
Learning Methods of Deep Learning
create by Deepfinder
 Agenda
Agenda
- 师徒相授:有监督学习(Supervised Learning)
- 见微知著:无监督学习(Un-supervised Learning)
- 无师自通:自监督学习(Self-supervised Learning)
- 以点带面:半监督学习(Semi-supervised learning)
- 明辨是非:对比学习(Contrastive Learning)
- 举一反三:迁移学习(Transfer Learning)
- 针锋相对:对抗学习(Adversarial Learning)
- 众志成城:集成学习(Ensemble Learning)
- 殊途同归:联邦学习(Federated Learning)
- 百折不挠:强化学习(Reinforcement Learning)
- 求知若渴:主动学习(Active Learning)
- 万法归宗:元学习(Meta-Learning)
Tutorial 04 - 以点带面:半监督学习(Semi-supervised learning)
半监督学习(Semi-Supervised Learning)是指在仅有一部分样本带有人工标注、而大部分样本是无标注的场景下,仍能有效利用全部数据(有标注 + 无标注)进行模型训练的方法。它既利用了有监督学习中“有标注数据”的信息,又充分挖掘了无标注数据潜在的结构或分布特征,从而提升模型性能。
下面介绍常见的半监督学习主要途径及思路。
1. 自训练 (Self-Training) / 伪标签 (Pseudo-Labeling)
核心思路
- 用当前模型为无标注数据生成“伪标签”,再把它们当做“带标签数据”一起加入训练,迭代更新模型。
- 具体做法是:先用少量有标注数据训练一个初始模型,然后让模型在无标注数据上做预测,将高置信度的预测结果当作伪标签加入训练集中,再重新训练模型。
代表方法
- Self-Training / 自训练: 最基础的做法:对无标注样本进行预测并过滤掉模型置信度低的样本,只保留置信度高的伪标签加入到新的训练集。
- Pseudo-Labeling: Google Brain 提出的简单实现:让模型自己给无标注数据打标签,然后再把这些新生成的标签当作真标签来训练。
优势 & 局限
- 优点:实现简单,易于和其他方法结合。
- 缺点:如果初始模型本身偏差大,产生的伪标签质量低,可能会被错误标签“污染”,出现训练退化。
 如果模型初期预测有偏差,把错误预测当作“真标签”重新训练,可能会越训越错?
如果模型初期预测有偏差,把错误预测当作“真标签”重新训练,可能会越训越错?
2. 一致性正则化 (Consistency Regularization)
核心思路
- 假设: 同一个无标注样本在经过不同的扰动或增强后,模型的输出应该保持一致。将这种一致性误差作为正则项来约束模型,即要求模型对同一数据不同增强视图的预测结果差异尽可能小。
具体实现
- 在半监督学习里,通常有两个数据集:
- 有标注数据集 $D_L$ :样本少,但每个都有标签。
- 无标注数据集 $D_U$ :样本很多,没有标签。
- 对 $D_L$ ,我们通常使用监督学习的损失函数(例如分类的交叉摘):
$$
\mathcal{L}_{\text {supervised }}=\sum_{(x, y) \in D_L} \operatorname{CE}\left(f_\theta(x), y\right)
$$
这里 $f_\theta$ 表示模型, CE 表示交叉熵。
- 对 $D_U$ ,我们没有真实标签,却希望模型能"有稳定的输出"——也就是一致性正则化:
$$
\mathcal{L}_{\text {consistency }}=\sum_{x \in D_U} d\left(f_\theta\left(\operatorname{Aug}_1(x)\right), f_\theta\left(\operatorname{Aug}_2(x)\right)\right)
$$
-
$\mathrm{Aug}_1, \mathrm{Aug}_2$ 是对同一无标注样本的两种随机增强/扰动方式;
-
$d(\cdot, \cdot)$ 可以是均方误差、KL 散度等度量函数,用来衡量两次增强后的预测分布差异。
-
要求这两个增强视图的预测尽量相似,鼓励模型对"同一个样本"有一致的输出。
-
综合起来,在训练阶段,会把上面两部分损失加权求和:
$$
\mathcal{L}_{\text {total }}=\mathcal{L}_{\text {supervised }}+\lambda \cdot \mathcal{L}_{\text {consistency }}
$$
- 其中 $\lambda$ 是一个超参数,用来平衡监督损失和一致性损失的相对权重。
- 这样就同时利用了有标注数据(提供类别区分的监督信号)和无标注数据(提供一致性正则约束,提升模型的判别能力和泛化能力)。
优势 & 局限
- 优点:能有效利用无标注数据的分布信息,尤其在计算机视觉中配合数据增强效果明显。
- 缺点:一致性约束依赖合适的数据增强或扰动方式,对不同任务需要不同设计。
3. 基于生成模型 (Generative Approaches)
核心思路
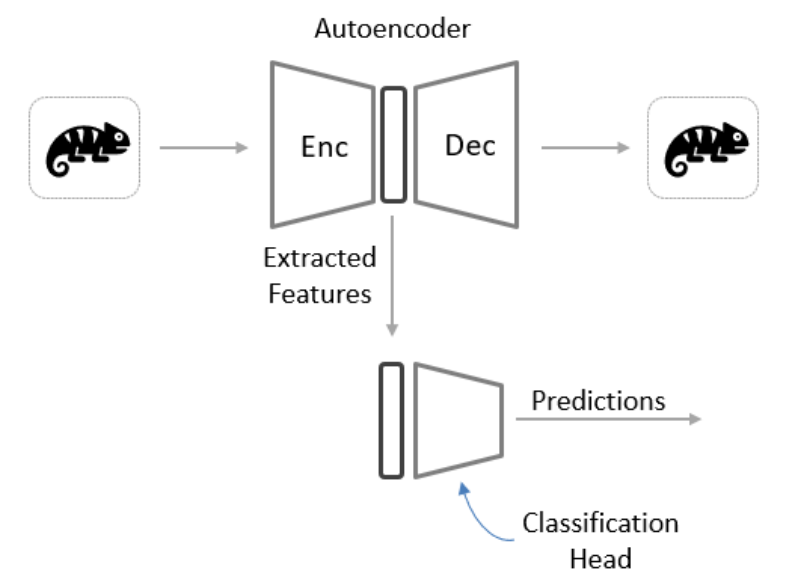
- 学习数据的分布模型(如变分自编码器 VAE、GAN 等),在此过程中同时使用有标注和无标注数据,使得模型在捕捉数据分布的同时,也能区分不同类别。
代表方法
- VAE + 分类器:把 VAE 编码器得到的隐变量空间既用于重构无标注样本,也辅助分类器分辨类别。
- Semi-Supervised GAN:在 GAN 框架中,引入一个判别器能够区分"真实图像的类别"和"生成图像"这两件事,从而在少量标签的情况下学习到有判别力的特征。
优势 & 局限
- 优点:生成式建模能更好地挖掘数据分布,对无标注数据的表示学习能力较强。
- 缺点:GAN 或VAE 的稳定训练以及和分类任务结合的策略较为复杂。
import os
import pickle
import torch
import random
import numpy as np
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# ---------------------------
# 1. 设置随机种子与设备
# ---------------------------
random.seed(42)
np.random.seed(42)
torch.manual_seed(42)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")
# ---------------------------
# 2. 加载 CIFAR-10 数据
# ---------------------------
def load_cifar10_batch(file_path):
"""
加载单个 batch 文件,返回图像和标签。
"""
with open(file_path, 'rb') as f:
batch = pickle.load(f, encoding='bytes')
images = batch[b'data'] # shape: (10000, 3072)
labels = batch[b'labels'] if b'labels' in batch else batch[b'fine_labels']
# 重塑图像为 (N, 3, 32, 32)
images = images.reshape(-1, 3, 32, 32)
images = images.astype(np.float32) / 255.0 # 归一化到 [0,1]
# 转换为 Tensor
images = torch.tensor(images)
labels = torch.tensor(labels, dtype=torch.long)
return images, labels
def load_cifar10_data(data_dir):
"""
加载整个 CIFAR-10 数据集,返回训练集和测试集的图像与标签。
"""
train_images = []
train_labels = []
# 加载训练批次
for i in range(1, 6):
batch_file = os.path.join(data_dir, f'data_batch_{i}')
images, labels = load_cifar10_batch(batch_file)
train_images.append(images)
train_labels.append(labels)
# 拼接所有训练批次
train_images = torch.cat(train_images, dim=0) # shape: (50000, 3, 32, 32)
train_labels = torch.cat(train_labels, dim=0) # shape: (50000,)
# 加载测试批次
test_file = os.path.join(data_dir, 'test_batch')
test_images, test_labels = load_cifar10_batch(test_file) # shape: (10000, 3, 32, 32), (10000,)
return train_images, train_labels, test_images, test_labels
# 指定 CIFAR-10 数据目录
CIFAR10_DIR = 'datasets/cifar-10-batches-py' # 根据实际路径修改
# 加载数据
train_images_all, train_labels_all, test_images_all, test_labels_all = load_cifar10_data(CIFAR10_DIR)
print(f"训练集图像数量: {train_images_all.shape[0]}")
print(f"测试集图像数量: {test_images_all.shape[0]}")
使用设备: cuda
训练集图像数量: 50000
测试集图像数量: 10000部分标记的数据
您会注意到,数据集中的所有图像都已提供相应的标签。如果您使用所有数据训练模型,那么您将拥有一个完全监督的模型。
本着半监督学习的精神,我们需要模拟缺乏标记数据的情况。一种简单的方法是提取一小部分图像及其相应的标签;然后您可以假装其他所有内容都没有标签。
下面的代码提取了这个“监督”数据子集。请注意,所有对象类都有相同数量的提取样本。建议您从仅提取 1% 的数据集开始,以便测试和调试后续代码的速度更快。您当然可以在以后增加这一部分。
# ---------------------------
# 3. 拆分“有标签”和“无标签”数据
# ---------------------------
NUM_LABELED_PER_CLASS = 50 # 每类有标签样本数
NUM_CLASSES = 10
# 初始化计数器
count_per_class = [0] * NUM_CLASSES
labeled_images = []
labeled_labels = []
unlabeled_images = []
unlabeled_labels = []
# 打乱索引以确保随机性
indices = list(range(len(train_images_all)))
random.shuffle(indices)
for idx in indices:
img = train_images_all[idx]
lbl = train_labels_all[idx].item()
if count_per_class[lbl] < NUM_LABELED_PER_CLASS:
labeled_images.append(img)
labeled_labels.append(lbl)
count_per_class[lbl] += 1
else:
unlabeled_images.append(img)
unlabeled_labels.append(lbl) # 标签仍然存在,但后续不使用
print(f"有标签数据数量: {len(labeled_images)}") # 预计: 10 * 50 = 500
print(f"无标签数据数量: {len(unlabeled_images)}") # 预计: 50000 - 500 = 49500
# ---------------------------
# 4. 定义 PyTorch Dataset 类
# ---------------------------
class LabeledCIFARDataset(Dataset):
def __init__(self, images, labels):
"""
有标签数据集
"""
self.images = images
self.labels = labels
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
x = self.images[idx]
y = self.labels[idx]
return x, y
class UnlabeledCIFARDataset(Dataset):
def __init__(self, images):
"""
无标签数据集
"""
self.images = images
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
x = self.images[idx]
return x
class CIFARValDataset(Dataset):
def __init__(self, images, labels):
"""
验证/测试数据集
"""
self.images = images
self.labels = labels
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
x = self.images[idx]
y = self.labels[idx]
return x, y
# ---------------------------
# 5. 创建 DataLoader
# ---------------------------
BATCH_SIZE = 64
# 有标签 DataLoader
labeled_dataset = LabeledCIFARDataset(labeled_images, labeled_labels)
labeled_loader = DataLoader(
labeled_dataset,
batch_size=BATCH_SIZE,
shuffle=True
)
# 无标签 DataLoader
unlabeled_dataset = UnlabeledCIFARDataset(unlabeled_images)
unlabeled_loader = DataLoader(
unlabeled_dataset,
batch_size=BATCH_SIZE,
shuffle=True
)
# 验证/测试 DataLoader
val_dataset = CIFARValDataset(test_images_all, test_labels_all)
val_loader = DataLoader(
val_dataset,
batch_size=BATCH_SIZE,
shuffle=False
)
print(f"有标签数据批次数: {len(labeled_loader)}") # 500 / 64 ≈ 8
print(f"无标签数据批次数: {len(unlabeled_loader)}") # 49500 / 64 ≈ 774
print(f"验证/测试数据批次数: {len(val_loader)}") # 10000 / 64 ≈ 157有标签数据数量: 500
无标签数据数量: 49500
有标签数据批次数: 8
无标签数据批次数: 774
验证/测试数据批次数: 157定义模型架构
现在我们已经准备好了数据,让我们将注意力转向模型架构。请记住,我们的目标不是从我们拥有的数据中获得最佳性能,而是专注于学习如何实施半监督技术。考虑到这一点,我们将研究能够从头开始构建的简单toy model。
您现在应该熟悉各种半监督技术。这里我们以VAE + 分类器为例子,可以针对两个不同的任务进行训练。

# ---------------------------
# 6. 定义模型(VAE + 分类器)
# ---------------------------
class Encoder(nn.Module):
def __init__(self, latent_dim=32):
super(Encoder, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 3, stride=2, padding=1) # [B, 16, 16, 16]
self.conv2 = nn.Conv2d(16, 32, 3, stride=2, padding=1) # [B, 32, 8, 8]
self.fc = nn.Linear(32*8*8, 128)
self.mu_layer = nn.Linear(128, latent_dim)
self.logvar_layer = nn.Linear(128, latent_dim)
def forward(self, x):
h = F.relu(self.conv1(x)) # [B, 16, 16, 16]
h = F.relu(self.conv2(h)) # [B, 32, 8, 8]
h = h.view(h.size(0), -1) # [B, 32*8*8]
h = F.relu(self.fc(h)) # [B, 128]
mu = self.mu_layer(h) # [B, latent_dim]
logvar = self.logvar_layer(h) # [B, latent_dim]
return mu, logvar
class Decoder(nn.Module):
def __init__(self, latent_dim=32):
super(Decoder, self).__init__()
self.fc = nn.Linear(latent_dim, 32*8*8)
self.deconv1 = nn.ConvTranspose2d(32, 16, 4, stride=2, padding=1) # [B,16,16,16]
self.deconv2 = nn.ConvTranspose2d(16, 3, 4, stride=2, padding=1) # [B,3,32,32]
def forward(self, z):
h = F.relu(self.fc(z)) # [B, 32*8*8]
h = h.view(h.size(0), 32, 8, 8) # [B, 32, 8, 8]
h = F.relu(self.deconv1(h)) # [B, 16, 16, 16]
x_recon = torch.sigmoid(self.deconv2(h)) # [B, 3, 32, 32]
return x_recon
class Classifier(nn.Module):
def __init__(self, latent_dim=32, num_classes=10):
super(Classifier, self).__init__()
self.fc1 = nn.Linear(latent_dim, 64)
self.fc2 = nn.Linear(64, num_classes)
def forward(self, z):
h = F.relu(self.fc1(z)) # [B, 64]
logits = self.fc2(h) # [B, num_classes]
return logits
class VAE_Classifier(nn.Module):
def __init__(self, latent_dim=32, num_classes=10):
super(VAE_Classifier, self).__init__()
self.encoder = Encoder(latent_dim)
self.decoder = Decoder(latent_dim)
self.classifier = Classifier(latent_dim, num_classes)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar) # [B, latent_dim]
eps = torch.randn_like(std) # [B, latent_dim]
return mu + eps * std # [B, latent_dim]
def forward_vae(self, x):
mu, logvar = self.encoder(x) # [B, latent_dim], [B, latent_dim]
z = self.reparameterize(mu, logvar) # [B, latent_dim]
x_recon = self.decoder(z) # [B, 3, 32, 32]
return x_recon, mu, logvar, z
def forward_classifier(self, x):
mu, logvar = self.encoder(x) # [B, latent_dim], [B, latent_dim]
logits = self.classifier(mu) # [B, num_classes]
return logits
# 实例化模型
latent_dim = 32
num_classes = 10
model = VAE_Classifier(latent_dim=latent_dim, num_classes=num_classes).to(device)
3. 训练阶段的"两条损失"
- 3.1 训练 VAE (无标签数据可用)
当你对无标注数据做川练时,只要做VAE的重构损失 + KL 散度即可:
$$
\mathcal{L}_{\mathrm{VAE}}=|x-\hat{x}|^2(\text { or } \mathrm{BCE})+\mathrm{KL}\left[q_\phi(z \mid x) | p(z)\right]
$$
- 重构损失: $|x-\hat{x}|^2$ 或二元交叉摘(BCE)等度量,让解码器输出的 $\hat{x}$ 与原图 $x$ 尽量相似。
- KL 散度:让编码器的潜在分布 $q_\phi(z \mid x)$ 靠近先验 $p(z)$ (通常是 $\mathcal{N}(0, I)$ )。
无标注数据上我们不计算分类损失,因为没有标签,但可以昭样通过 VAE 重构去学习潜在表示。
- 3.2 训练分类器(需有标注数据)
当你对有标注数据进行训练时,同时更新VAE 及分类器,因为分类器要用到编码器的输出:
$$
\mathcal{L}_{\text {Classifier }}=\text { CrossEntropy }(\text { logits }, y)
$$
其中:
- logits = classifier(encoder(x)) (或 reparameterized $z$ )。
- $y$ 是图像对应的真实类别标签( $0 \sim 9$ )。
这个部分只在"有标签数据"上存在。
- 3.3 总损失
综合起来,你可以同时或交替地对有标签 / 无标签批次进行更新。
def vae_loss_function(x, x_recon, mu, logvar):
# x: [B, 3, 32, 32]
# x_recon: [B, 3, 32, 32]
# mu, logvar: [B, latent_dim]
# 1) 重构损失 - 使用 BCE
recon_loss = F.binary_cross_entropy(x_recon, x, reduction='sum') / x.size(0)
# 或者 mean() 并再根据需要调节平衡
# 2) KL 散度
# KL = 0.5 * sum( exp(logvar) + mu^2 - 1 - logvar )
kl_divergence = 0.5 * torch.mean(torch.sum(torch.exp(logvar) + mu**2 - 1. - logvar, dim=1))
return recon_loss + kl_divergence, recon_loss, kl_divergence
def classifier_loss_function(logits, y):
return F.cross_entropy(logits, y)
# ---------------------------
# 8. 定义验证函数
# ---------------------------
def evaluate_on_valset(model, val_loader):
"""
在验证集上评估分类准确率
"""
model.eval()
correct = 0
total = 0
with torch.no_grad():
for x_val, y_val in val_loader:
x_val = x_val.to(device)
y_val = y_val.to(device)
logits = model.forward_classifier(x_val) # [B, num_classes]
preds = torch.argmax(logits, dim=1) # [B]
correct += (preds == y_val).sum().item()
total += y_val.size(0)
acc = correct / total
return acc# ---------------------------
# 9. 实现 Baseline 和 Semi-Supervised 训练
# ---------------------------
def train_baseline(model, labeled_loader, val_loader, epochs=10, lr=1e-3):
"""
Baseline 训练:仅使用有标签数据训练模型
"""
optimizer = optim.Adam(model.parameters(), lr=lr)
for epoch in range(epochs):
model.train()
total_loss = 0.0
total_clf = 0.0
for x_labeled, y_labeled in labeled_loader:
x_labeled = x_labeled.to(device)
y_labeled = y_labeled.to(device)
optimizer.zero_grad()
# 分类器前向
logits = model.forward_classifier(x_labeled)
clf_loss = classifier_loss_function(logits, y_labeled)
# 反向传播和优化
clf_loss.backward()
optimizer.step()
total_loss += clf_loss.item()
total_clf += clf_loss.item()
# 计算平均损失
avg_loss = total_loss / len(labeled_loader)
avg_clf = total_clf / len(labeled_loader)
# 验证集评估
val_acc = evaluate_on_valset(model, val_loader)
print(f"[Baseline] Epoch {epoch+1}/{epochs}, Loss: {avg_loss:.4f}, Clf: {avg_clf:.4f}, Val Acc: {val_acc:.4f}")
return model
def train_semi_supervised(model, labeled_loader, unlabeled_loader, val_loader, epochs=10, lr=1e-3, lambda_unsupervised=1.0, confidence_threshold=0.8):
"""
半监督训练:同时使用有标签和无标签数据
"""
optimizer = optim.Adam(model.parameters(), lr=lr)
for epoch in range(epochs):
model.train()
total_loss = 0.0
total_recon = 0.0
total_kl = 0.0
total_clf = 0.0
total_unsupervised = 0.0
# a) 有标签数据训练
for x_labeled, y_labeled in labeled_loader:
x_labeled = x_labeled.to(device)
y_labeled = y_labeled.to(device)
optimizer.zero_grad()
# VAE 前向
x_recon, mu, logvar, z = model.forward_vae(x_labeled)
vae_loss, recon_loss, kl_div = vae_loss_function(x_labeled, x_recon, mu, logvar)
# 分类器前向
logits = model.forward_classifier(x_labeled)
clf_loss = classifier_loss_function(logits, y_labeled)
# 合并损失
total_batch_loss = vae_loss + clf_loss
total_batch_loss.backward()
optimizer.step()
total_loss += total_batch_loss.item()
total_recon += recon_loss.item()
total_kl += kl_div.item()
total_clf += clf_loss.item()
# b) 无标签数据训练(伪标签)
for x_unlabeled in unlabeled_loader:
x_unlabeled = x_unlabeled.to(device)
optimizer.zero_grad()
# 生成伪标签
logits = model.forward_classifier(x_unlabeled)
probs = torch.softmax(logits, dim=-1)
max_probs, pseudo_labels = torch.max(probs, dim=-1)
# 只使用高置信度的伪标签
high_confidence_mask = max_probs > confidence_threshold
if high_confidence_mask.sum() > 0:
pseudo_labels = pseudo_labels[high_confidence_mask]
x_unlabeled = x_unlabeled[high_confidence_mask]
# 计算无标签数据的分类损失
clf_loss = classifier_loss_function(logits[high_confidence_mask], pseudo_labels)
# 总损失 = 无标签数据损失 + 有标签数据损失
total_unsupervised_loss = lambda_unsupervised * clf_loss
total_unsupervised_loss.backward()
optimizer.step()
total_unsupervised += total_unsupervised_loss.item()
# 计算平均损失
avg_loss = total_loss / len(labeled_loader)
avg_recon = total_recon / len(labeled_loader)
avg_kl = total_kl / len(labeled_loader)
avg_clf = total_clf / len(labeled_loader)
avg_unsupervised = total_unsupervised / len(unlabeled_loader)
# 验证集评估
val_acc = evaluate_on_valset(model, val_loader)
print(f"[Semi-Supervised] Epoch {epoch+1}/{epochs}, Loss: {avg_loss:.4f}, Clf: {avg_clf:.4f}, Unsupervised: {avg_unsupervised:.4f}, Val Acc: {val_acc:.4f}")
return model
# ---------------------------
# 10. 运行训练并对比
# ---------------------------
def main():
# 实例化两个独立的模型
model_baseline = VAE_Classifier(latent_dim=latent_dim, num_classes=num_classes).to(device)
model_semi = VAE_Classifier(latent_dim=latent_dim, num_classes=num_classes).to(device)
# 定义训练参数
epochs = 10
learning_rate = 1e-2
print("开始 Baseline 训练(仅有标签数据)...")
model_baseline = train_baseline(model_baseline, labeled_loader, val_loader, epochs=epochs, lr=learning_rate)
print("\n开始 半监督训练(有标签 + 无标签数据)...")
model_semi = train_semi_supervised(model_semi, labeled_loader, unlabeled_loader, val_loader, epochs=epochs, lr=learning_rate)
# 最终评估对比
baseline_acc = evaluate_on_valset(model_baseline, val_loader)
semi_acc = evaluate_on_valset(model_semi, val_loader)
print(f"\n最终对比结果:\n Baseline 准确率 = {baseline_acc:.4f}\n 半监督准确率 = {semi_acc:.4f}")
if __name__ == "__main__":
main()开始 Baseline 训练(仅有标签数据)...
[Baseline] Epoch 1/10, Loss: 2.3153, Clf: 2.3153, Val Acc: 0.1000
[Baseline] Epoch 2/10, Loss: 2.3001, Clf: 2.3001, Val Acc: 0.1632
[Baseline] Epoch 3/10, Loss: 2.2466, Clf: 2.2466, Val Acc: 0.1284
[Baseline] Epoch 4/10, Loss: 2.2630, Clf: 2.2630, Val Acc: 0.1401
[Baseline] Epoch 5/10, Loss: 2.2094, Clf: 2.2094, Val Acc: 0.1573
[Baseline] Epoch 6/10, Loss: 2.1534, Clf: 2.1534, Val Acc: 0.1925
[Baseline] Epoch 7/10, Loss: 2.1225, Clf: 2.1225, Val Acc: 0.2331
[Baseline] Epoch 8/10, Loss: 2.0578, Clf: 2.0578, Val Acc: 0.2203
[Baseline] Epoch 9/10, Loss: 2.0038, Clf: 2.0038, Val Acc: 0.2675
[Baseline] Epoch 10/10, Loss: 1.8889, Clf: 1.8889, Val Acc: 0.2509
开始 半监督训练(有标签 + 无标签数据)...
[Semi-Supervised] Epoch 1/10, Loss: 2130.3845, Clf: 2.3115, Unsupervised: 0.0000, Val Acc: 0.0872
[Semi-Supervised] Epoch 2/10, Loss: 2125.7730, Clf: 2.2873, Unsupervised: 0.0000, Val Acc: 0.1113
[Semi-Supervised] Epoch 3/10, Loss: 2106.7699, Clf: 2.2789, Unsupervised: 0.0000, Val Acc: 0.1629
[Semi-Supervised] Epoch 4/10, Loss: 2088.1254, Clf: 2.2613, Unsupervised: 0.0000, Val Acc: 0.1784
[Semi-Supervised] Epoch 5/10, Loss: 2069.3262, Clf: 2.2282, Unsupervised: 0.0000, Val Acc: 0.2065
[Semi-Supervised] Epoch 6/10, Loss: 2087.0404, Clf: 2.1865, Unsupervised: 0.0000, Val Acc: 0.1421
[Semi-Supervised] Epoch 7/10, Loss: 2071.9022, Clf: 2.1797, Unsupervised: 0.0000, Val Acc: 0.1959
[Semi-Supervised] Epoch 8/10, Loss: 2049.9933, Clf: 2.1584, Unsupervised: 0.0000, Val Acc: 0.2161
[Semi-Supervised] Epoch 9/10, Loss: 2037.8330, Clf: 2.1724, Unsupervised: 0.0000, Val Acc: 0.1703
[Semi-Supervised] Epoch 10/10, Loss: 2030.8822, Clf: 2.1445, Unsupervised: 0.0000, Val Acc: 0.2203
最终对比结果:
Baseline 准确率 = 0.2509
半监督准确率 = 0.2203最终对比结果显示,Baseline模型的准确率为0.2509,而半监督模型的准确率为0.2203。需要注意的是,这个项目仅是一个演示(demo),其主要目的是为了讲解半监督训练的基本原理和工作流程,而不是追求最终的精度表现。半监督训练的效果通常依赖于大量的数据、细致的参数调优以及合适的模型设计。在实际应用中,半监督学习可以通过利用未标注数据来提升模型性能,但这一过程需要经过反复的实验和调整。因此,当前的结果并不代表半监督学习的最终潜力,而是为进一步探索和优化提供了一个起点。
 Credits
Credits
- Icons made by Becris from www.flaticon.com
- Icons from Icons8.com - https://icons8.com
- Datasets from Kaggle - https://www.kaggle.com/
- Jason Brownlee - Why Initialize a Neural Network with Random Weights?
- OpenAI - Deep Double Descent
- Tal Daniel
作者
arwin.yu.98@gmail.com





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}