
1. 摘要
视觉与语言预训练(VLP)在跨模态任务(如图文检索、视觉问答等)上取得了显著进展。然而,现有方法大多依赖计算量大的图像特征提取模块(如基于目标检测的区域特征或CNN提取的全局特征),这不仅降低了效率,还限制了模型的表达能力。本文提出 ViLT(Vision-and-Language Transformer),一种极简的VLP模型,其核心创新是完全摒弃传统卷积或区域监督方法,改用类似文本处理的“无卷积”方式直接建模视觉输入。实验证明,ViLT 比现有方法快数十倍,同时在下游任务上保持甚至超越SOTA性能。
论文地址:http://proceedings.mlr.press/v139/kim21k/kim21k.pdf
2. 介绍
2.1 背景
作者总结了视觉-语言模型(Vision-and-Language Models)的 四种计算范式分类,通过比较 视觉嵌入(VE)、文本嵌入(TE)和模态交互(MI) 三个模块的 相对计算量(矩形高度表示),揭示了不同模型的设计差异。以下是详细解析:
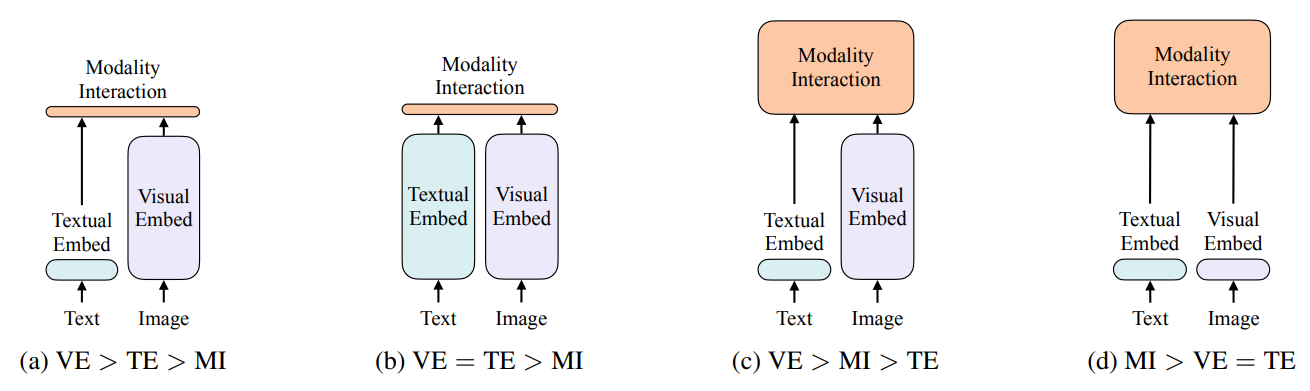
- Visual Embedder (VE):图像特征提取(如CNN、区域检测器、线性投影)。
- Textual Embedder (TE):文本特征提取(如BERT、Word2Vec)。
- Modality Interaction (MI):跨模态交互(如Transformer注意力机制)。
(a) VE > TE > MI
特点:视觉嵌入计算量最大,文本次之,模态交互最小。需运行Faster R-CNN提取区域特征(VE耗时高),文本用轻量BERT(TE中等),交互较简单。
代表模型:早期基于区域检测的模型(如UNITER、VILBERT)。
(b) VE = TE > MI
特点:视觉和文本嵌入计算量相当,均大于模态交互。ResNet(VE)和BERT(TE)计算量平衡,交互仍非主导。
代表模型:基于CNN网格特征的模型(如Pixel-BERT)。
(c) VE > MI > TE
特点:模态交互计算量显著增加,视觉/文本嵌入比重降低。
代表模型: 部分交互密集型模型(如OSCAR)。
(d) MI > VE = TE
特点:视觉嵌入极简(线性投影,VE耗时低),文本用标准BERT(TE),模态交互(MI)成为主要计算部分。
代表模型: ViLT
视觉-语言模型的范式进化经历了从复杂视觉特征提取到轻量嵌入+深度交互的转变:早期模型(如UNITER)依赖重型区域检测器(VE≫MI),计算成本高;过渡期(如Pixel-BERT)改用CNN平衡视觉与文本嵌入(VE≈TE>MI),但仍受限于卷积计算;突破性工作ViLT彻底摒弃CNN,通过线性投影实现极简视觉嵌入(VE≈0.4ms),将计算重心转移到模态交互(MI主导),实现15ms级高效推理;现代模型(如BLIP、CoCa)进一步强化交互能力,采用统一Transformer架构,推动多模态任务端到端联合优化。核心趋势是视觉模块持续轻量化,跨模态交互深度增强,形成高效通用的多模态学习范式。
2.2 动机
下图展示了ViLT(Vision-and-Language Transformer)论文中提出的视觉嵌入方法,并将其与其他主流方法进行了对比。ViLT是一种无需卷积或区域监督的视觉-语言Transformer模型。
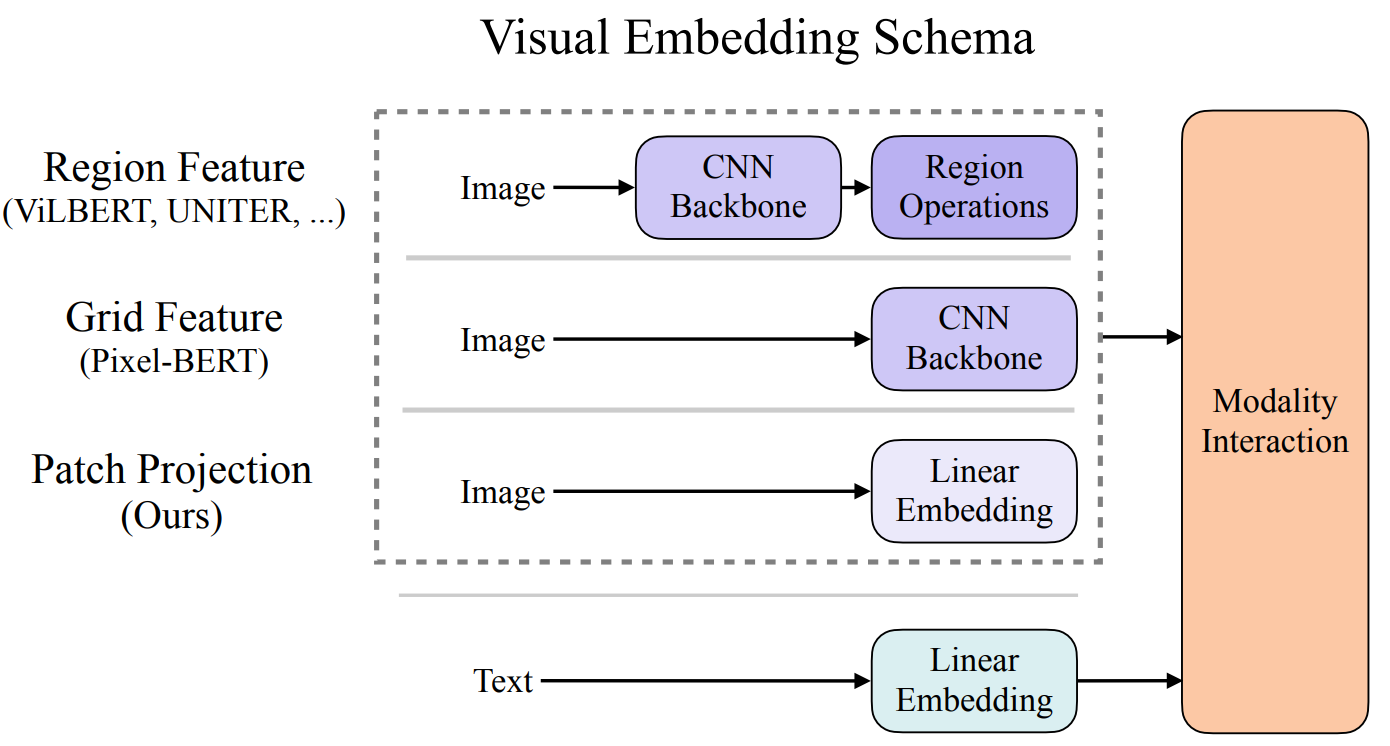
- Region Feature(区域特征)
- 代表模型:VILBERT、UNITER等。
- 特点:
- 使用预训练的物体检测器(如Faster R-CNN)提取图像的区域特征(如边界框内的特征)。
- 依赖额外的区域标注或检测任务,计算成本高。
- Grid Feature(网格特征)
- 代表模型:Pixel-BERT。
- 特点:
- 使用CNN骨干网络(如ResNet)提取图像的网格特征(均匀划分的特征图)。
- 无需区域标注,即边界框bounding box,但仍需预训练的CNN,计算量较大。
- Patch Projection(块投影)
- 代表模型:ViLT(Ours)。
- 特点:
- 直接将图像分割为块(Patch),通过线性投影生成嵌入向量。
- 无需CNN或区域检测器,完全基于Transformer,轻量且高效。
Embedding Projection的具体操作:
- Image:
- Patch Projection:
- 将图像分割为固定大小的块(如16x16像素)。
- 每个块通过线性投影(全连接层,一般被卷积替代)转换为嵌入向量(类似ViT的处理方式)。
- Text:
- 文本通过独立的线性嵌入层转换为向量。
- Modality Interaction:
- 图像和文本的嵌入向量直接输入Transformer,进行跨模态交互。

上图展示了 ViLT(Vision-and-Language Transformer)模型与其他主流多模态模型(UNITER、Pixel-BERT)在 推理速度 和 任务性能 上的对比,突出了ViLT的高效性。以下是关键结论:
- ViLT的推理速度 比UNITER快60倍(15 ms vs 900 ms),比Pixel-BERT快6倍(15 ms vs 90 ms)。
- 速度优势主要来自:
- 去除了CNN骨干网络(ResNet的45-75 ms耗时)。
- 无需区域检测(省去RPNs、RoI Align等80 ms操作)。
总的来说,UNITER:依赖区域特征,性能高但计算成本极大(适合对延迟不敏感的场景)。Pixel-BERT:用CNN网格特征简化流程,但速度仍受限于ResNet。ViLT:开创了“无卷积、无区域”的多模态范式,为后续模型(如BLIP、FLAVA)奠定基础。
2.3 核心贡献
- 轻量化设计:
ViLT通过直接线性投影图像块(类似ViT),彻底摆脱了CNN和区域检测的复杂流程。 - 速度与性能平衡:
在NLVR2任务上性能最优,同时推理速度达到实时级别(15 ms)。 - 端到端训练:
纯Transformer架构支持图像-文本的端到端交互,无需多阶段预训练。
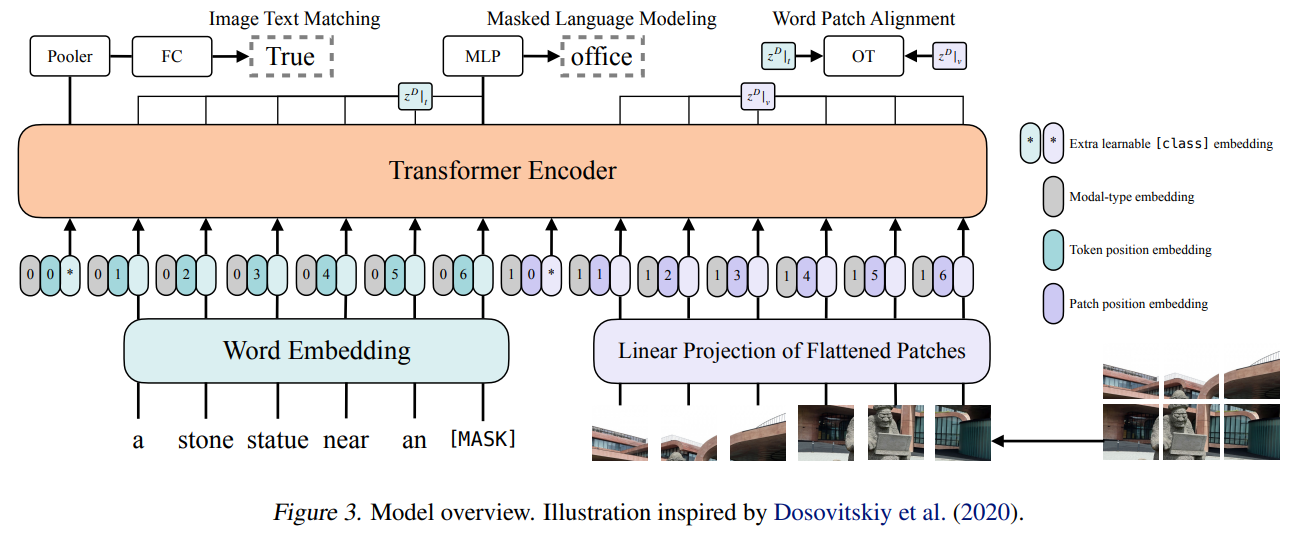
2.4 模型
下图展示了 ViLT(Vision-and-Language Transformer) 的核心架构,它是一种纯Transformer的多模态模型,完全摒弃了CNN和区域检测器,实现了高效的视觉-语言联合建模。
2.4.1 输入层
ViLT 的输入包含 图像 和 文本 两部分,分别通过以下方式编码:
(1) 视觉嵌入(Visual Embedding)
- 图像分块(Patch Partition):
- 输入图像被分割为固定大小的块(如16×16像素),类似ViT(Vision Transformer)。
- 线性投影(Linear Projection):
- 每个图像块通过一个全连接层(一般被卷积替代)映射为向量,得到 Patch Embeddings。
- 额外嵌入(Extra Embeddings):
[class]token:类似ViT,添加一个可学习的分类标记(用于全局表示)。- 位置编码(Patch Position Embedding):标记每个图像块的位置信息。
- 模态类型编码(Modal-type Embedding):区分图像和文本模态(如"0"表示图像,"1"表示文本)。
(2) 文本嵌入(Text Embedding)
- Word Embedding:
- 文本(如句子)通过BERT风格的词嵌入层转换为向量。
- 位置编码(Token Position Embedding):标记每个单词的位置。
- 模态类型编码:与视觉部分共享同一套模态标记。
2.4.2 Transformer 编码器(Transformer Encoder)
视觉和文本的嵌入向量拼接后输入标准的Transformer编码器(多层Self-Attention + FFN),实现跨模态交互:
- 自注意力机制(Self-Attention):
- 图像块和文本词互相计算注意力权重,捕捉跨模态关联(如"
[MASK]"与图像中的"office"对齐)。
- 图像块和文本词互相计算注意力权重,捕捉跨模态关联(如"
- 任务适配:
- Masked Language Modeling (MLM):随机遮盖文本词(如
[MASK]),模型根据图像和上下文预测被遮盖的词(多模态完形填空)。 - Image-Text Matching (ITM):通过额外的
[CLS]标记判断图像和文本是否匹配(二分类任务)。 - Word-Patch Alignment:通过注意力权重对齐单词和图像块(弱监督定位)。
- Masked Language Modeling (MLM):随机遮盖文本词(如
2.4.3 输出层(Task Heads)
根据不同任务,Transformer的输出会接入不同的轻量级头:
- MLM Head:预测被遮盖的单词(全连接层 + Softmax)。
- ITM Head:
[CLS]标记接一个二分类器(FC + Sigmoid)判断图文是否匹配。 - Pooler:可选的全连接层,用于提取全局特征(如检索任务)。
ViLT的架构标志着多模态模型从依赖卷积/检测器到纯Transformer驱动的范式转变,其高效性和简洁性为后续工作(如BLIP、FLAVA)奠定了基础。
3. 实验
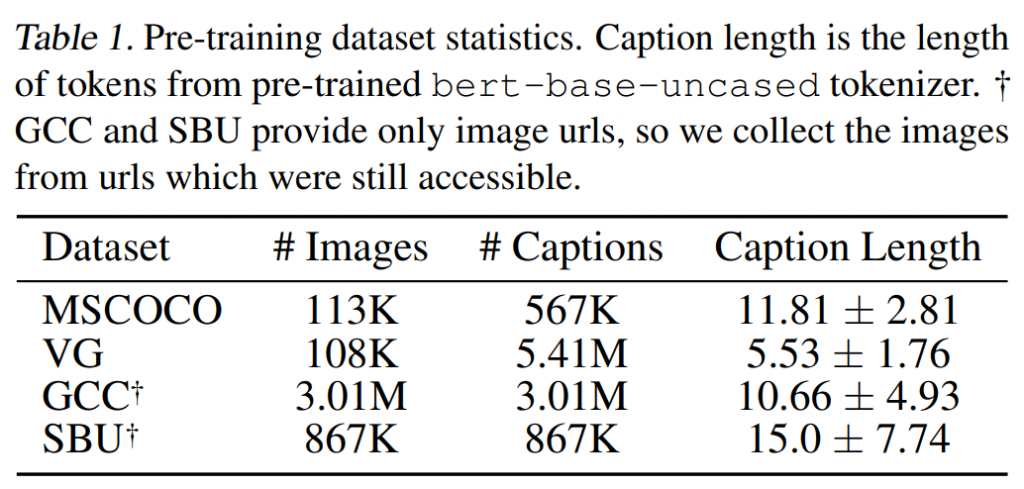
下表格统计了ViLT模型预训练使用的4个多模态数据集:MSCOCO(11.3万图/56.7万文本)、VG(10.8万图/541万短标注)、GCC(302万网络图)和SBU(86.7万图),其中GCC和SBU需从URL爬取图像。文本长度显示MSCOCO最稳定(11.81±2.81词),SBU波动最大(15.0±7.74词),VG最短(5.53词),这些数据为模型提供了规模与多样性平衡的训练素材。
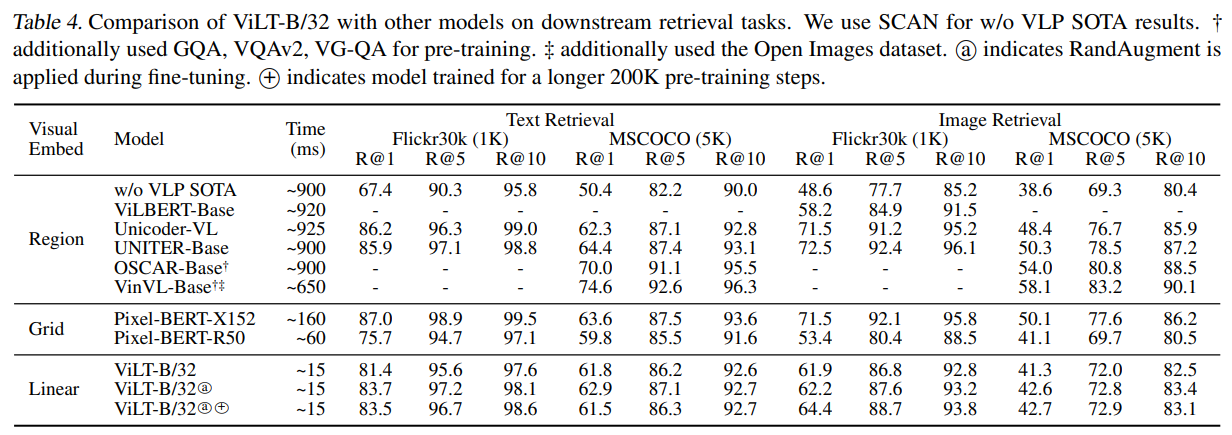
表格3对比了ViLT-B/32与其他视觉语言预训练模型在零样本检索任务上的表现。结果显示,基于线性视觉嵌入的ViLT-B/32仅需15ms推理时间,在Flickr30k文本检索任务中R@1达73.2,图像检索R@1达55.0,性能接近甚至超过基于区域特征的模型(如UNITER-Base),但速度快60倍(15ms vs 900ms)。加长训练(ViLT-B/32ⓒ)可进一步提升效果,验证了ViLT在效率与性能上的优势。值得注意的是,有些基线模型甚至不支持零样本检索,这其实与基于对比学习的预训练有关系。
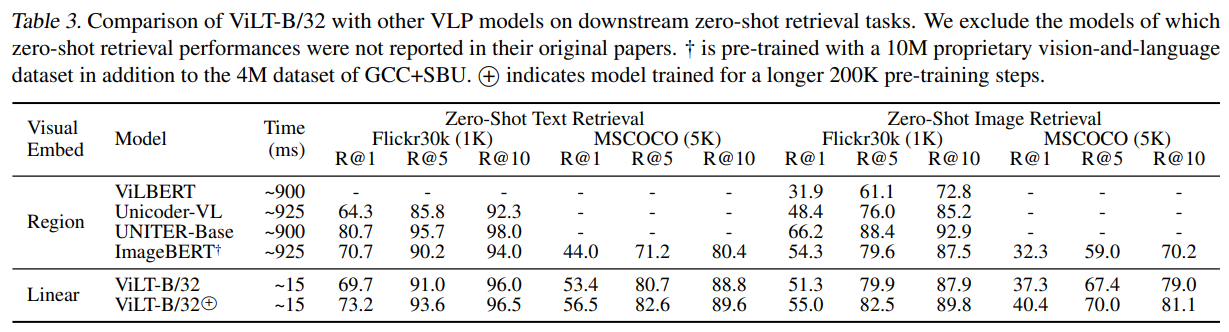
表格4对比了ViLT-B/32与其他视觉语言模型在检索任务中的表现。结果表明,ViLT在保持竞争力的性能下,实现了极致的效率提升。
表格5展示了ViLT-B/32模型的消融实验结果,通过控制不同训练策略和训练步数来评估模型性能。主要结论如下:
- 训练步数影响:随着训练步数从25K增加到200K,模型在各项任务上的性能持续提升。例如,VQAv2 test-dev准确率从68.96提升至71.26,Flickr30k文本检索R@1(零样本)从45.12提升至73.24。
- 训练策略对比:
- 全词掩码(⨀⨀):显著提升性能,如100K步时NLVR2 test-P从74.15提升至74.57。
- MPP目标(⨁⨁):进一步优化模型,100K步时Flickr30k R@1(零样本)从66.99提升至69.73。
- RandAugment(⨀⨀):在微调阶段使用后,200K步时MSCOCO图像检索R@1(零样本)达到40.42,优于未使用的对照组。
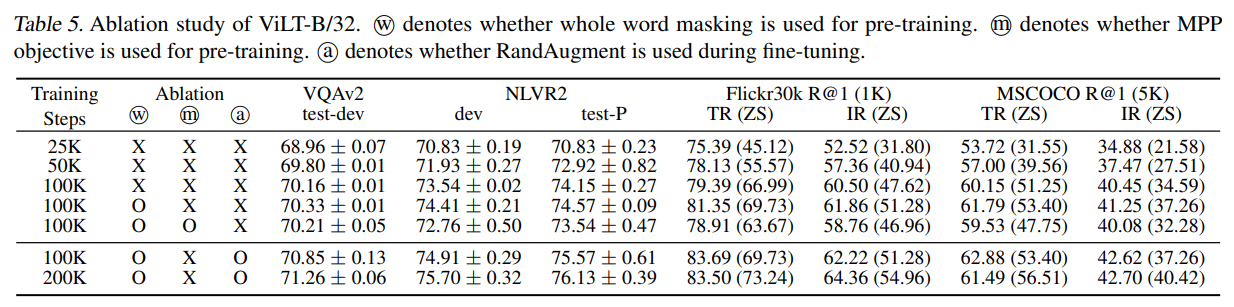
注:MPP(Masked Patch Prediction) 是ViLT模型中用于视觉预训练的自监督目标,类似于文本中的MLM(Masked Language Modeling),但针对图像模态设计。其核心思想是通过随机遮盖图像块并让模型预测被遮盖区域的视觉特征,从而学习图像与文本的跨模态关联。
4.讨论
本文提出了一种极简的视觉-语言预训练(VLP)架构——ViLT(Vision-and-Language Transformer)。实验表明,ViLT无需依赖复杂的卷积视觉嵌入网络(如Faster R-CNN或ResNet),即可达到与主流模型竞争的性能。我们呼吁未来研究应更关注Transformer内部的跨模态交互机制,而非单纯增强单模态嵌入器的能力。
尽管ViLT-B/32已证明无需卷积和区域监督的高效VLP模型可行性,但它更多是概念验证。实际的训练成本非常大!!!以下是未来可改进的方向:
1. 可扩展性(Scalability)
大规模Transformer(如BERT、ViT)已证明数据量与性能正相关,但当前对齐的视觉-语言数据集仍稀缺。未来可探索更大规模的ViLT变体(如ViLT-L/ViLT-H)。
2. 视觉掩码建模(Masked Modeling for Visual Inputs)
- 当前局限:
表格5显示,直接对图像块应用掩码预测(MPP)效果不佳,可能因视觉词汇的动态性(需避免固定聚类)。 - 改进方向:
参考无监督视觉学习中的交替聚类(Caron et al.)或同步聚类(Asano et al.)方法,设计更灵活的视觉掩码目标。
3. 数据增强策略(Augmentation Strategies)
对比学习研究表明,高斯模糊等增强策略能显著提升性能(如SimCLR)。未来可探索更适合多模态任务的文本-视觉联合增强方法,超越RandAugment的现有方案。
作者
arwin.yu.98@gmail.com





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1 评论