
基本信息
- 📰标题: Coordinate Attention for Efficient Mobile Network Design
- 🖋️作者: Xiangyu Zhang
- 🏛️机构: Megvii Technology (旷视科技)
- 🔔关键词: Coordinate Attention, Mobile Networks, Efficient Design
摘要概述
| 项目 | 内容 |
|---|---|
| 📖研究背景 | 移动网络设计需要轻量且高效的注意力机制,传统方法(如Squeeze-and-Excitation)难以同时捕获空间和通道关系。 |
| 🎯研究目的 | 提出一种新型注意力机制(Coordinate Attention),通过分解二维全局池化为两个一维操作,高效建模通道关系和长程空间依赖。 |
| ✍️研究方法 | 1. 将空间坐标信息嵌入通道注意力;2. 使用水平与垂直方向的坐标注意力(Coordinate Attention Blocks);3. 在MobileNetV2等轻量网络上验证。 |
| 🕊️研究对象 | 轻量级CNN架构(如MobileNetV2、ShuffleNet)及其在ImageNet分类、目标检测等任务的表现。 |
| 🔍研究结论 | 在参数量相近的情况下,相比SE模块,坐标注意力提升MobileNetV2在ImageNet上的Top-1准确率1.2%,且计算开销仅增加0.03ms。 |
| ⭐创新点 | 1. 首次将坐标信息显式编码到注意力机制;2. 通过分解池化操作实现空间-通道联合建模;3. 适用于移动设备的即插即用模块。 |
背景
-
研究背景:
注意力机制通过指示模型“关注什么”和“关注哪里”,已成为提升深度神经网络性能的关键技术。然而,其在计算资源受限的移动网络(Mobile Networks)中的应用显著落后于大型网络,主要因现有注意力机制的计算开销难以满足移动设备的轻量化需求。 -
过去方案:
-
Squeeze-and-Excitation (SE):通过2D全局池化计算通道注意力,计算成本低但忽略位置信息,难以捕捉视觉任务中的对象结构。
-
BAM/CBAM:通过降维和卷积引入空间注意力,但卷积仅能建模局部关系,无法捕获长程依赖(long-range dependencies)。
核心问题:现有方法无法平衡计算效率与空间-通道联合建模的需求。
-
-
研究动机:
提出Coordinate Attention机制,通过分解2D池化为两个1D方向编码(水平/垂直),将位置信息嵌入通道注意力,实现以下目标:
(1)同时建模跨通道交互与长程空间依赖;
(2)保持轻量化特性,适配MobileNetV2等移动网络架构;
(3)提升下游密集预测任务(如语义分割)的性能。
方法
-
理论背景:
本研究基于注意力机制在轻量化网络中的两大局限:
1) 传统通道注意力(如SE模块)因全局池化丢失空间位置信息;
2) 空间注意力(如CBAM)的卷积操作难以建模长程依赖。受人类视觉系统“坐标-通道”协同感知机制启发,提出位置信息与通道注意力耦合的理论框架。 -
技术路线:
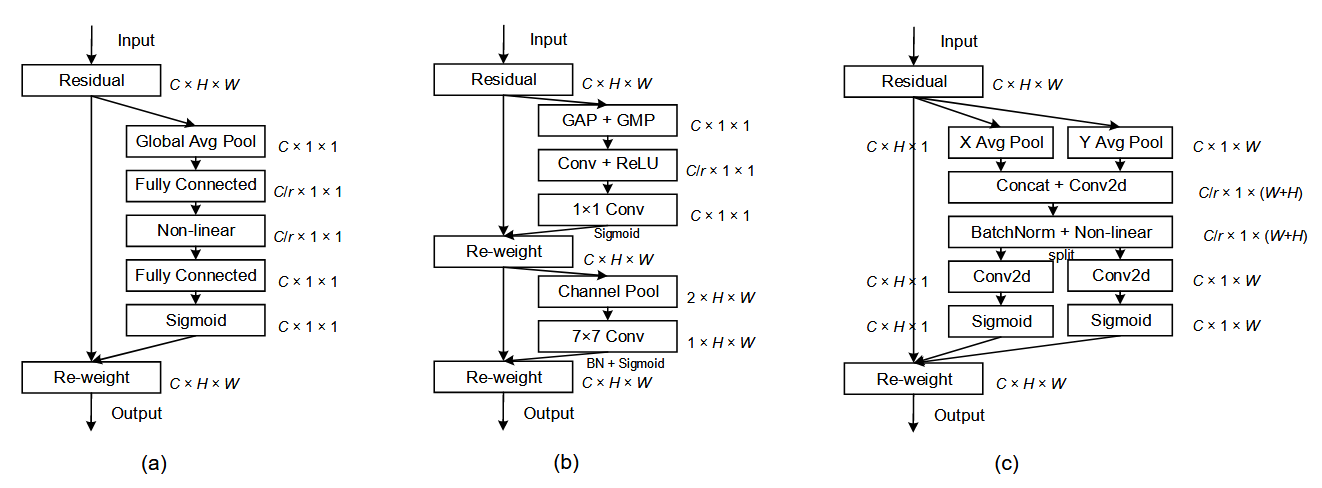
下面,对比SENet和CBAM来理解CANet,如下图所示:
-
(a) SE通道注意力
流程:通过全局平均池化(GAP)压缩空间信息→两个全连接层(含降维)→Sigmoid生成通道权重→与输入特征相乘
缺陷:2D全局池化导致空间位置信息丢失,仅建模通道关系. -
(b) CBAM双路径设计:
通道注意力:类似SE但增加GMP分支
空间注意力:通过通道压缩+大核卷积(7×7)生成空间权重
局限:卷积只能捕获局部关系(论文3.1节指出其难以建模长程依赖) -
(c) 坐标注意力(本文提出) 创新点:
坐标信息嵌入:将2D池化解耦为水平(X Avg Pool)和垂直(Y Avg Pool)两个1D池化,分别保留方向敏感特征。
联合编码:拼接双方向特征→共享1×1卷积→分解为方向感知注意力图(强制两个分支分别学习水平/垂直方向的注意力模式,避免特征混淆)→1x1卷积→Sigmoid生成通道权重→与对应输入特征相乘。
优势: 同时捕获长程依赖(单方向)和精确保留位置信息(另一方向)。
具体来说:传统卷积(如CBAM的7×7卷积)受限于局部感受野,难以建模图像中远距离像素的关联(例如天空与地面的颜色渐变关系)。CANet中对水平方向(X轴)进行1D全局池化(X Avg Pool),将特征压缩为 C×1×W 的向量。此时,每个位置的权重计算会考虑该行所有像素的信息(即水平长程依赖)。类似地,对垂直方向(Y轴)的1D池化(Y Avg Pool)捕获 C×H×1 的垂直长程依赖。单方向的1D池化天然具有全局视野(类似Non-local网络的全局关系建模),但计算成本更低(仅需O(H)或O(W)复杂度)。另一方面,SE模块的2D全局池化会完全丢失空间位置信息(例如无法区分目标在图像左上角还是右下角)。CANet通过解耦为双1D池化,在计算水平方向注意力时,垂直方向的坐标信息(Y轴位置)被保留(反之亦然)。
结论
-
提出适用于mobile networks的轻量级Coordinate Attention机制,解决了传统channel attention方法(如SE模块)无法同时建模通道关系与空间位置信息的核心问题,显著提升了轻量模型在视觉任务中的性能表现。
-
优点:
1) 通过分解2D池化为双1D操作,在保持计算效率的同时捕获long-range dependencies;
2) 即插即用特性适配多种轻量架构(如MobileNetV2)。 -
局限:未讨论硬件部署时的实际延迟与能耗表现。
-
主要结论:
- Coordinate Attention通过坐标嵌入同时建模inter-channel relationships与精确位置信息;
- 在ImageNet分类、object detection和semantic segmentation任务中均验证有效性;
- 计算开销仅轻微增加(如MobileNetV2推理延迟+0.03ms),符合移动端轻量化需求。
Pytorch code
import torch
import torch.nn as nn
import torch.nn.functional as F
class CoordinateAttention(nn.Module):
def __init__(self, in_channels, reduction_ratio=32):
"""
Coordinate Attention 模块 (CVPR 2021)
Args:
in_channels: 输入特征图的通道数
reduction_ratio: 中间层通道压缩比例
"""
super(CoordinateAttention, self).__init__()
self.reduction_ratio = reduction_ratio
mid_channels = max(8, in_channels // reduction_ratio) # 确保中间通道数≥8
# 水平(X轴)和垂直(Y轴)方向的池化
self.x_avg_pool = nn.AdaptiveAvgPool2d((None, 1)) # [b,c,h,w] -> [b,c,h,1]
self.y_avg_pool = nn.AdaptiveAvgPool2d((1, None)) # [b,c,h,w] -> [b,c,1,w]
# 共享权重的两层MLP(与SE Block不同,这里不降维到C/r)
self.conv1 = nn.Conv2d(in_channels, mid_channels, kernel_size=1)
self.conv2 = nn.Conv2d(mid_channels, in_channels, kernel_size=1)
# 激活函数
self.relu = nn.ReLU(inplace=True)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
b, c, h, w = x.shape
# 1. 坐标信息嵌入(Coordinate Information Embedding)
# X轴方向池化 [b,c,h,w] -> [b,c,h,1]
x_avg = self.x_avg_pool(x)
# Y轴方向池化 [b,c,h,w] -> [b,c,1,w]
y_avg = self.y_avg_pool(x)
# 2. 调整 y_avg 形状,使其能与 x_avg 在 dim=2 拼接
y_avg = y_avg.permute(0, 1, 3, 2) # [b,c,1,w] -> [b,c,w,1]
# 3. 拼接两个方向的池化结果 [b,c,h,1] + [b,c,w,1] -> [b,c,h+w,1]
concat = torch.cat([x_avg, y_avg], dim=2)
# 4. 共享MLP处理
out = self.relu(self.conv1(concat))
out = self.sigmoid(self.conv2(out))
# 5. 分离X/Y轴注意力权重
x_att, y_att = torch.split(out, [h, w], dim=2) # 拆分为[b,c,h,1]和[b,c,w,1]
y_att = y_att.permute(0, 1, 3, 2) # [b,c,w,1] -> [b,c,1,w](恢复原始形状)
# 6. 特征图重标定(Feature Recalibration)
return x * x_att.expand_as(x) * y_att.expand_as(x)
# ------------------- 用法示例 -------------------
if __name__ == "__main__":
# 1. 初始化模块(输入通道=256)
ca = CoordinateAttention(in_channels=256)
# 2. 模拟输入数据(batch_size=4, 通道=256, 尺寸=56x56)
dummy_input = torch.randn(4, 256, 56, 56)
# 3. 前向传播
output = ca(dummy_input)
print(f"输入形状: {dummy_input.shape}")
print(f"输出形状: {output.shape}") # 应与输入形状一致作者
arwin.yu.98@gmail.com
相关文章




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}