
1. 摘要
目前最先进的计算机视觉系统通常通过预定义的对象类别进行训练。这种受限的监督形式严重限制了模型的通用性和实用性——因为任何新视觉概念的识别都需要额外的标注数据。而直接从图像相关的原始文本中学习,则提供了一种更具潜力的替代方案,它能利用更广泛的监督信号来源。
论文的研究表明,一个简单的预训练任务——即预测哪段文本描述与哪张图像匹配——可以高效、可扩展地从互联网收集的4亿个(图像,文本)配对数据集中,从头开始学习最先进的图像表征。预训练完成后,通过自然语言即可调用已学习的视觉概念(或描述新概念),从而实现模型在下游任务中的零样本迁移。
论文地址:https://arxiv.org/pdf/2103.00020
2. 方法
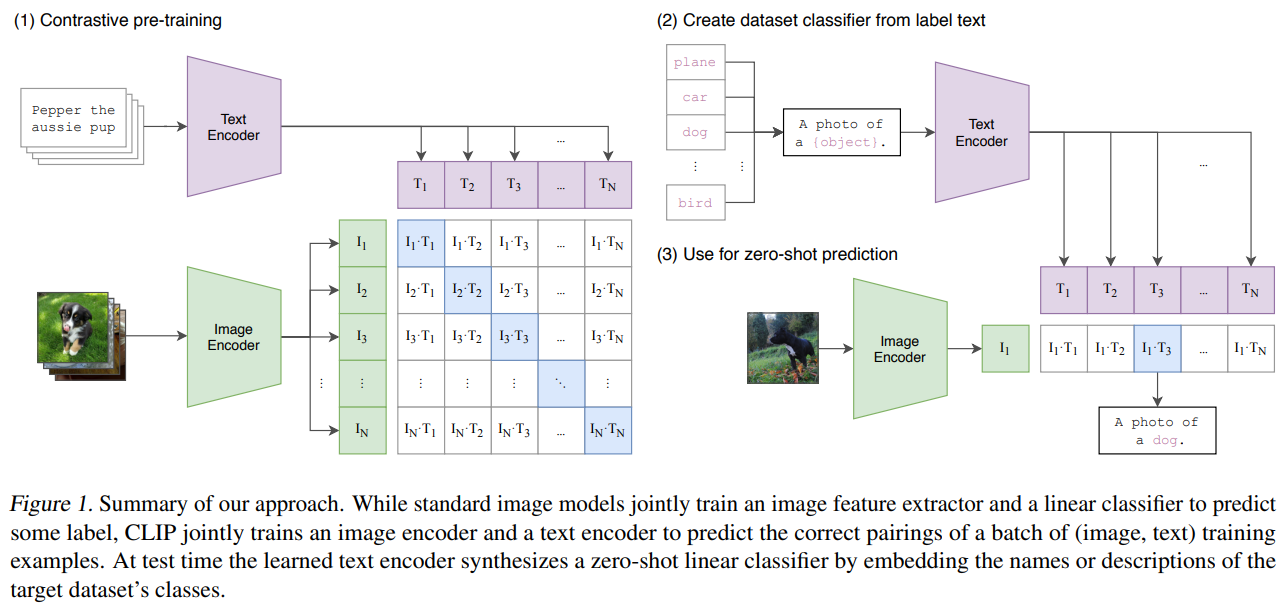
(图1)详细展示了CLIP(Contrastive Language-Image Pre-training)模型的核心工作流程,分为三个关键阶段。图示符号详解:
| 符号 | 含义 | 技术作用 |
| l_i | 第i张图像的特征向量 | 视觉概念的向量化表示 |
| T_j | 第j个文本的特征向量 | 语言概念的向量化表示 |
| l_i-T_j | 图像-文本对相似度得分 | 对比学习的优化目标 |
2.1. 对比预训练阶段(Contrastive Pre-training)
结构说明:
- 正样本采样:将配对的图文采样作为正样本。
- 负样本采样:某图片与同一批次内其他图像的文本描述组成负样本。
- 图像编码器(Image Encoder):将输入图像转换为图像特征向量(l₁, l₂... l_N),具体做法类似VIT模型
- 文本编码器(Text Encoder):将对应的文本描述(T₁, T₂... T_N)转换为文本特征向量,具体做法类似Transformer模型
- 对比学习矩阵:
矩阵中每个元素表示图像特征($l_i$)与文本特征($T_j$)的相似度得分($l_i-T_j$)。模型通过最大化正确配对(对角线元素)的相似度,最小化错误配对(非对角线元素)的相似度进行训练。
2.2. 零样本分类器生成(Create Dataset Classifier)
流程说明:
- 标签文本模板化:将目标数据集的类别(如"plane, car, dog, bird")通过提示工程转换为自然语言描述(如"A photo of a [object]")
- 文本编码器嵌入:通过预训练好的文本编码器,将这些模板化描述转换为类别特征向量,即"文本原型(T₁...$T_N$)"。
关键创新:
- 动态分类头生成:传统模型需要固定类别数的线性分类层,而CLIP通过提示工程(prompt)与文本编码器实时生成与类别描述对应的分类权重。
2.3. 零样本预测(Zero-shot Prediction)
工作流程:
- 图像编码器提取待预测图像的特征向量($l_i$)
- 计算该特征与所有文本原型(T₁...$T_N$)的余弦相似度
- 选择相似度最高的文本原型对应的类别作为预测结果(如图中匹配到"A photo of a dog")
- 整个过程无需任何微调,直接利用预训练好的双编码器完成预测
CLIP奠定了对比学习在多模态预训练中的统治地位,后续工作(如CoCa、BLIP等)均延续了这一核心设计思想。
3. 实验
3.1 Comparing CLIP to prior zero-shot transfer image classification results.
CLIP论文进行了大量的实验来证明CLIP的性能,尤其是zero-shot的能力。同时,也讨论了CLP模型的一些限制,下面举例其中的一些实验结果。其他实验详见原图。
如表1所示:CLIP零样本分类全面碾压Visual N-Grams(2017),三大数据集提升26%~65%,尤其ImageNet从11.5%→76.2%。
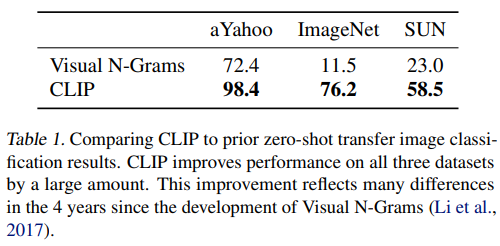
关键原因:对比学习+4亿图文对的跨模态预训练 >> N-gram统计方法。CLIP证明了大规模预训练对零样本任务的革命性改进,但领域适配和计算效率仍是挑战。
3.2 Zero-shot CLIP is much more robust to distribution shift than standard ImageNet models.
如图13是一个大规模的系统性评估,图表显示了从ImageNet的扩展数据集,存在多个特殊版本(如ImageNet-R、ImageNet-Sketch、ImageNet-A等),这些通常用于测试模型在:
- 渲染图像(R).
- 对抗样本(A)等场景的鲁棒性
- ImageNet-Sketch 素描风格
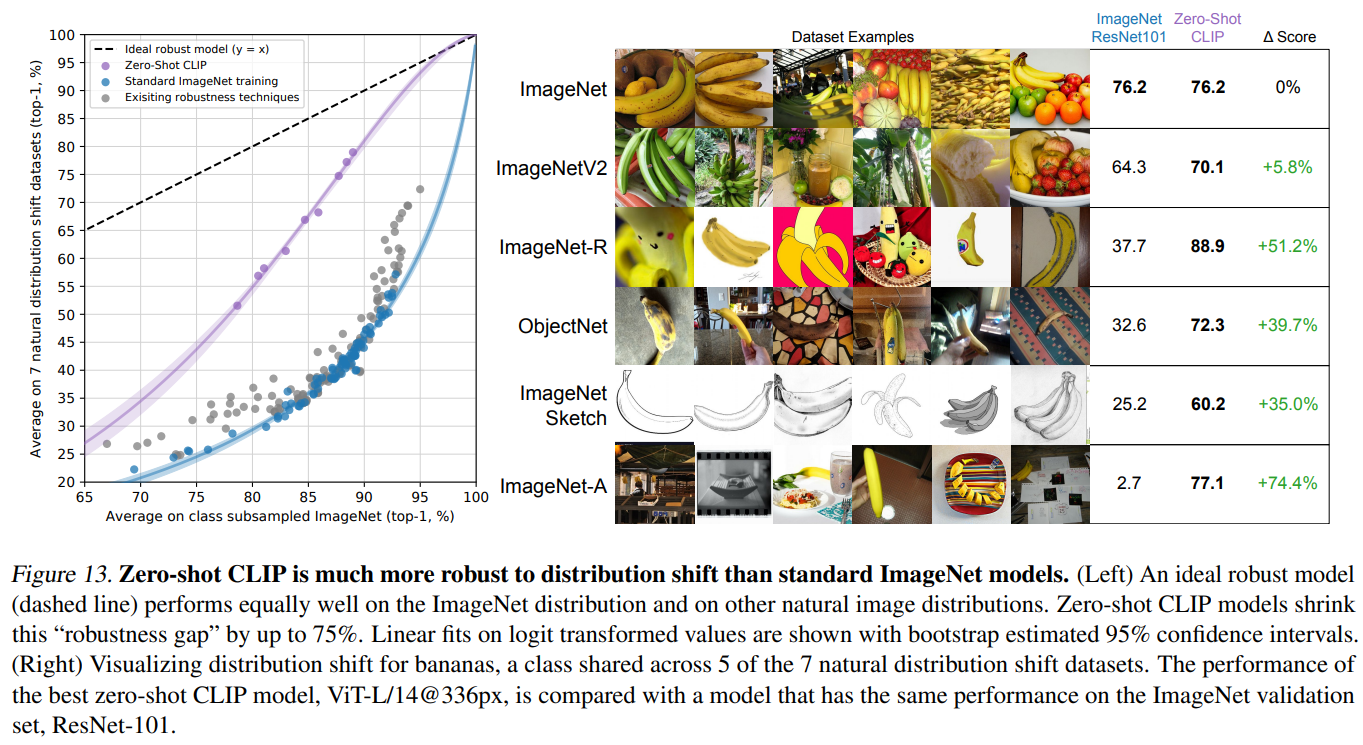
结果表明,CLIP在不同数据分布上具体强大的泛化能力,其零样本预测能力比基于有监督训练出的ResNet101模型性能有大幅度提升,尤其是在对抗样本方面。
3.3 Few statistically significant improvements in accuracy due to detected data overlap.
作者担心测试数据可能"混入"了训练数据(即数据重叠 data overlap),就像考试前偷偷看到了考题,这会影响成绩的真实性。他们用特殊方法检测出了这些"疑似泄题"的数据,想看看CLIP模型是不是靠"作弊"才得高分的。结果如图17:
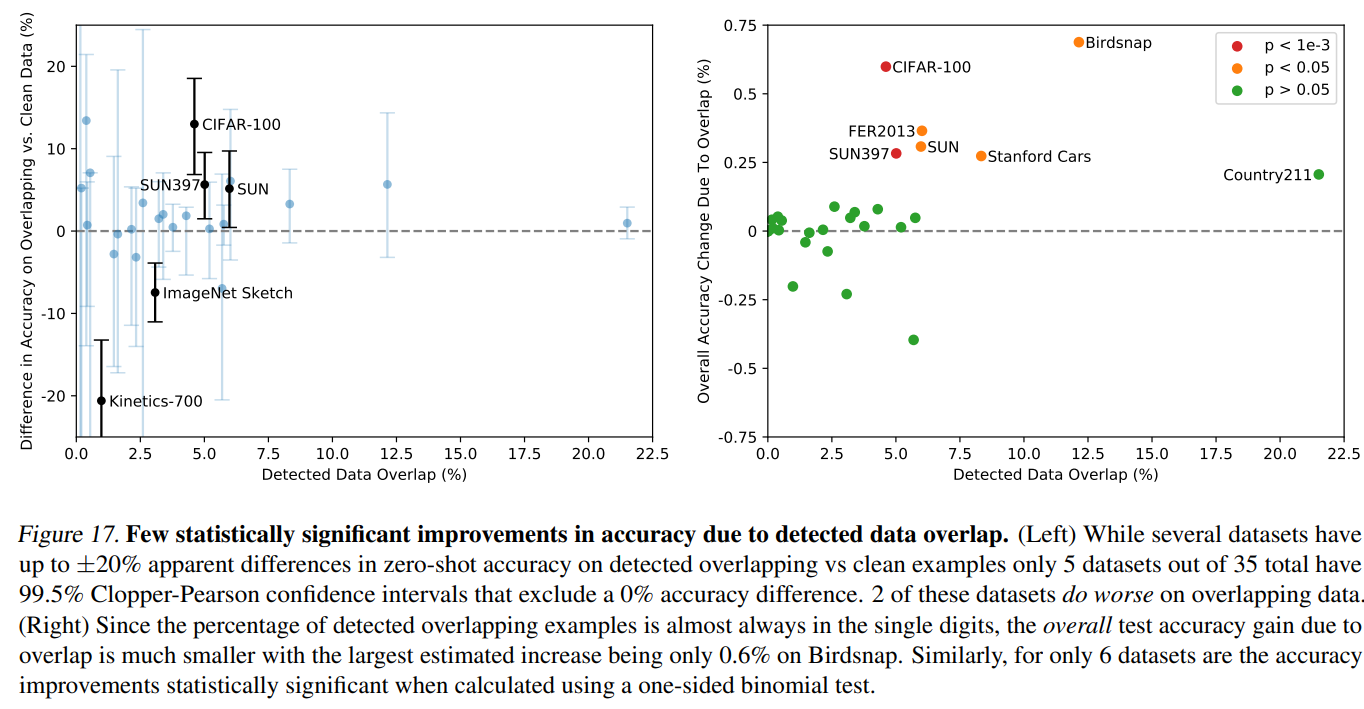
如图文描述,在35个数据集中,仅5个出现统计显著差异(99.5%置信区间),其中2个数据集在重叠数据上表现更差。重叠样本占比通常个位数,最大准确率提升仅0.6%(Birdsnap)单侧二项式检验显示仅6个数据集有显著改进。
说大白话就是,在35场"考试"中:只有5场考试的成绩变化明显(统计显著),其中2场反而考得更差了(重叠数据拖后腿)最好的情况也只是从90分提到90.6分(Birdsnap数据集)。
这些实验结果证明CLIP的高分是"真才实学":不是靠记忆训练数据,其真正掌握了图像理解的通用能力,即使有少量"泄题",对整体结果影响微乎其微,说明CLIP评估中"数据重叠污染"问题被过度担忧。
结论
对于CLIP模型,通俗来说,作者尝试把自然语言处理(NLP)中'海量数据预训练'的成功经验复制到计算机视觉领域,结果发现确实可行。CLIP模型就像个'通才学生',通过上网课(预训练)自学了各种技能。当遇到新任务时,只需要给它'自然语言提示'(就像口头出题),它就能直接作答,不需要额外补课(零样本迁移)。虽然目前还比不上专门为某个任务特训的'尖子生',但当训练规模足够大时,这个'通才'的表现已经能和专业选手掰手腕了。当然,它还有很大的进步空间。"
2 条评论
发表回复
作者
arwin.yu.98@gmail.com





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
代码:https://github.com/OpenAI/CLIP