汇总函数\(R\left(\boldsymbol{H},A\right)\)完成,它可以是简单的平均节点表示,或者一个更复杂的结构,如基于注意力的汇总方法。这个图级别的表示\(\mathbf{s}\)应该捕获整个图的全局性质,它将在损失函数中用于比较正样本和负样本的节点表示。
最后一步是模型学习的关键。在这一步中,通过梯度下降来更新编码器\(\boldsymbol{\varepsilon}\)、汇总函数\(\text{R}\)以及判别器\(\text{D}\)的参数。判别器也是一个图神经网络,其任务是根据节点表示(\(h_{i}\)或\(h_{j}\))和图表示来判断节点是否属于该图。损失函数\(\text{L}\)在正样本的情况下鼓励判别器给出高的得分,而在负样本的情况下给出低的得分。通过最大化损失函数中定义的互信息量,模型能够训练出区分原始图节点和负样本节点表示的能力。
这个训练过程的目标是调整模型的参数,使得从正样本图中提取的节点表示与图的全局表示尽可能接近,而从负样本图中提取的节点表示则与图的全局表示尽可能远。即最大化节点表示和对应图级表示的互信息。这种方法认为,如果节点表示能够捕捉到与整个图表示高度相关的信息,那么这些节点表示就是有用的。这便完成了DGI的主要目标:学习图中节点的有效表示,即图数据的Embedding。
随机游走算法的目的也是学习图中节点的有效表示,且与DGI同属无监督学习方法,但在方法和理念上存在显著差异。随机游走侧重于通过模拟从一个节点开始的随机路径来捕捉图中节点的局部连接模式,以探索和利用图的局部结构特性。这种方法通过观察节点间的“游走”行为,直接反映了节点的邻近关系。相比之下,DGI采用基于互信息最大化的策略,通过学习节点表示和全局图表示之间的互信息来提取特征,不仅考虑了局部结构,还尝试捕捉整个图的全局上下文。DGI通常使用图神经网络如图卷积网络(GCN)作为编码器,更侧重于深度学习技术。总体而言,随机游走方法更加直观和简单,适用于图的局部特征学习;而DGI则是一种更复杂的深度学习方法,能够综合局部与全局信息,适合于需要深层特征提取的复杂图形任务。
此外,DGI(Deep Graph Infomax)和GAN(生成对抗网络)虽然都涉及到一个判别器组件,但它们的目标和训练过程有本质的不同。GAN由两个模型组成:生成器(Generator)和判别器(Discriminator)。生成器的目标是创建尽可能接近真实数据的新数据实例,而判别器则试图区分真实数据和生成器创建的伪造数据。这两个模型在训练过程中相互竞争,生成器不断改进其生成的数据质量以试图“欺骗”判别器,而判别器也不断改进其识别真伪数据的能力。这种对抗性的训练过程导致了生成器学会生成高质量的数据。DGI的目的不是生成新的数据,而是从图数据中学习有用的节点表示。在DGI中,判别器的作用不是与编码器对抗,而是帮助编码器学习生成高质量的节点嵌入。DGI使用一个非对抗的信息最大化原则,这个原则指导编码器生成的节点表示要包含足够的信息以便判别器可以准确区分节点是来自原始图还是扰动后的图(即正样本或负样本)。换句话说,判别器用于指导编码器捕捉到有意义的特征——使得这些特征对于区分不同图结构是有信息的。DGI的目标是通过这种方式提升表示的质量,而不是在编码器和判别器之间创建对抗。
作者
arwin.yu.98@gmail.com
相关文章

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}