
Learning Methods of Deep Learning
create by Deepfinder
 Agenda
Agenda
- 师徒相授:有监督学习(Supervised Learning)
- 见微知著:无监督学习(Un-supervised Learning)
- 无师自通:自监督学习(Self-supervised Learning)
- 以点带面:半监督学习(Semi-supervised learning)
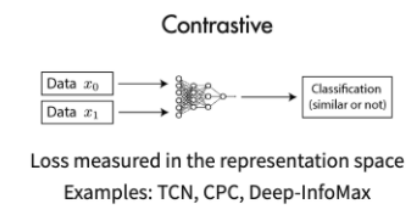
- 明辨是非:对比学习(Contrastive Learning)
- 举一反三:迁移学习(Transfer Learning)
- 针锋相对:对抗学习(Adversarial Learning)
- 众志成城:集成学习(Ensemble Learning)
- 殊途同归:联邦学习(Federated Learning)
- 百折不挠:强化学习(Reinforcement Learning)
- 求知若渴:主动学习(Active Learning)
- 万法归宗:元学习(Meta-Learning)
Tutorial 05 - 明辨是非:对比学习(Contrastive Learning)
 对比学习
对比学习
- 对比学习是一种制定 为深度学习模型寻找相似和不相似事物(基本上就是给定标签时分类所做的事情) 的任务的方法。
- 对比方法,顾名思义,通过对比正面和负面示例来学习表示。
- 使用这种方法,可以训练机器学习模型对相似和不相似的图像进行分类。
更正式地说,对于任何数据点 $x$,对比方法旨在学习编码器 $f$,使得:
- $x^+$ 是与 $x$ 相似的数据点,称为 正 样本。
- $x^−$ 是与 $x$ 不相似的数据点,称为 负 样本。
- 得分函数 是衡量两个特征之间相似度的指标: $$score(f(x), f(x^+)) >> score(f(x), f(x^-))$$


-
实现得分范式的最常见损失函数是 InfoNCE 损失,它看起来类似于 softmax。

- 分母项由一个正样本和 $N−1$ 个负样本组成。
 但是,如果我们处于自监督环境中,我们如何获得负样本?
但是,如果我们处于自监督环境中,我们如何获得负样本?
 对比预测编码 ( Contrastive Predictive Coding)
对比预测编码 ( Contrastive Predictive Coding)
- 对比预测编码 (CPC) 通过使用强大的自回归模型在学习到的 潜在空间 中预测未来,学习自监督表示。
- 该模型使用概率对比损失,诱导潜在空间捕获对预测未来样本最有用的信息。
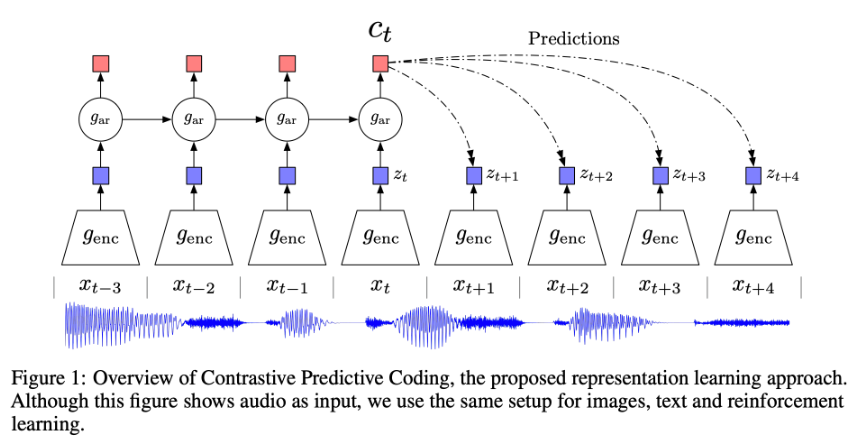
- 首先,非线性编码器 $g_{enc}$ 将输入的观测序列 $x_t$ 映射到潜在表示序列 $z_t = g_{enc}(x_t)$,可能具有较低的时间分辨率($g_{enc}$ 的架构通常取决于数据类型,例如用于图像的 CNN)。
- 接下来,自回归模型 $g_{ar}$ 总结潜在空间中的所有 $z \leq t$ 并产生上下文潜在表示 $c_t=g_{ar}(z \leq t)$。
- 相似度 $f$ 被建模,它保留了 $x_{t+k}$ 和 $c_t$ 之间的 相互信息,如下所示: $$ f_k(x_{t+k}, c_t) = \exp(z_{t+k}^T W_k c_t) \propto \frac{p(x_{t+k} | c_t)}{p(x_{t+k})} $$
你可以这么理解:在 CPC(Contrastive Predictive Coding)的情境下,
- 编码器 ( $g_{\mathrm{enc}}$ ) 用于把每个时刻的文本 (或其他模态) 输入映射到一个潜在向量表示 $z_t$ 。
- 自回归模型( $g_{\mathrm{ar}}$ )则负责在时间序列维度上"聚合语义",输出一个"上下文"向量 $c_t$ ,表示模型对 "截止到当前时刻所有信息"的理解。
- 在训练时:
- 取一个时间戳 $t$ ,用上下文 $c_t$ 和真正的未来 (下一时刻) 对应的潜在向量 $z_{t+1}$ 作为正例,
- 并将上下文 $c_t$ 与其他时刻(或者其他无关样本)的潜在向量 $z_{\mathrm{neg}}$ 作为负例。
- 通过 InfoNCE 这类对比损失,让模型尽可能区分出正例和负例,从而拉近真正相关的时刻表示、推远不相关的时刻表示。
这样做的直观含义是:
- "如果给定了过去时刻的语义,能不能正确辨认出真正的下一个时刻?"
- 这在自监督的框架下,会促使模型学到具有预测能力、对"上下文一未来"关系敏感的表示。
所以,"编码器 + 自回归 + InfoNCE 对比损失" 就构成了 CPC 的基本思路。文本上可以这样简单记忆:
先"编码"每个时刻,
再用"自回归"汇总过去,
利用"对比损失"来拉近正确的下一个时刻表示 推远不正确的下一个时刻表示。
bert中的上下文预测任务算对比学习吗?
 视觉表征对比学习简单框架 (Simple Framework for Contrastive Learning of Visual Representations)
视觉表征对比学习简单框架 (Simple Framework for Contrastive Learning of Visual Representations)
- 视觉表征对比学习简单框架 (SimCLR) 是一个用于对比学习 视觉 表征的框架。
- 它通过潜在空间中的对比损失,最大化同一数据示例的不同增强视图之间的一致性来学习表征。
正例 (Positive Pair) 是如何定义的?
-
随机数据增强:对同一张原始图像 $x$ 进行两次随机增强,得到两张增强后的图像:$\tilde{x}_i \quad \text { 和 } \quad \tilde{x}_j$。
它们来自同一张图,只是由于裁剪、颜色抖动、模糊等增强调整而得到的两个视图。 -
称为"正对": 这两张视图在语义上是相同的,都是来自同一个原图,因此 $\left(\tilde{x}_i, \tilde{x}_j\right)$ 被看作一对 "正例 (positive pair)"。
-
小批量内的所有正例对:在训练时,会抽取一个包含 $N$ 个原图的小批量,为其中每个原图都生成两份增强视图。所以小批量最终拥有 $2 N$ 个"图像视图"。对于每个原图 $x$ ,它的两份视图就构成了一个正例对。
负例 (Negative Examples) 又是怎么来的?
- 显式"负例" vs. 隐式"负例"
传统对比学习方法常常需要显式地找一些不同的图像作为"负例",比如从别的类别中抽取样本来构建负例。SimCLR 则提出一个非常简单且有效的做法:不用显式地挑选负例,只要把小批量里的其他所有视图,统统视为本视图的负例即可。
- 具体定义
假设小批量里有 $N$ 个原图,一共得到 $2 N$ 个增强视图(2个视图/图 $\times N$ 张原图)。如果我们关注其中某个正对 $\left(\tilde{x}_i, \tilde{x}_j\right)$ ,那么对于 $\tilde{x}_i$ 来说:
- 它的"正例"就是 $\tilde{x}_j$ (因为二者都是来自同一个原图)。
- 小批量中剩下的 $2 N-2$ 个视图(包括别的图片的增强视图,以及 $\tilde{x}_i$ 自己那一对的另一个成员已经被算作正例,所以要排除)都被视为负例。
- 好处
这样做显著降低了管理正负例的复杂度:不必额外维护一个大型的负例池,也无需在线挖掘负例,只要在一个 mini-batch 内求对比损失,就能把其它视图当作负例了。

对于小批量中的任意一个增强视图,在计算它的损失时,它“应该”只和它那对正例视图相似,而和任何其他视图都不相似,这就自然刻画出了正例和负例的区分。通过在小批量维度上做对比损失,SimCLR 就能在没有标签的条件下,学到很有判别力的视觉表示。
 CLIP - Contrastive Language–Image Pre-training
CLIP - Contrastive Language–Image Pre-training
- CLIP 是一种神经网络,可从自然语言监督中高效学习视觉概念。
- CLIP 可以以 零样本 方式应用于任何视觉分类基准,只需提供要识别的视觉类别的名称即可。
- 训练数据:在互联网上找到的与图像配对的文本。
- 自我监督任务:给定一张图像,预测在一组随机采样的文本片段中,哪一个与数据集中的图像实际配对,这类似于我们之前介绍的匹配范例。
- 损失函数:配对之间的余弦相似度等缩放交叉熵损失。
- 在推理时,我们可以通过检查每张图片的 CLIP 模型预测文本描述“一张狗的照片”或“一张猫的照片”是否更有可能与其配对,对狗和猫的照片进行分类。
- 官方存储库 (PyTorch)
- Colab 示例 - 与 CLIP 和零样本分类的交互
- HuggingFace 演示:
- CLIP-ViT-Large
- CLIPScore
# clip usage example
import torch
import clip
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
image = preprocess(Image.open("CLIP.png")).unsqueeze(0).to(device)
text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs) # prints: [[0.9927937 0.00421068 0.00299572]] Credits
Credits
- Icons made by Becris from www.flaticon.com
- Icons from Icons8.com - https://icons8.com
- Datasets from Kaggle - https://www.kaggle.com/
- Jason Brownlee - Why Initialize a Neural Network with Random Weights?
- OpenAI - Deep Double Descent
- Tal Daniel
作者
arwin.yu.98@gmail.com





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}