

Learning Methods of Deep Learning
create by Deepfinder
 Agenda
Agenda
- 师徒相授:有监督学习(Supervised Learning)
- 见微知著:无监督学习(Un-supervised Learning)
- 无师自通:自监督学习(Self-supervised Learning)
- 以点带面:半监督学习(Semi-supervised learning)
- 明辨是非:对比学习(Contrastive Learning)
- 举一反三:迁移学习(Transfer Learning)
- 针锋相对:对抗学习(Adversarial Learning)
- 众志成城:集成学习(Ensemble Learning)
- 殊途同归:联邦学习(Federated Learning)
- 百折不挠:强化学习(Reinforcement Learning)
- 求知若渴:主动学习(Active Learning)
- 万法归宗:元学习(Meta-Learning)
Tutorial 03 - 无师自通:自监督学习(Self-supervised Learning)
 自监督学习
自监督学习
- 一种无监督学习的版本,其中数据提供监督。
- 想法:保留部分数据,然后让神经网络根据剩余部分进行预测。
 Masked Autoencoders
Masked Autoencoders

Masked Autoencoders (MAE) 的基本工作原理:
数据处理阶段:
对输入的图像分割成许多小的图像块(patches)。
随机选择一部分图像块(通常是 75% 的图像块)进行遮掩(mask),即从输入中移除这些块。
剩下未遮掩的图像块被送入编码器(encoder)进行特征提取。
掩码令牌 (Mask Tokens):
在编码器之后,将掩码块的位置用特殊的“掩码令牌”来补充。掩码令牌是用于填充被遮掩的图像块位置的特殊标记。因为解码器需要完整的图像块序列(包含未遮掩的块和遮掩的块)来重建原始图像,所以掩码令牌在遮掩块的位置上起到了占位的作用。通过解码器(decoder)对编码后的图像块和掩码令牌进行处理,尝试重建原始图像的像素。
简单说,掩码令牌使解码器能够区分哪些部分是已知信息(编码器提供的未遮掩块),哪些是需要预测的未知信息(由掩码块的位置指示)。这有效地帮助解码器在训练过程中专注于重建被遮掩的部分。
使用阶段:
预训练完成后,解码器被丢弃,只有编码器被保留。
对于后续任务(如图像分类或目标识别),编码器接收完整的未遮掩图像块作为输入。
这种方法的核心思想是通过预测被遮掩的部分来让模型学习更好的图像表示。预训练阶段类似于自监督学习,通过对遮掩部分的重建来提升编码器的特征提取能力。
- 代码:
- HuggingFace:ViTMAE
- GitHub:官方 PyTorch 实现 (FAIR)、超赞 MAE 模型
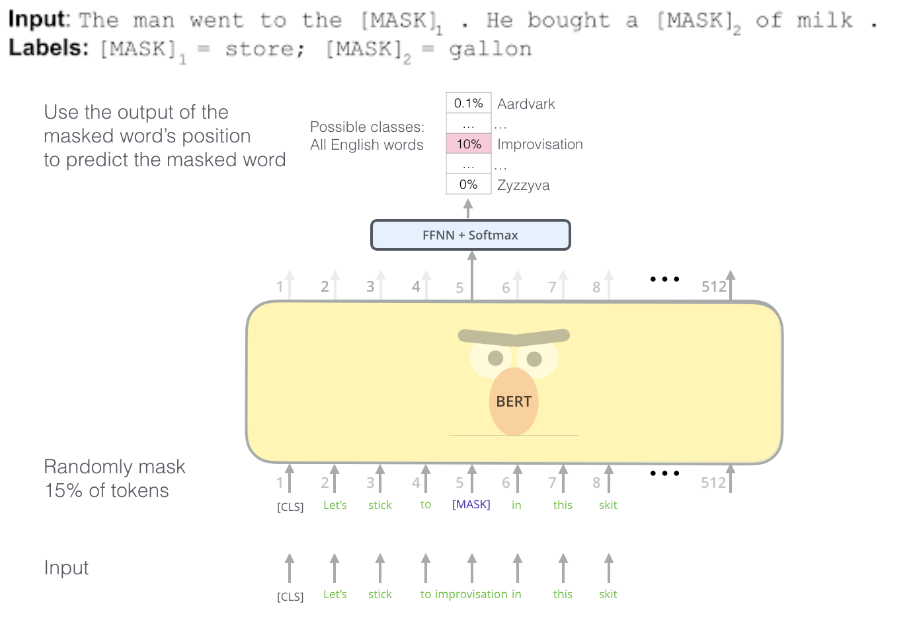
Masked Language Model (MLM)
掩码语言模型是 BERT 的关键训练方式,旨在通过掩码部分输入词汇来学习上下文语义。
- 训练过程:
掩码随机词:
对输入文本中的词随机选择 15% 进行处理:
80% 的概率用 [MASK] 替换(如 "apple" → "[MASK]")。
10% 的概率替换为随机词(如 "apple" → "orange")。
10% 的概率保持原词不变(如 "apple" → "apple")。
-
目标:
模型通过上下文预测被掩码的词。 -
作用:
通过双向上下文建模,让模型理解句子中每个词与周围词的关系,从而学习更深层次的语义表示。
Next Sentence Prediction (NSP)

 自监督和无监督的核心区别在哪里?
自监督和无监督的核心区别在哪里?
from datasets import load_dataset
def load_and_split_dataset(csv_file_path, test_size=0.2, seed=42):
"""
从 CSV 文件中加载数据,并拆分为训练集与测试集。
参数:
-------
csv_file_path : str
CSV 文件路径
test_size : float
测试集占比 (默认为 0.2, 即 20%)
seed : int
随机种子
返回:
-------
dataset_dict : DatasetDict
包含 'train' 与 'test' 两个切分的 DatasetDict 对象
"""
# 1. 加载 CSV 文件(其中一列名为 "review", 另一列名为 "sentiment")
raw_dataset = load_dataset(
"csv",
data_files=csv_file_path
)
# 注意:此时 raw_dataset 只包含一个名为 "train" 的切分。
# 因为默认情况下读取单一文件会放在 "train" 这个切分下。
# 你可以用 raw_dataset["train"] 来访问全部数据。
# 2. 把全部数据拆分成训练集和测试集(8:2)
# 使用 train_test_split 将原始 raw_dataset["train"] 切分为 'train' 和 'test'
dataset_dict = raw_dataset["train"].train_test_split(
test_size=test_size,
shuffle=True,
seed=seed
)
# 3. 打印数据形态与示例
print(f"Dataset splits: {dataset_dict}")
print(f"Train samples: {dataset_dict['train'].num_rows}")
print(f"Test samples: {dataset_dict['test'].num_rows}")
# 打印前两行作为示例
print("Train sample[0]:", dataset_dict["train"][0])
print("Test sample[0]:", dataset_dict["test"][0])
# 返回包含 'train' 和 'test' 的 DatasetDict
return dataset_dict
csv_path = "datasets/imdb/IMDB Dataset.csv" # 你的 CSV 文件路径
dataset = load_and_split_dataset(
csv_file_path=csv_path,
test_size=0.2,
seed=42
)/home/arwin/anaconda3/envs/dt/lib/python3.8/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
:219: RuntimeWarning: pyarrow.lib.Tensor size changed, may indicate binary incompatibility. Expected 64 from C header, got 80 from PyObject
Dataset splits: DatasetDict({
train: Dataset({
features: ['review', 'sentiment'],
num_rows: 40000
})
test: Dataset({
features: ['review', 'sentiment'],
num_rows: 10000
})
})
Train samples: 40000
Test samples: 10000
Train sample[0]: {'review': "The film disappointed me for many reasons: first of all the depiction of a future which seemed at first realistic to me was well-built but did only feature a marginal role. Then, the story itself was a weak copy of Lost in Translation. The Middle-Eastern setting, man with family meets new girl overseas, karaoke bar, the camera movements and the imagery - all that was a very bad imitation of the excellent Lost in Translation which had also credibility. This movie tries to be something brilliant and cultural: it is not. I wonder why Tim Robbins even considered doing this film!? The female main actress is awful - did she play the precog in Minority Report? And why do you have to show the vagina in a movie like this? Lost in Translation didn't have to show excessive love scenes. R-Rated just for this? This movie isn't even worth watching it from a videostore!", 'sentiment': 'negative'}
Test sample[0]: {'review': 'Arguably the finest serial ever made(no argument here thus far) about Earthman Flash Gordon, Professor Zarkov, and beautiful Dale Arden traveling in a rocket ship to another universe to save the planet. Along the way, in spellbinding, spectacular, and action-packed chapters Flash and his friends along with new found friends such as Prince Barin, Prince Thun, and the awesome King Vultan pool their resources together to fight the evils and armies of the merciless Ming of Mongo and the jealous treachery of his daughter Priness Aura(now she\'s a car!). This serial is not just a cut above most serials in terms of plot, acting, and budget - it is miles ahead in these areas. Produced by Universal Studios it has many former sets at its disposable like the laboratory set from The Bride of Frankenstein and the Opera House from The Phantom of the Opera just to name a few. The production values across the board are advanced, in my most humble opinion, for 1936. The costumes worn by many of these strange men and women are really creative and first-rate. We get hawk-men, shark men, lion men, high priests, creatures like dragons, octasacks, orangapoids, and tigrons(oh my!)and many, many other fantastic things. Are all of them believable and first-rate special effects? No way. But for 1936 most are very impressive. The musical score is awesome and the chapter beginnings are well-written, lengthy enough to revitalize viewer memories of the former chapter, and expertly scored. Director Frederick Stephani does a great job piecing everything together wonderfully and creating a worthy film for Alex Raymond\'s phenom comic strip. Lastly, the acting is pretty good in this serial. All too often serials have either no names with no talent surrounding one or two former talents - here most everyone has some ability. Don\'t get me wrong, this isn\'t a Shakespeare troupe by any means, but Buster Crabbe does a workmanlike, likable job as Flash. He is ably aided by Jean Arden, Priscella Lawson, and the rest of the cast in general with two performers standing out. But before I get to those two let me add as another reviewer noted, it must have been amazing for this serial to get by the Hayes Office. I see more flesh on Flash and on Jean Rogers and Priscella Lawson than in movies decades later. The shorts Crabbe(and unfortunately for all of us Professor Zarkov((Frank Shannon)) wears are about as form-fitting a pair of shorts guys can wear. The girls are wearing mid drifts throughout and are absolutely beautiful Jean Rogers may have limited acting talent but she is a blonde bombshell. Lawson is also very sultry and sensuous and beautiful. But for me the two actors that make the serial are Charles Middleton as Ming: officious, sardonic, merciless, and fun. Middleton is a class act. Jack "Tiny" Lipson plays King Vultan: boisterous, rousing, hilarious - a symbol for pure joy in life and the every essence of hedonism. Lipson steals each and every scene he is in. The plot meanders here, there, and everywhere - but Flash Gordon is the penultimate serial, space opera, and the basis for loads of science fiction to follow. Excellent!', 'sentiment': 'positive'}
import torch
from datasets import load_dataset
from transformers import (
BertTokenizer,
BertForMaskedLM,
DataCollatorForLanguageModeling,
TrainingArguments,
Trainer
)
# 1. 加载 IMDB 数据集
# 数据集包含 "train" 和 "test" 两个切分,每条数据包含 "text" 和 "label" 字段。
imdb_dataset = dataset
# 2. 初始化分词器(Tokenizer)
tokenizer = BertTokenizer.from_pretrained("datasets/bert-base-uncased")
# 3. 定义分词函数,并对数据集进行分词与数值化
# - `padding="max_length"`: 将句子补到同样长度
# - `truncation=True` : 超过指定长度会进行截断
# - `max_length=128` : 统一到 128 的序列长度
def tokenize_function(examples):
# 注意列名用 "review"
return tokenizer(
examples["review"],
padding="max_length",
truncation=True,
max_length=128
)
# remove_columns=["review"] 表示处理后去掉原始文本列,只保留模型所需的字段
tokenized_imdb = imdb_dataset.map(
tokenize_function,
batched=True,
remove_columns=["review"]
)
# 4. 准备 DataCollator
# DataCollatorForLanguageModeling 会自动对 batch 内的句子进行随机 Mask
# mlm_probability=0.15 表示在一个句子中有 15% 的 Token 被随机 Mask。
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=True,
mlm_probability=0.15
)
# 5. 定义 BERT MLM 模型
model = BertForMaskedLM.from_pretrained("datasets/bert-base-uncased")
# 6. 训练配置
training_args = TrainingArguments(
output_dir="./mlm_imdb_bert", # 模型输出路径
evaluation_strategy="epoch", # 每个 epoch 结束后进行一次评估
per_device_train_batch_size=8, # 训练时每块 GPU/CPU 的 batch size
per_device_eval_batch_size=8, # 测试时每块 GPU/CPU 的 batch size
num_train_epochs=1, # 演示用训练轮数,可根据需要修改
logging_steps=100, # 每隔多少步打印日志
save_steps=500 # 多少步保存一次模型
)
# 7. 用 Trainer 来封装训练流程
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_imdb["train"], # 训练集
eval_dataset=tokenized_imdb["test"], # 测试集
data_collator=data_collator
)
# 8. 进行训练
trainer.train()
# 9. 训练完成后,可使用 trainer.evaluate() 对测试集进行评估
eval_results = trainer.evaluate()
print(eval_results)
[2500/2500 20:34, Epoch 1/1]
Epoch
Training Loss
Validation Loss
1
1.984600
1.933474
[625/625 02:10]
{'eval_loss': 1.9387198686599731, 'eval_runtime': 130.2856, 'eval_samples_per_second': 76.754, 'eval_steps_per_second': 4.797, 'epoch': 1.0}
 Credits
Credits
- Icons made by Becris from www.flaticon.com
- Icons from Icons8.com - https://icons8.com
- Datasets from Kaggle - https://www.kaggle.com/
- Jason Brownlee - Why Initialize a Neural Network with Random Weights?
- OpenAI - Deep Double Descent
- Tal Daniel
作者
arwin.yu.98@gmail.com





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}