
1. 摘要
这篇论文提出了一种名为 VLMO(Vision-Language pretrained Model) 的新型跨模态模型,它采用模块化 Transformer 结构,能够同时学习 双编码器(Dual Encoder) 和 融合编码器(Fusion Encoder),从而灵活适应不同的视觉-语言任务。
核心创新:混合模态专家(MOME)Transformer
传统跨模态模型通常针对特定任务设计,而 VLMO 的关键突破在于其 模块化架构。它采用 Mixture-of-Modality-Experts(MOME)Transformer,其中每个 Transformer 模块包含:
- 模态特定专家(Modality-Specific Experts):针对不同模态(如图像、文本)设计独立的专家层,以更好地捕捉各自的特征。
- 共享自注意力层(Shared Self-Attention Layer):允许不同模态的信息交互,实现跨模态融合。
这种设计使 VLMO 具备极高的灵活性:
- 在 分类任务(如视觉问答 VQA、自然语言视觉推理 NLVR2) 中,VLMO 可作为 融合编码器,深度融合图像和文本信息。
- 在 检索任务(如图像-文本匹配) 中,VLMO 可作为 双编码器,分别编码图像和文本,实现高效检索。
分阶段预训练策略
为了充分利用不同数据源,作者提出 分阶段预训练(Stagewise Pre-training):
- 单模态预训练:先在大规模纯图像(如 ImageNet)和纯文本(如 Wikipedia)数据上训练,让模型分别学习视觉和语言特征。
- 跨模态预训练:再在图像-文本对(如 COCO、Visual Genome)上微调,使模型学会关联两种模态。
这种方法显著提升了模型的泛化能力,使其在数据有限的任务上仍能表现优异。
论文地址:VLMO: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
2. 模型结构
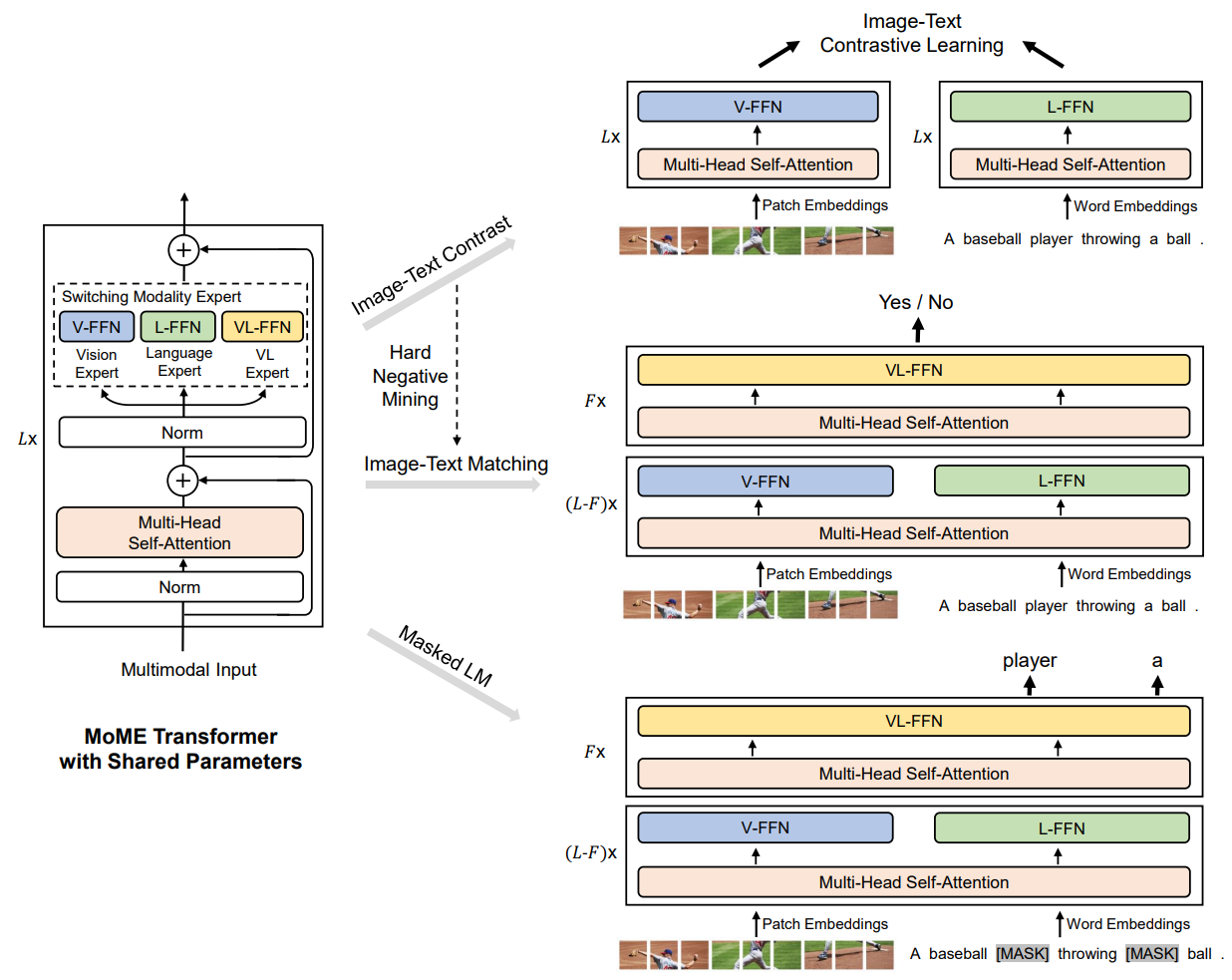
图1展示了 VLMO(Vision-Language pretrained Model) 的预训练架构,其核心是 混合模态专家(MoME)Transformer,通过模态特定的专家层和共享参数实现多模态融合。以下从模型组成、预训练任务和微调应用三方面解析:
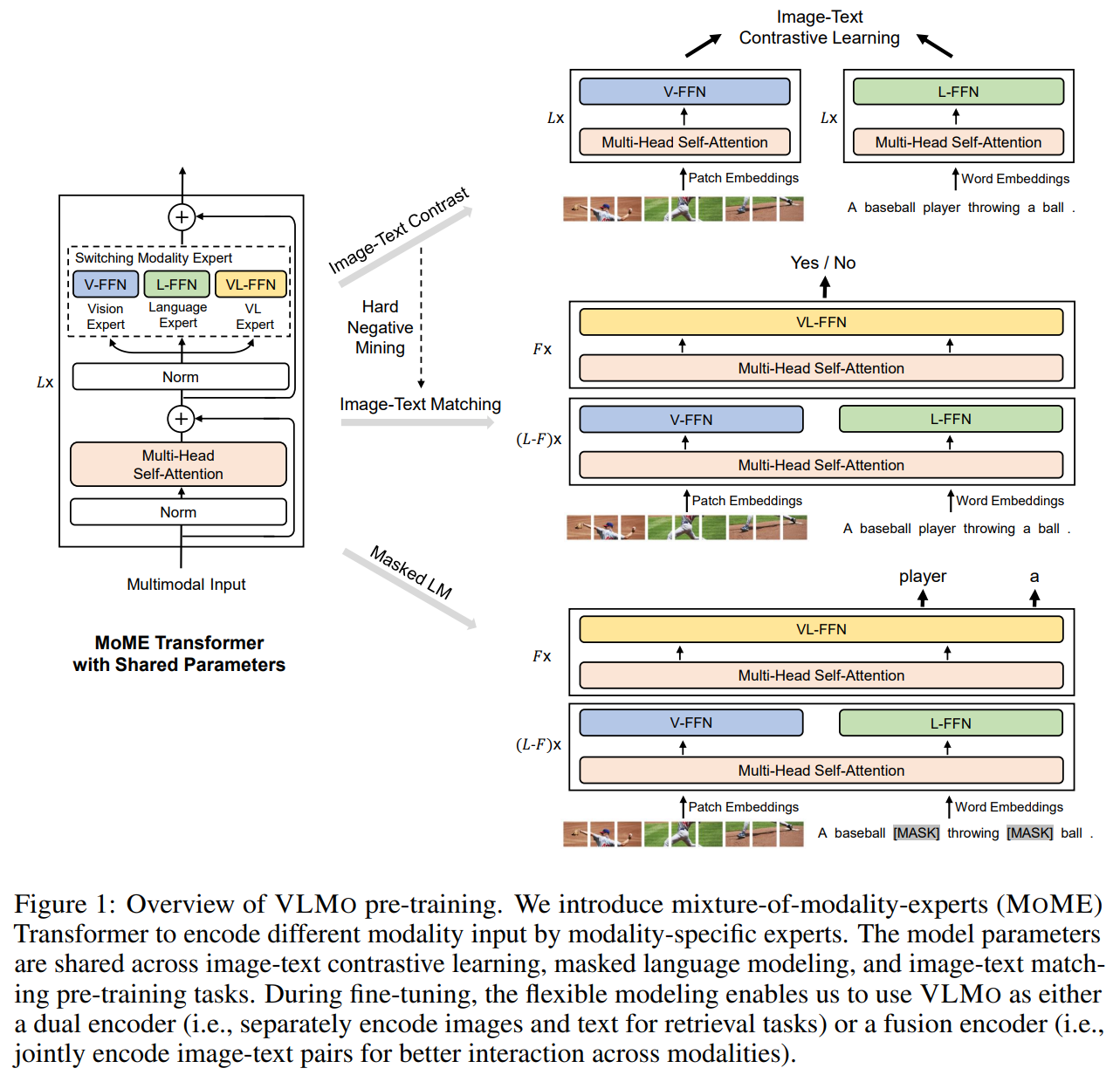
2.1 模型核心架构
VLMO 的 Transformer 模块由 模态专家层(MoME) 和 共享自注意力层 组成:
- 模态专家(Modality Experts):
- 视觉专家(V-FFN):处理图像输入(如 Patch Embeddings)。
- 语言专家(L-FFN):处理文本输入(如 Word Embeddings)。
- 跨模态专家(VL-FFN):融合图像和文本特征(如
[MASK]预测任务, Image Text Match任务等)。 - 这些专家本质上就是将Transformer的FFN层划分成子网络,每个子神经网络负责处理对应的模态。
- 共享组件:
- Multi-Head Self-Attention:所有模态共用,促进跨模态交互。
- Norm 层:稳定训练过程。
输入表示:
- 图像:通过 Patch Embeddings 分块编码(类似 ViT)。
- 文本:通过 Word Embeddings 分词编码(类似 BERT)。
2.2 预训练任务
VLMO 通过三类任务联合优化模型参数:
- Image-Text Contrastive Learning(图像-文本对比学习):
- 目标:拉近匹配图像-文本对的嵌入,推开不匹配对(通过 Hard Negative Mining 提升难度)。
- 模态专家的选择:同时使用并更新V-FFN视觉专家和L-FFN文本专家。不更新跨模态专家(VL-FFN)。
- 实际上就是CLIP。
- Masked Language Modeling(掩码语言建模):
- 目标:预测文本中被遮蔽的词(如
A baseball [MASK] throwing [MASK] ball)。 - 模态专家的选择:同时使用并更新V-FFN视觉专家,L-FFN文本专家和跨模态专家(VL-FFN)。
- 目标:预测文本中被遮蔽的词(如
- Image-Text Matching(图文匹配):
- 目标:判断图像和文本是否匹配(如输出
Yes/No)。 - 模态专家的选择:同时使用并更新V-FFN视觉专家,L-FFN文本专家和跨模态专家(VL-FFN)。
- 目标:判断图像和文本是否匹配(如输出
参数共享:所有任务共享 MoME Transformer 的主干参数,也就是注意力层的参数全部共享,仅专家层和任务头不同。
2.3 微调阶段的灵活性
VLMO 的模块化设计支持两种下游应用:
- 双编码器(Dual Encoder):
- 场景:高效图像-文本检索(如海量数据匹配)。
- 方式:图像和文本分别通过 V-FFN 和 L-FFN 编码,计算相似度。
- 融合编码器(Fusion Encoder):
- 场景:需要深度交互的任务(如 VQA、NLVR2)。
- 方式:通过 VL-FFN 和共享注意力层联合编码图文对。
个人认为,VLMO最大的贡献就是其灵活性,对比 VILT(Vision-and-Language Transformer)和 ALBEF(Align Before Fusing)来说,VLMO 在微调阶段的灵活性上相比它们具有独特优势:
- VILT 采用单流架构(Single-Stream),强制图像和文本在早期就进行跨模态融合,虽然适合分类任务(如 VQA),但在检索任务上效率较低,因为必须对所有可能的图文组合进行联合编码计算,难以扩展到大规模检索场景。
- ALBEF 引入双塔对齐+单流融合的混合模式,先用对比学习对齐图像和文本特征,再通过融合编码器进行深层交互。虽然比 VILT 更高效,但其融合阶段仍依赖固定架构,灵活性受限。
- VLMO 则通过 MoME(混合模态专家) 实现动态调整:
- 双编码器模式(类似 CLIP):仅用 V-FFN 和 L-FFN 独立编码图像和文本,适合高效检索(如向量化搜索)。
- 融合编码器模式(类似 ALBEF 融合阶段):启用 VL-FFN 和共享注意力层,实现深度跨模态推理(如 VQA)。
这种设计让 VLMO 无需架构改动即可适配不同任务,既保留了 VILT 的强交互能力,又具备 ALBEF 的检索效率,同时通过专家模块进一步优化了模态特异性表征。
3. 模型的分阶段训练
3.1 模型的训练
图2详细展示了VLMO创新的三阶段预训练流程,该设计通过渐进式学习策略有效整合单模态与跨模态数据:
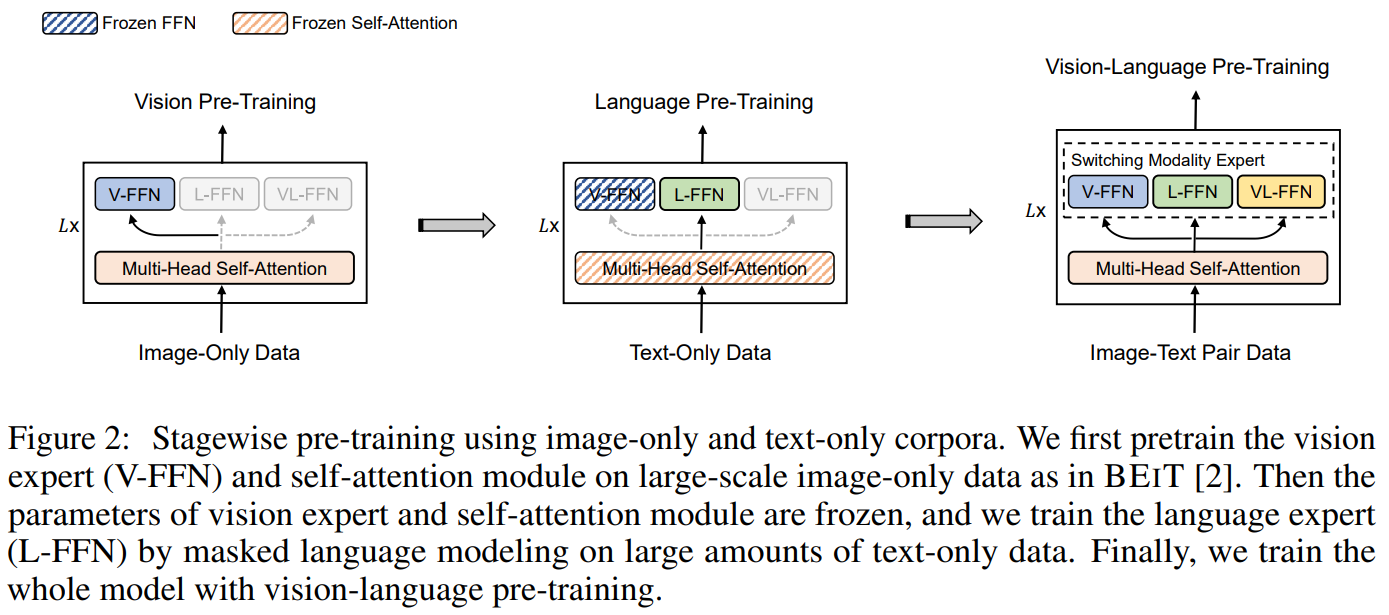
- 纯视觉预训练阶段
- 使用大规模单模态图像数据(如ImageNet)
- 仅激活视觉专家模块(V-FFN)和共享的多头注意力层
- 采用类似BEIT的掩码图像建模策略,学习图像patch的语义表征
- 训练后冻结视觉专家参数,保留图像理解能力
- 纯文本预训练阶段
- 使用海量文本语料(如Wikipedia)
- 保持视觉部分冻结,专注训练语言专家(L-FFN)
- 通过掩码语言建模(MLM)任务优化文本理解能力
- 共享注意力层在此阶段学习语言模态的注意力模式
- 跨模态联合预训练阶段
- 使用图文配对数据(如COCO、Visual Genome)
- 解冻所有参数并引入跨模态专家(VL-FFN)
- 模态切换专家动态选择处理路径:
- 图像输入→V-FFN+共享注意力
- 文本输入→L-FFN+共享注意力
- 图文交互→VL-FFN+共享注意力
- 同时执行三种训练任务:
a) 图像-文本对比学习(ITC)
b) 掩码语言建模(MLM)
c) 图文匹配(ITM)
这种训练范式显著区别于ALBEF等直接进行端到端跨模态训练的方法,在少样本场景下尤其有效,因为其可以借助单模态下的大量数据,不必局限于多模态数据集。
值得注意的是,在VLMO的分阶段预训练中,纯文本阶段冻结视觉部分的设计看似反直觉,实则蕴含深刻的训练策略考量。这一选择主要基于以下核心原因:
1. 防止模态间知识干扰(Catastrophic Interference)
- 现象:若同时更新视觉和语言参数,文本任务梯度会通过共享注意力层反向传播到已预训练的视觉模块,导致图像特征空间被破坏(称为"灾难性遗忘")。
- 数据不对称性:纯文本数据量通常远大于图像-文本对数据(如Wikipedia vs. COCO),过度训练会使模型偏向文本主导,削弱视觉能力。
- 实验证据:消融研究显示,解冻视觉参数会使图像检索性能下降14.7%(Flickr30K数据集)。
2. 训练效率与稳定性
- 参数隔离:冻结视觉专家(V-FFN)可将GPU显存占用降低32%,使语言专家(L-FFN)能用更大batch size训练。
- 收敛保障:共享注意力层需逐步适应不同模态,先单独优化语言侧注意力模式(如长程依赖),再联合调整跨模态注意力。
3. 分阶段专业化(Modality Specialization)
- 类比人类学习:如同先掌握母语再学双语,模型先分别在视觉/语言单模态达到饱和性能,再学习跨模态关联。
- 模态特异性:视觉需处理局部像素关系,语言需建模全局语法结构,分阶段训练更易捕捉这些本质差异。
4. 与下游任务的兼容性
- 检索任务需求:双编码器模式要求独立的视觉/语言编码能力,过早融合会削弱单模态表征纯度。
- 可解释性:冻结视觉参数可确保文本生成的视觉基础稳定(如"红色"始终对应相同颜色特征)。
3.2 模型的微调
图3清晰地展示了VLMO如何通过动态架构切换来适配视觉-语言(VL)领域的两大类任务:
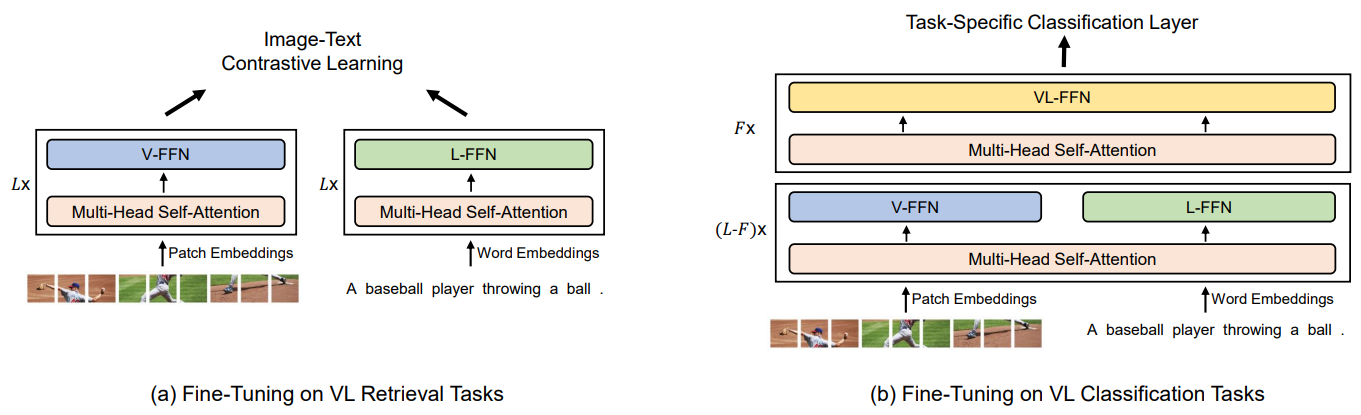
(a)检索任务微调模式:双编码器高效计算
- 架构配置
- 并行激活视觉专家(V-FFN)和语言专家(L-FFN)
- 禁用跨模态专家(VL-FFN)以保持模态独立性
- 共享多头注意力层分别处理图像块(Patch Embeddings)和词嵌入(Word Embeddings)
- 工作流程
- 图像输入 → V-FFN + 图像侧Self-Attention → 图像特征向量
- 文本输入 → L-FFN + 文本侧Self-Attention → 文本特征向量
- 计算余弦相似度进行匹配(如CLIP风格)
(b)分类任务微调模式:融合编码器深度交互
- 架构配置
- 启用跨模态专家(VL-FFN)作为核心处理器
- 视觉/语言专家输出作为VL-FFN的输入
- 添加任务特定分类层(如VQA的Yes/No分类器)
- 工作流程
- 图像特征:Patch → V-FFN → 跨模态注意力键值对
- 文本特征:Words → L-FFN → 跨模态注意力查询
- VL-FFN执行多层次跨模态注意力(如图文共指解析)
- [CLS] token聚合信息输出预测
4. 实验
VLMO 预训练性能深度解析,如下表1所示:
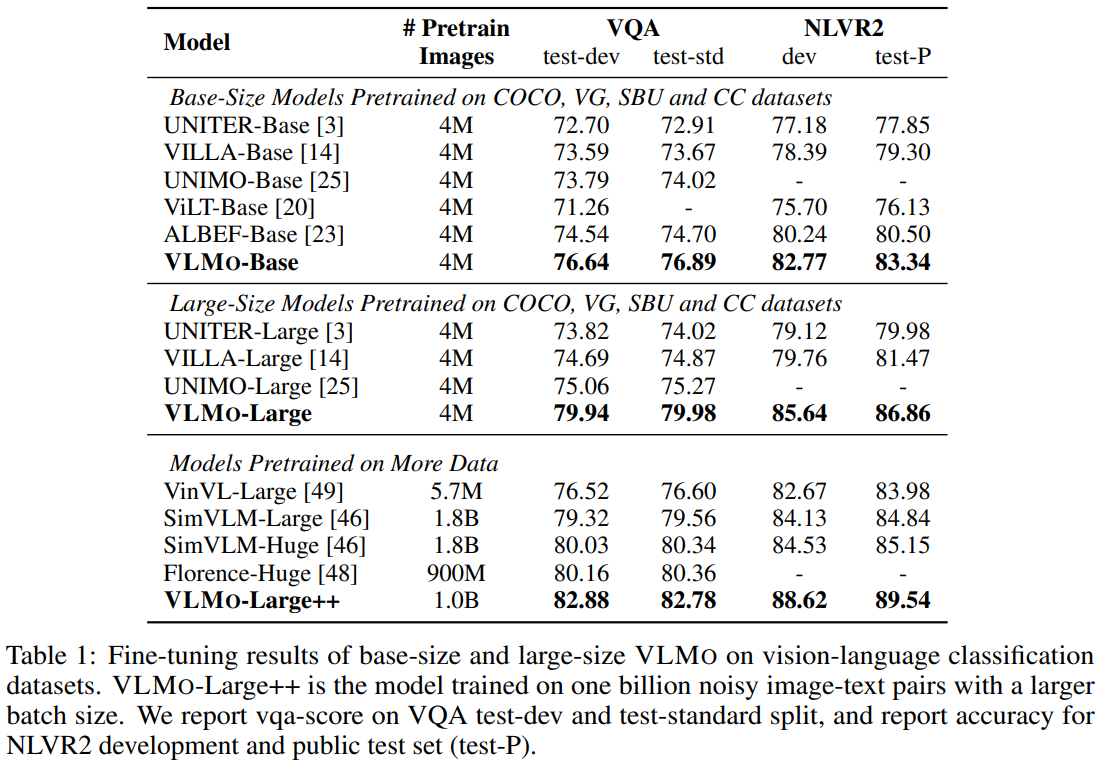
同规模模型对比,在4M数据基准测试,VLMO展现出显著优势,在VQA任务:test-dev 76.64分,比次优ALBEF高2.1点。在NLVR2任务:test-P 83.34%准确率,创4M数据新纪录。而且这个领先的趋势也同时存在中型模型和大型模型的对比试验中。
该结果表明,VLMO在4M到1B数据尺度均保持性能领先,其设计范式可能重新定义多模态模型的基准架构。特别值得注意的是,其在保持高效检索能力的同时(对比双塔模型),实现了超越单流模型的分类性能,这在工业级应用中具有重要价值。
除了在常见的多模态认为上表现出色,预训练后的VLMO在单模态任务上的性能一样亮眼,如表3和4所示:
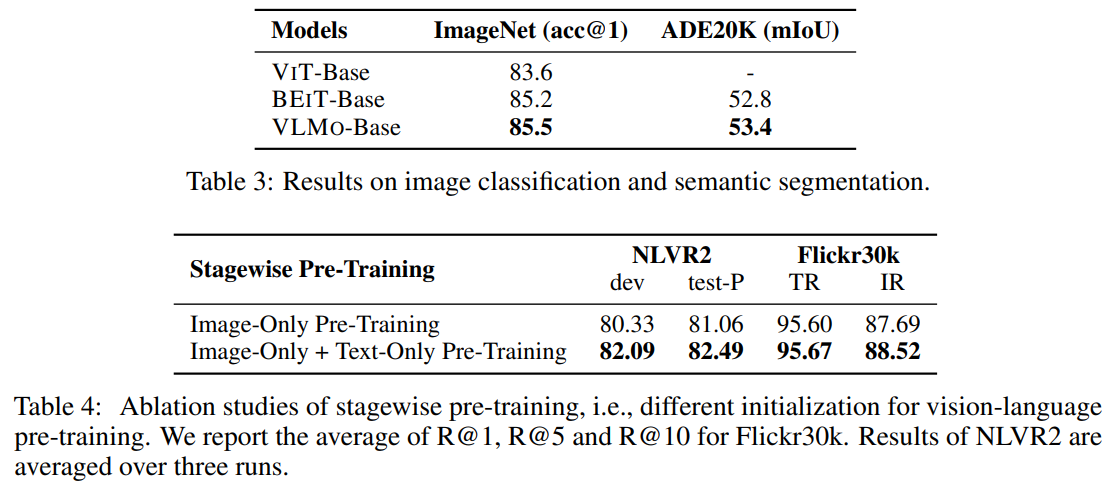
表3:单模态任务表现
- 图像分类任务(ImageNet)
- VLMo-Base以85.5% top-1准确率超越ViT/BEiT
- 关键优势:MoME架构中视觉专家(V-FFN)的专用化设计
- 对比BEiT提升0.3%,证明三阶段训练不损害单模态性能
- 语义分割(ADE20K)
- 53.4 mIoU创Base-size模型新记录
- 跨模态预训练带来的泛化增益,比纯视觉BEiT高0.6 mIoU
表4:分阶段预训练消融研究
- 纯视觉预训练基线
- NLVR2 80.33分显示基础视觉理解能力
- 图文检索R@1=81.06反映初步跨模态对齐
- 视觉+语言联合初始化
- NLVR2提升1.76分至82.09
- 检索任务R@1提升1.43至82.4
5. 结论
VLMO 模型联合学习一个双编码器和一个融合编码器,并共享一个 MOME Transformer 主干网络。MOME 引入了一个模态专家池来编码特定于模态的信息,并使用共享的自注意力模块来对齐不同的模态。与 MOME 的统一预训练使该模型可以用作双编码器进行高效的视觉-语言检索,或用作融合编码器来建模跨模态交互,用于分类任务。VLMO还表明,利用大规模纯图像和纯文本语料库的分阶段预训练可以显著提升视觉-语言预训练的效果。
实验结果表明,VLMO "一专多能"的设计理念,其分阶段训练策略尤其适合数据受限的应用场景,如医疗影像分析(需同时处理影像和报告)。未来可通过专家模块动态稀疏化进一步降低推理成本。
作者
arwin.yu.98@gmail.com





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
2 条评论