
1. 摘要
- Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
- GitHub - salesforce/ALBEF: Code for ALBEF: a new vision-language pre-training method
1.1 问题
现有的多模态(图像+文本)模型通常用一个Transformer编码器同时处理图像特征和文本词符。但图像区域和单词之间没有天然的对齐关系,导致模型难以准确学习两者之间的交互。比如,模型可能不知道图片中的"狗"对应文本中的哪个词。
1.2 解决方案:ALBEF
- 先对齐再融合:在融合图像和文本特征之前,先用一种对比损失(contrastive loss)让图像和文本的表征在特征空间中对齐(比如相似的图像和文本在特征空间中靠近)。这相当于让模型先学会"配对",再深入学习细节。
- 无需额外标注:不像一些方法需要人工标注的物体边界框(bounding boxes)或高清图片,ALBEF直接从普通网络数据学习,更实用。
- 抗噪声技巧:动量蒸馏
网络数据(比如图片配错误文字)噪声大,作者提出动量蒸馏:用一个持续更新的“动量模型”(类似老师)生成伪标签,指导学生模型训练,减少噪声干扰。
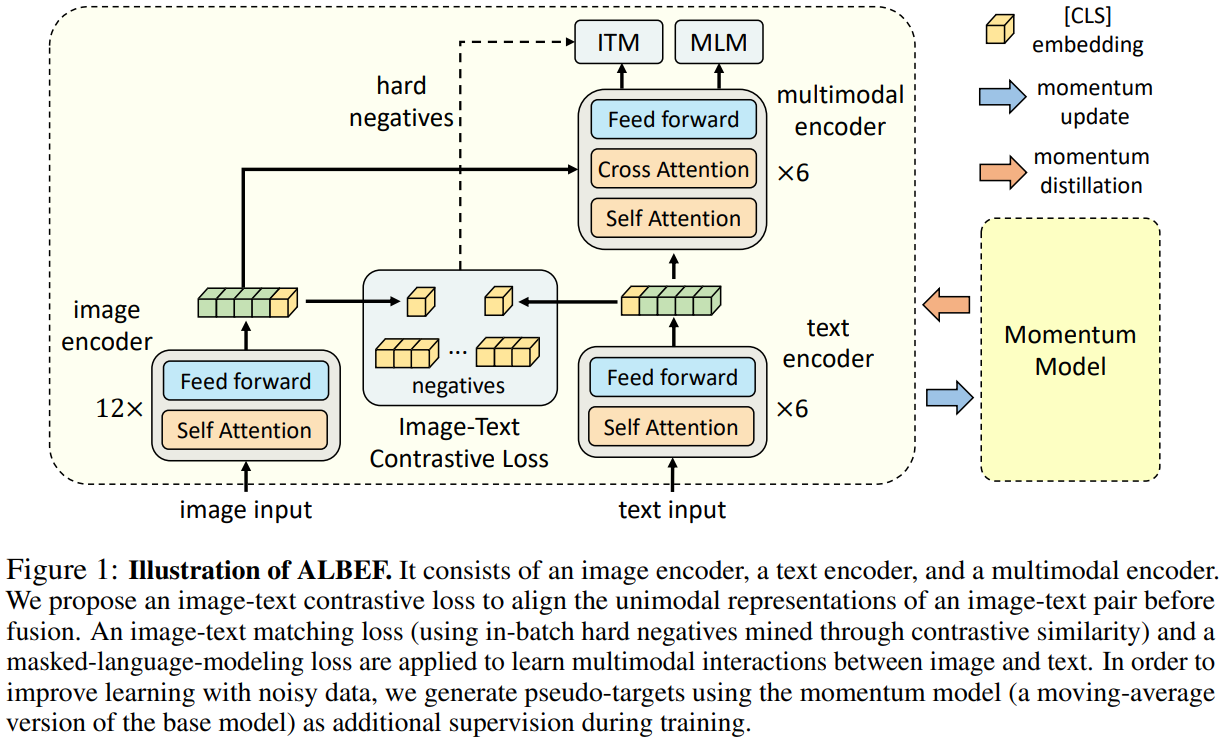
2. 模型架构
ALBEF(Align Before Fusing)的模型结构通过图像编码器、文本编码器和多模态编码器三部分协同工作,实现图像与文本的高效对齐和融合。以下是详细解析:
2.1 各组件细节
(1) 图像编码器
- 结构:采用12层的ViT-B/16(Vision Transformer),预训练于ImageNet-1k。
- 输入处理:
- 图像 I 被分割为若干块(patches),通过线性投影得到嵌入序列,也就是图像提取到的特征向量。
- $v_{cls}$是分类标记(类似BERT的[CLS]),用于汇总全局图像信息。
(2) 文本编码器
- 结构:6层Transformer,初始化自BERT-base的前6层。
- 输入处理:
- 文本 T 被转换为嵌入序列,其中 $w_{c l s}$ 是文本的全局表征。
(3) 多模态编码器
- 结构:6层Transformer,初始化自BERT-base的后6层。
- 融合机制:
- 每层通过交叉注意力(Cross Attention)将图像特征与文本特征交互:
- Query来自文本的token特征,Key和Value来自图像的token特征,实现文本到图像的注意力交互。
- 自注意力(Self Attention)进一步细化文本内部和图像内部的关系。
- 最终输出融合后的多模态表征。
- 每层通过交叉注意力(Cross Attention)将图像特征与文本特征交互:
2.2 关键训练任务与损失函数
(1) 图像-文本对比损失(Image-Text Contrastive Loss,ITC)
- 目的:拉近匹配的图像-文本对的嵌入表示,推开不匹配的对,实现跨模态对齐。
- 实现:
- 分别通过图像编码器和文本编码器提取图像特征 $v$ 和文本特征 $t$ 。
- 计算所有图像-文本对的余弦相似度矩阵 $S$ ,其中 $S_{i, j}$ 表示第 $i$ 个图像和第 $j$ 个文本的相似度。
- 对相似度矩阵分别沿图像和文本维度计算交叉摘损失,优化双向对齐:
$$
\mathcal{L}_{\mathrm{ITC}}=\frac{1}{2}\left(\mathrm{CE}(S, y)+\mathrm{CE}\left(S^{\top}, y\right)\right)
$$
- $y$ 是真实标签(对角线为匹配对),CE 是交叉摘损失。
- 作用:确保模型能够区分正负样本,为后续任务提供良好的初始化特征。
(2) 图像-文本匹配损失(Image-Text Matching Loss,ITM)
- 目的:学习细粒度的图像-文本匹配关系,判断二者是否语义匹配。
- 实现:
- 从批次中采样部分图像-文本对(包括正样本和负样本),负样本通过ITC相似度选择最难样本 (Hard Negative Mining)。
-将图像和文本的融合特征(通过跨模态编码器)输入一个二分类头,预测匹配概率 $p$ :
$$
\mathcal{L}_{\mathrm{ITM}}=\mathrm{BCE}(p, y)
$$
- $y \in{0,1}$ 表示是否匹配, BCE 是二元交叉摘损失。
- 作用:增强模型对跨模态语义一致性的理解,尤其关注难负样本。
(3) 掩码语言建模损失(Masked Language Modeling Loss,MLM)
- 目的:通过文本重建任务,利用图像信息辅助理解被掩码的文本,学习上下文感知的文本表示。
- 实现:
- 随机掩码文本中的部分词(如15%),用[MASK]标记替换。
- 结合图像特征和未被掩码的文本上下文,预测被掩码的词:
$$
\mathcal{L}_{\mathrm{MLM}}=\mathrm{CE}(p_{mask}, y_{mask})
$$
- $y_{\text {mask }}$ 是被掩码词的真实标签。
- 作用:提升模型的多模态推理能力,使文本理解受视觉信息增强。
(4) 动量蒸馏损失(Momentum Distillation)
- 目的:缓解网络数据的噪声问题。
- 方法:
- 使用动量模型(基模型的滑动平均版本)生成伪标签,作为额外监督信号。
- 动量模型更稳定,能提供更可靠的伪目标。
- 动量蒸馏的相关介绍,详见第三章节。
2.3 总结
- 先对齐后融合:通过ITC损失提前对齐单模态特征,简化多模态编码器的学习难度。
- 无需额外标注:仅需普通图文对,不依赖物体检测框或高分辨率图像。
- 抗噪声设计:动量蒸馏利用动量模型的伪标签过滤噪声数据。
通过这种结构,ALBEF在减少计算成本的同时,实现了更高效的跨模态理解。
3. 动量蒸馏(Momentum Distillation, MoD)
动量蒸馏是知识蒸馏的延申,其核心思想是通过一个更强大的“教师模型”指导“学生模型”的训练,从而提升学生模型的性能。ALBEF针对多模态预训练中网络数据噪声大的问题,提出动量蒸馏,以下是详细解析:
3.1 背景与问题
为什么需要动量蒸馏?
- 数据噪声:网络爬取的图文对(Image-Text Pairs)通常存在弱相关性(例如图片是“狗”,文本描述“公园散步”但未明确提到狗)。
- 传统方法的局限:
- ITC(图像-文本对比学习)和MLM(掩码语言建模)使用one-hot标签,会错误惩罚实际合理的负样本(如“狗”的负样本“猫”可能也与图片部分相关)。
- 直接使用噪声数据训练会导致模型学习到错误的关联。
3.2 动量蒸馏的机制
(1) 动量模型(Momentum Model)
- 角色:作为“教师模型”,通过滑动平均(Exponential Moving Average, EMA)更新,比学生模型(基模型)更稳定。
- 更新方式:
教师模型的参数 $\theta_t$ 是学生模型参数 $\theta_s$ 的历史加权平均:
$$
\theta_t \leftarrow \lambda \theta_t+(1-\lambda) \theta_s
$$
其中 $\lambda$ 是动量系数(如 0.995 ),控制教师模型的更新平滑度。
(2) 生成伪标签(Pseudo-Targets)
教师模型对输入数据生成软标签(pseudo-target),而非硬标签(one-hot),从而捕捉更合理的语义关联。
- ITC任务:
教师模型计算图像-文本相似度 $s^{\prime}(I, T)$ ,并生成软目标分布 $q^{i 2 t}$ 和 $q^{t 2 i}$ 。
-例如,图片"狗"可能与文本"宠物"的相似度高于"汽车",但传统one-hot标签会忽略这种梯度关系。
- MLM任务:
教师模型预测被掩码词的分布 $q^{\mathrm{msk}}(I, \hat{T})$ ,允许模型学习多个合理替换词(如"狗"可被"犬科动物"替代)。
对此,原文中的图2举例详细的例子:

图2中的五张图片的原标签(one-hot的硬标签)分别是
- polar bear in the [wild]
- a man [standing] along a road in front of nature in summer
- a [remote] waterfall in the deep woods
- breakdown of the car on the road
- the harbor a small village
对比之下,根据概率分布生成的生成的top-5伪标签(软标签)描述的更加合理,不管是用“zoo”代替“wild”;“walks”代替“standing”还是“small or beautiful”代替remote都更加的合理。
3.3 动量蒸馏的损失函数设计
动量蒸馏的损失在ITC和MLM任务上都有添加:
(1)ITC任务的动量损失($\mathbf{ITC}_{\mathrm{MoD}}$)
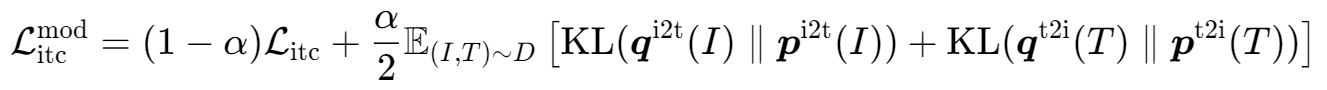
- $\mathcal{L}_{i t c}$ :原始对比损失。
- $KL(q | p)$ :动量蒸馏损失,学生模型预测分布 $p$ 与教师模型伪标签分布 $q$ 的KL散度,迫使学生模仿教师的更合理判断。
- $\alpha$ :权重(默认0.4),平衡两者贡献。
(2)MLM任务的动量损失($\mathbf{M L M}_{\mathrm{MoD}}$ )
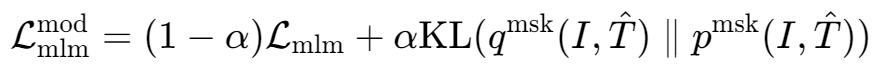
- $\mathcal{L}_{mlm}$ :标准的掩码语言建模损失,权重为(1-α)。
- $KL(q^{msk(I,T̂)} | p^{msk(I,T̂)})$ :动量蒸馏损失,同样是KL散度,这一项鼓励当前模型学习动量模型的预测。
- $\alpha$ :权重(默认0.4),平衡两者贡献。
两个损失函数都采用了原始损失和动量蒸馏损失的加权组合,α=0.4表示更倾向于原始损失(60%)但动量蒸馏也有显著贡献(40%)。动量模型通过EMA更新,比当前模型更稳定,能提供更可靠的监督信号,而且不同于传统使用硬标签(one-hot)的方法,动量模型提供的是概率分布(软目标),能更好地处理数据中的噪声。
值得注意的是,在ALBEF模型中,ITM(Image-Text Matching)任务没有使用动量蒸馏(MoD)。这主要是由于以下几个原因:
1. ITM的任务性质与ITC/MLM不同
- ITM是二分类任务(判断图像-文本对是否匹配),而ITC和MLM是多分类/对比学习任务。
- ITM的标签是硬标签(0/1),而ITC和MLM的伪标签可以是软标签(概率分布),更适合用动量模型生成更平滑的监督信号。
- ITM的噪声问题不如ITC和MLM严重(因为匹配/不匹配的标注相对明确),而ITC和MLM面临更大的语义模糊性(如"部分相关"的负样本或MLM的替代词选择)。
2. ITM的负样本采样依赖ITC的困难样本
- ALBEF的ITM任务使用ITC计算的相似度来筛选困难负样本(hard negatives),而不是随机负样本。
- 如果对ITM也应用动量蒸馏,可能会导致:
- 动量模型的ITC分数影响ITM的样本选择,引入额外的复杂性。
- 破坏原始ITM任务的对抗性学习目标(区分真正的不匹配对和"似是而非"的负样本)。
3. 训练效率与稳定性的权衡
- ITM需要计算图像-文本对的全局交互(通过跨模态编码器),计算成本较高。如果加入动量蒸馏,需要额外维护一个动量跨模态编码器,会增加显存和计算开销。
- ITC和MLM仅需单模态或轻量级跨模态计算,更适合用动量模型生成软目标。
3. Downstream V+L Tasks
ALBEF 在预训练后通过微调(Fine-tuning)可以适配下游任务,如下图中的 视觉问答(VQA) 和 自然语言视觉推理(NLVR²)。
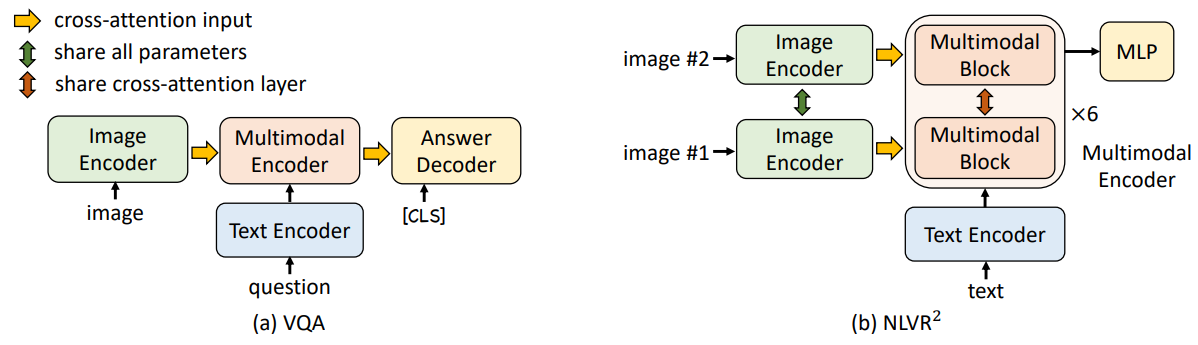
VQA视觉问答任务目标:模型需根据图像和问题生成答案(开放式生成任务,而非传统的多答案分类任务)。
- 输入处理:
- 图像通过 Image Encoder 编码为视觉特征。
- 问题文本通过 Text Encoder 编码为文本特征。
- 多模态融合:
- 视觉和文本特征输入 6层 Multimodal Encoder(共享预训练参数),通过跨注意力机制交互。
- 答案生成:
- 使用 6层 Transformer Decoder(如图
Answer Decoder)以自回归方式生成答案:- 初始输入为
[CLS]标记,结束标记为[SEP]。 - Decoder 通过跨注意力接收多模态编码器的输出(图中
cross-attention input)。
- 初始输入为
- 使用 6层 Transformer Decoder(如图
NLVR自然语言视觉推理目标:判断文本陈述是否与一对图像匹配
- 输入处理:
- 两张图像(Image #1 和 Image #2)分别通过 Image Encoder 编码。
- 文本通过 Text Encoder 编码。
- 多模态编码器扩展:
- 每层 Multimodal Encoder 被复制为 两个连续的 Transformer Block(如图
Multimodal Block → x6):- 每个 Block 包含自注意力层、跨注意力层(
share cross-attention layer)和前馈层。 - 两个 Block 共享预训练权重,且跨注意力的 Key/Value 投影权重一致。
- 每个 Block 包含自注意力层、跨注意力层(
- 两个 Block 分别处理两幅图像的嵌入特征。
- 每层 Multimodal Encoder 被复制为 两个连续的 Transformer Block(如图
- 分类器:
- 在多模态编码器的
[CLS]表示上接 MLP 进行二分类预测。
- 在多模态编码器的
除此之外,常见的V+L任务还有根据图片检索文本(TR),根据文本检索图片(IR),以及SNLI-VE(Visual Entailment)。SNLI-VE视觉蕴含的任务定义为:
给定一个图像(Image)和一段文本(Text),模型需要判断文本与图像之间的关系,分为三类:
中立(Neutral):图像与文本无关或无法确定关系。
蕴含(Entailment):图像中的视觉内容支持文本描述。
矛盾(Contradiction):图像中的视觉内容否定文本描述。
4. 实验
4.1 损失函数的消融实验
表格1展示了从基础任务(MLM+ITM)逐步增加新损失的性能提升,核心结论如下:
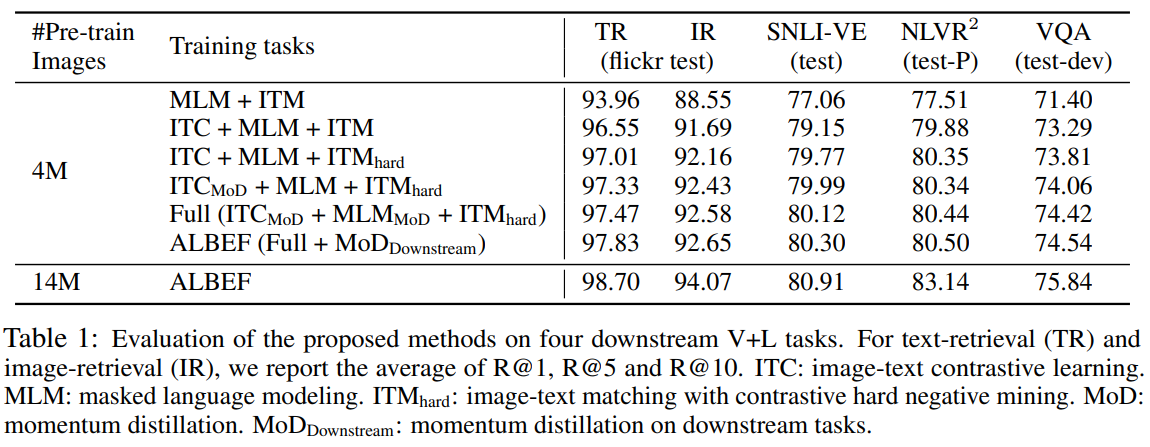
- ITC 的贡献最大:在所有任务中平均提升约 3%,验证了跨模态对比学习对对齐图像-文本全局特征的关键作用。
- 难负样本挖掘(ITM-hard):对复杂任务(如 NLVR)提升更明显,说明难样本有助于模型区分细微语义差异。
- 动量蒸馏(MoD):小幅但稳定提升,尤其在 VQA 上(+0.36),表明伪标签平滑能缓解噪声标注的影响。
数据规模的影响
- 4M → 14M 数据:
- NLVR² 提升最显著(+2.64),因双图像推理任务需要更多样本学习复杂对齐;
- 检索任务(TR/IR)接近饱和,但仍有约 1.5% 提升,说明数据规模对基础对齐任务仍有边际效益。
4.2 预训练效果
根据表格2数据,预训练后的ALBEF 在 Flickr30K 和 MSCOCO 数据集上的图像-文本检索任务中表现出显著优势,尤其在数据效率和性能上超越现有方法。以下是详细结果:
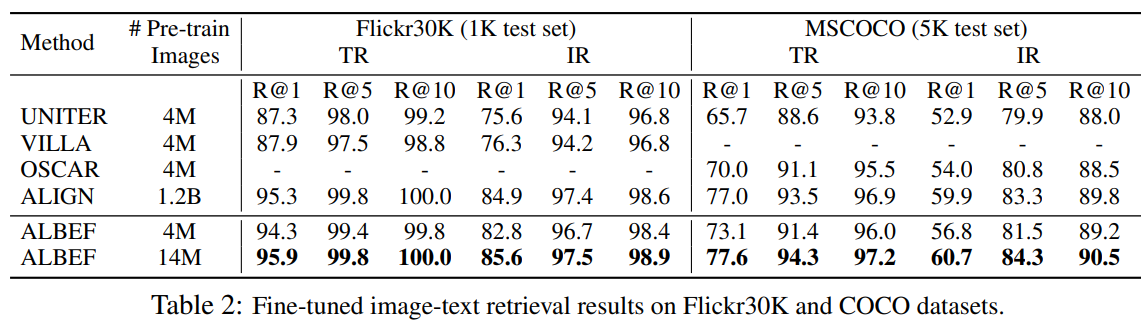
表3展示的零样本的检测能力,ALBEF(14M)的精度要远超CLIP(400M),也就是说,其用更少的数据,训练出来了更高的精度。
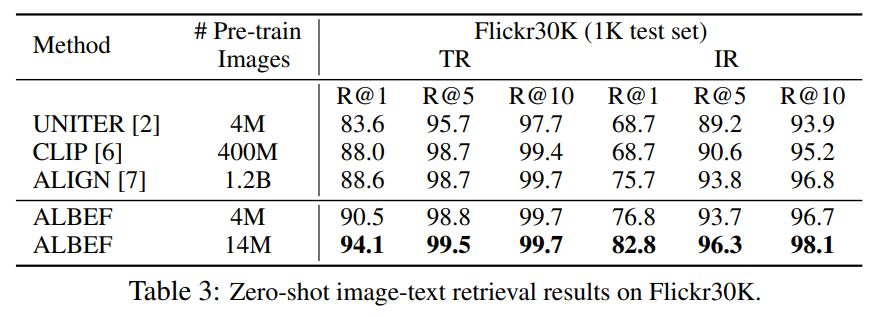
表4是关于多模态下游任务的实验:
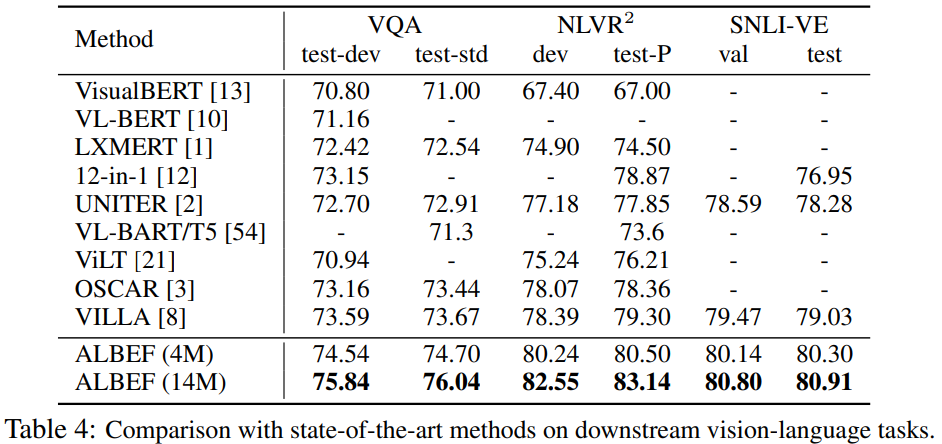
- VQA(视觉问答)ALBEF (14M) 以 75.84 的准确率显著领先,比此前最优方法(VILLA: 73.59)高出 2.25%,即使对比 4M 数据的 ALBEF(74.54)也优于大多数方法。
- NLVR²(视觉推理)ALBEF (14M) 在测试集上达 83.14,较之前 SOTA(VILLA: 79.30)提升 3.84%:
- SNLI-VE(视觉语义推理)ALBEF (14M) 达到 80.80,超越 VILLA(79.47),验证了对细粒度语义对齐的优越性。
5. 总结
ALBEF——一种新的视觉-语言表示学习框架。ALBEF的核心创新在于先通过单模态编码器对齐图像与文本的独立表示(其实就是CLIP),再通过多模态编码器进行融合。从理论和实验上验证了所提出的图像-文本对比学习和动量蒸馏方法的有效性。与现有方法相比,ALBEF在多种视觉-语言(V+L)下游任务中实现了更高的性能与更快的推理速度。
值得一提的是, 由于其高效的模型设计,和联合损失的使用。ALBEF的训练成本相比CLIP小小得多,只用了 8 NVIDIA A100 GPUs,CLIP是64张。这个训练资源在LLM领域以及是非常友好了!
作者
arwin.yu.98@gmail.com





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1 评论