
1. 介绍
视觉-语言预训练近期在各种多模态下游任务中取得了巨大成功。然而现有方法存在两大局限性:
(1)模型层面:现有方法要么采用基于编码器的模型,要么采用编码器-解码器模型。但基于编码器的模型难以直接迁移到文本生成任务(如图像描述),而编码器-解码器模型尚未成功应用于图文检索任务。
(2)数据层面:最先进方法(如CLIP、ALBEF、SimVLM)主要使用网络收集的图文对进行预训练。尽管扩大数据集能提升性能,但本文证明网络文本的噪声特性不利于视觉-语言学习。
为此,BLIP提出(自举式语言-图像预训练框架),通过模型与数据层面的双重创新实现统一的理解与生成能力:
(a) 多模态混合编解码器(MED):新型架构支持多任务预训练与灵活迁移学习。MED可切换为单模态编码器、基于图像的文本编码器或解码器,通过图像-文本对比学习、匹配和条件语言建模三目标联合预训练。
(b) 字幕生成与过滤(CapFilt):从噪声数据中学习的新方法。将预训练MED微调为两个模块:为网络图像生成合成字幕的生成器(Cap),以及过滤原始网络文本与合成文本噪声的过滤器(Filt)。
图1展示使用字幕生成器(Cap)为网络图像生成合成字幕,并通过过滤器(Filt)去除噪声字幕的流程。

示例图片的原标签为"日落公园蓝天空面包店",其图文的相关性并不强,因此过滤器Filt会将其打上不好的标签;同时生成器Cap尝试为其生成新标签"奶油巧克力蛋糕顶部撒有巧克力糖粒"并再次通过过滤器Flit进行检测。
关键发现:
• 字幕生成与过滤协同作用,通过自举字幕显著提升下游任务性能,且字幕多样性越高收益越大
• BLIP在图文检索、图像描述、视觉问答、推理及对话等任务上达到SOTA,在零样本迁移至视频-语言任务(文本-视频检索、视频问答)时同样创下最佳性能
2. 模型与训练
BLIP(Bootstrapping Language-Image Pre-training)是一种统一的多模态视觉-语言预训练模型,其核心创新在于提出了多模态混合编码器-解码器(Multimodal Mixture of Encoder-Decoder, MED)架构,能够通过共享参数实现三种不同的功能模式。以下是对其模型结构的详细展开:
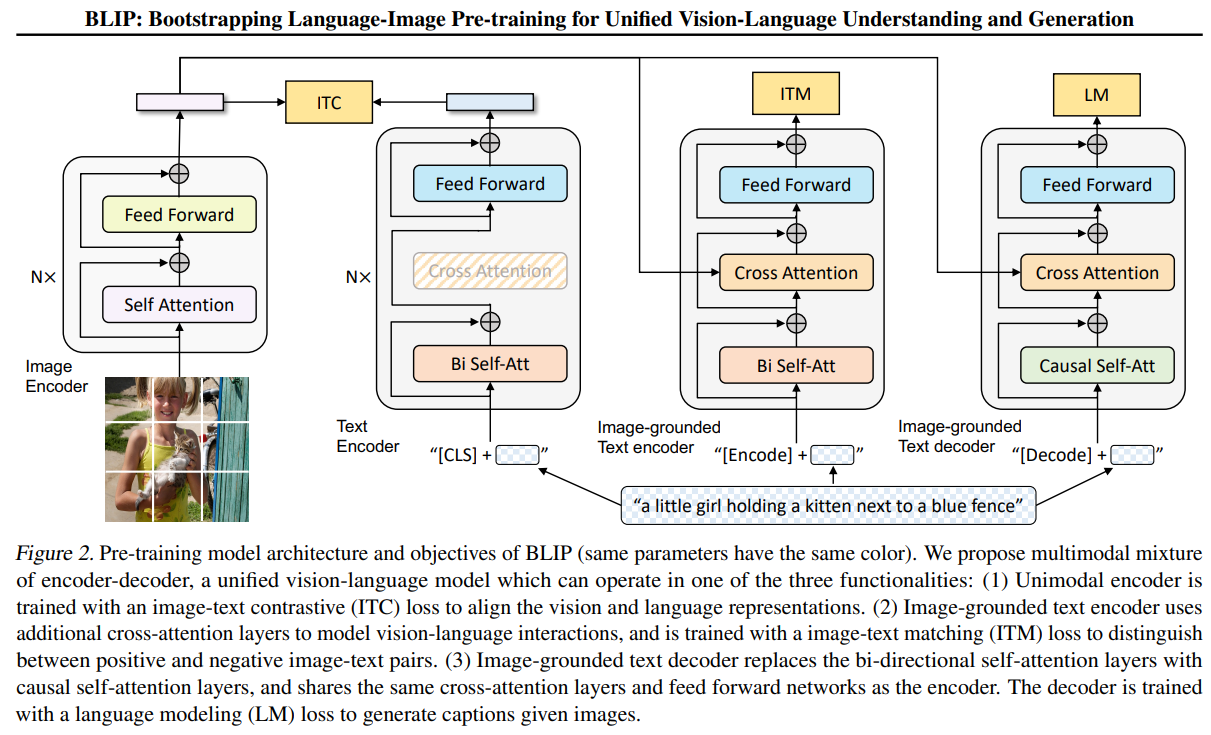
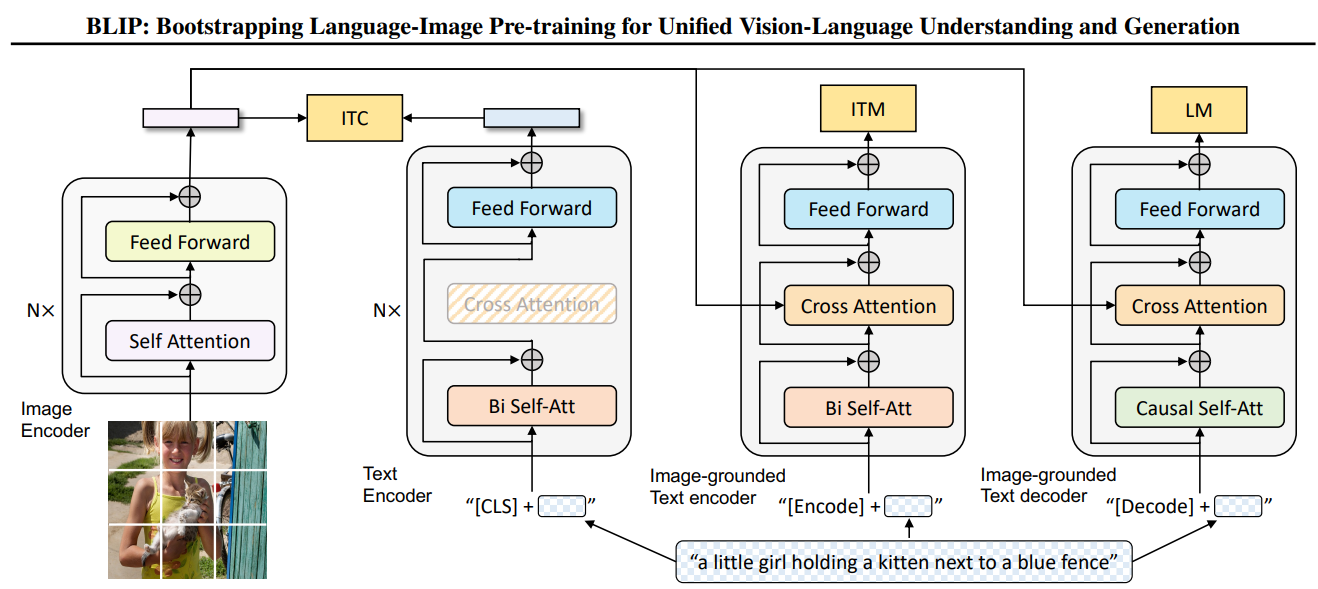
整体架构设计
BLIP的MED架构由三个关键组件构成,共享部分参数以提高效率:
- 单模态编码器(Unimodal Encoder)
- 基于图像的文本编码器(Image-grounded Text Encoder)
- 基于图像的文本解码器(Image-grounded Text Decoder)
所有组件共享相同的视觉编码器(Vision Transformer, ViT)和部分文本处理层,但通过不同的注意力机制和训练目标实现多功能性。
2.1 视觉编码器(Visual Encoder)
- 基础结构:采用ViT(Vision Transformer)对输入图像进行编码。
- 输入图像被分割为固定大小的patch(如16×16),线性投影为patch embeddings。
- 添加[CLS] token作为全局图像表示的聚合标志。
- 通过多层Transformer块(如12层)提取视觉特征,输出视觉嵌入序列 V。
2.2 文本编码器(Text Encoder)
(1) 单模态文本编码器
- 功能:仅处理文本输入(不涉及视觉信息),用于图像-文本对比学习(ITC)。
- 结构:
- 输入文本通过词嵌入层转换为token序列,添加[CLS]和[SEP]标记。
- 使用双向Transformer(如BERT结构)编码文本,输出文本嵌入 T 。
- [CLS] token的嵌入用于计算图像-文本相似度。
(2) 基于图像的文本编码器(Image-grounded Text Encoder)
- 功能:融合视觉和语言信息,用于图像-文本匹配(ITM)。
- 结构改进:
- 在单模态文本编码器基础上,插入跨注意力层(Cross-Attention),使文本token能够关注视觉特征 V。
- 具体来说,跨注意力层的Query来自文本,Key和Value来自视觉编码器的输出。
- 保留双向自注意力层,实现文本与图像的细粒度交互。
2.3 文本解码器(Text Decoder)
- 功能:以自回归方式生成图像描述(Language Modeling, LM)。
- 结构改进:
- 将文本编码器的双向自注意力层替换为因果自注意力层(Causal Self-Attention),Causal Self-Attention(因果自注意力)是自注意力机制(Self-Attention)的一种变体,主要用于处理序列数据中的因果约束(Causal Constraint),即确保模型在生成输出时只能访问当前时刻及之前的输入信息,而不能“偷看”未来信息。这种机制在自回归模型(如GPT)中至关重要。
- 共享跨注意力层和FFN:与Image-grounded Text Encoder共用跨注意力层和前馈网络,减少参数量。
- 在训练时,使用前缀语言模型(Prefix LM)目标,以图像特征为条件生成文本。
2.4 训练目标与损失函数
BLIP通过三种损失函数联合优化模型:
(1) 图像-文本对比损失(ITC)
- 目标:对齐图像和文本的表示空间。
- 实现方式:
- 计算图像[CLS] token vclsvcls 和文本[CLS] token tclstcls 的余弦相似度。
- 使用InfoNCE损失,在一个batch内区分正负样本对。
(2) 图像-文本匹配损失(ITM)
- 目标:学习图像-文本对的细粒度匹配关系。
- 实现方式:
- 通过Image-grounded Text Encoder计算匹配分数(二分类)。
- 使用硬负样本挖掘(Hard Negative Mining)提升难样本区分能力。
(3) 语言建模损失(LM)
- 目标:生成与图像相关的自然语言描述。
- 实现方式:
- 基于交叉熵损失,以图像特征为条件自回归预测下一个token。
- 解码器在训练时使用教师强制(Teacher Forcing)。
实际上,单看模型结构和训练,BLIP其实并没有太大的创新,结构上与ALBEF很像,训练上也是视觉-语言多模态算法常用的训练损失。BLIP模型的主要贡献其实是自举式的数据增强,论文中成为CapFilt。
3. CapFilt
CapFilt(Captioning and Filtering)是BLIP(Bootstrapping Language-Image Pre-training)框架中提出的创新性方法,旨在提升视觉-语言预训练数据质量。下面我将从多个维度详细解析这一机制。
3.1 CapFilt的设计背景与动机
当前视觉-语言预训练面临的核心问题是:高质量人工标注数据稀缺而网络数据噪声大。具体表现为:
- 人工标注数据(如COCO):质量高但规模有限(约10万量级)
- 网络爬取数据(如Conceptual Captions):规模大(千万级)但文本噪声严重(与图像内容不匹配)
CapFilt的创新在于通过模型自身能力提升数据质量,实现"数据自举"(Bootstrapping),而不是简单地混合或丢弃数据。
3.2 CapFilt的双模块架构
CapFilt由两个核心组件构成,二者都源自同一预训练的 BLIP 模型,如下图所示:

生成器Captioner是一个 image-grounded text decoder,通过掩码任务LM进行的预训练,即BILP中的下图部分:
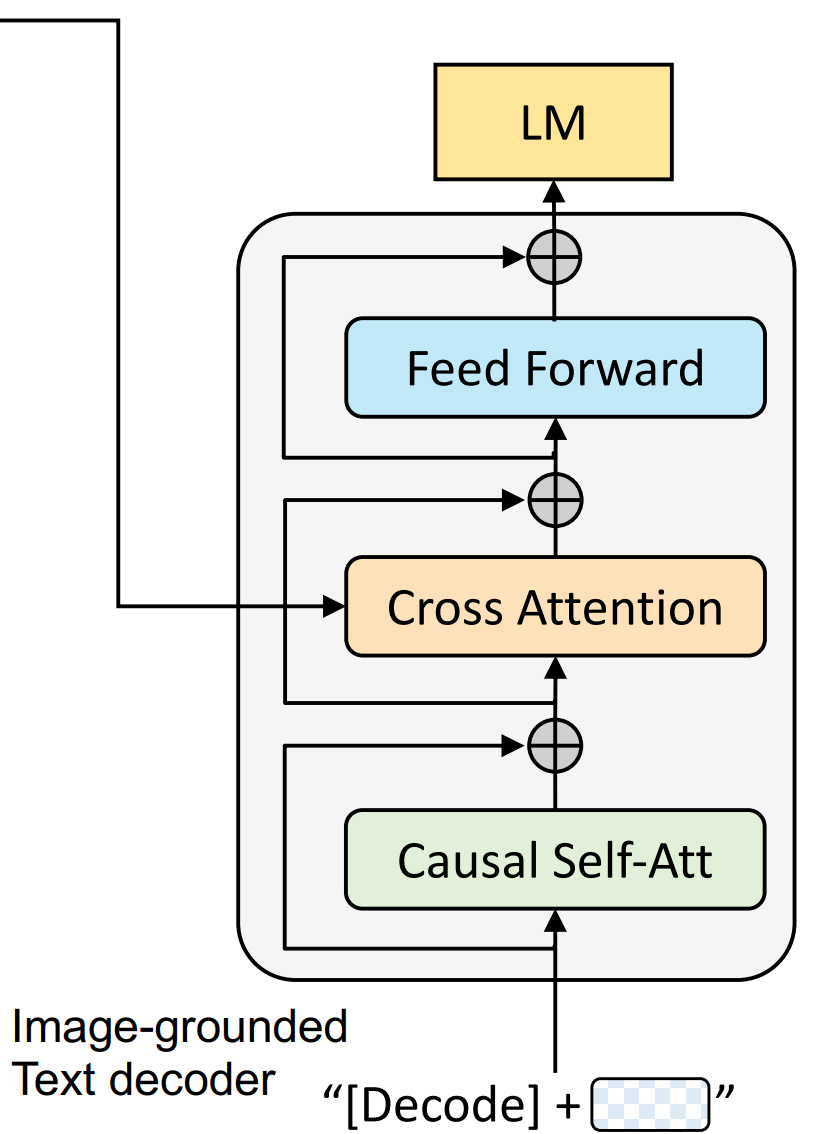
生成器Filter是一个 image-grounded text encoder,通过对比训练ITC和匹配任务ITM进行的预训练,即BILP中的下图部分:

初始化阶段,使用基础BLIP模型在原始混合数据(人工+网络数据)上预训练,从此预训练模型派生出两个分支:Captioner和Filter。
接下来,Captioner和Filter需要在 COCO 数据集上分别进行微调,提进一步提升其生成和判别的性能,整体微调过程十分轻量。
在使用Captioner和Filter时,首先对每张网络图像Iw,Filter判别其与对应文本的匹配度,高于设定阈值则视为优质样本进行保留,即图3中的{Iw,Tw}。同时,对每张网络图像Iw,Captioner也会为其生成对应的文本描述Ts,{Iw,Ts}也会经过Filter的判别,高于设定阈值的优质样本对称为{Iw,Ts}。最后,在加上预训练的CoCo数据集{Iw,Th},组成了最终BILP模型的训练集。
论文中,作者也可视化了Tw和Ts,即网络样本中匹配度不高的图文对{Iw,Tw},和CapFilt生成的图文对{Iw,Ts},如下图所示:

CapFilt通过Captioner生成合成描述扩展高质量数据规模,同时通过Filter严格过滤保证数据纯净度。进一步的,BILP通过训练不断变强,基于BLIP的Captioner和Filter也会不断变强,形成正向反馈循环。这种数据自举范式为解决AI中的数据瓶颈问题提供了新思路。
4. 实验
4.1 CapFilt的消融实验
表格1对比了不同预训练数据集配置和不同视觉骨干网络下CapFilt的性能表现,主要评估了图像-文本检索和图像描述生成两大任务。如下所示:
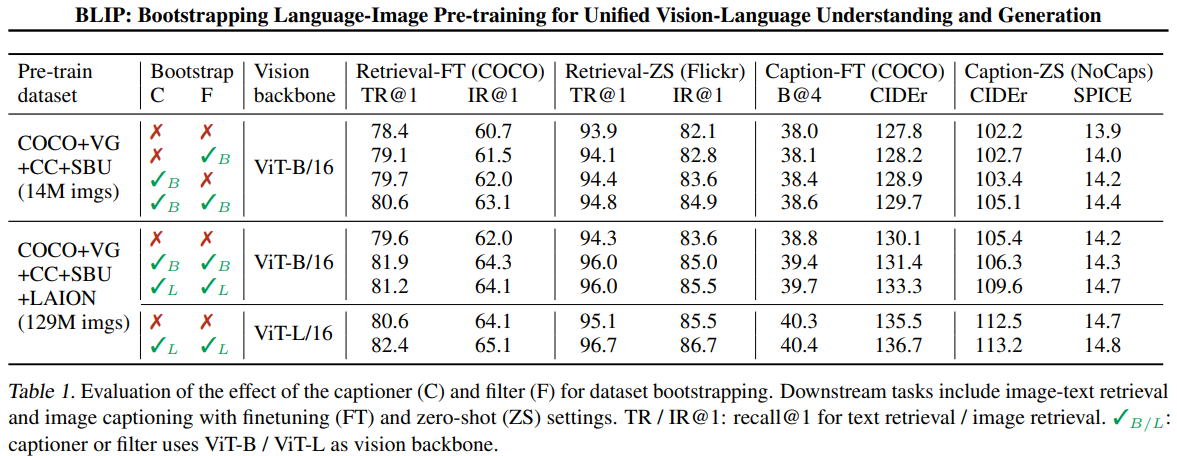
在表1中,C表示captioner,F表示Filter,下游任务包括带有微调 (FT) 和零样本 (ZS)的图文检索任务和文字生成任务。
根据结果,同时使用C和F的模型,在检索任务和生成任务上都达到了最好的效果。而且,当训练集扩大(14M-->129M)后,其精度的提升更加明显。这些实验结果充分证明了CapFilt在提升视觉-语言预训练效果方面的有效性,特别是在数据质量和模型泛化能力方面的显著改善。
4.2 BLIP与前沿方法的跨模态检索性能对比分析
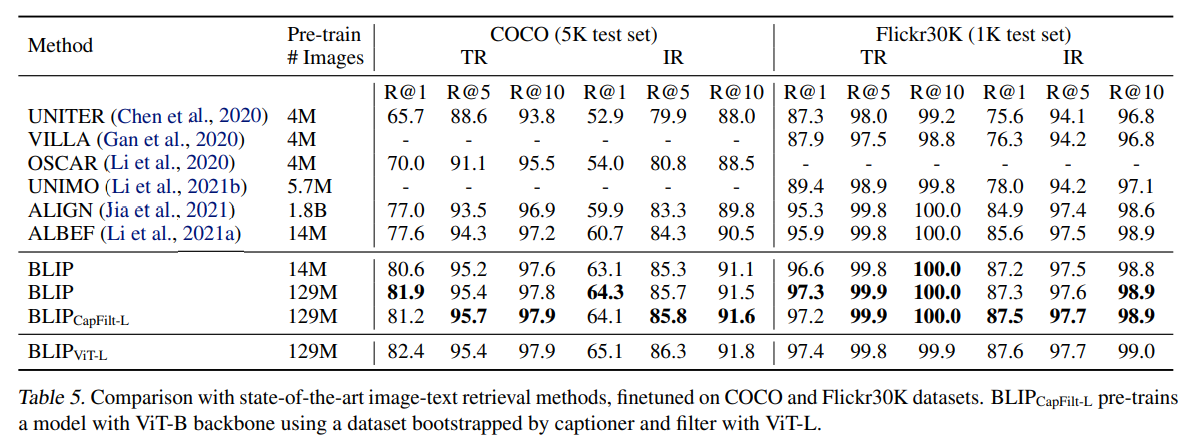
该表格详细比较了BLIP与当前主流视觉-语言模型在图像-文本检索任务上的性能表现,涵盖COCO和Flickr30K两个标准测试集。BLIP(14M)相比同数据量的ALBEF,TR@1提升3.0%,IR@1提升2%,即使相比使用1.8B数据的ALIGN,BLIP仍保持显著优势。扩大数据至129M后,BLIP的性能得到进一步提高。
4.3 BILP的zero-shot能力

如表6所示,BILP的零样本检测能力一样优秀,BLIP仅在(14M)的数据量下训练的性能就远远好于CLIP在(400M)的数据量下训练得到的性能。一方面是因为BLIP的CapFilt可以大幅提高训练集的质量,另一方面是因为BLIP在模态融合端比CLIP做的好很多。
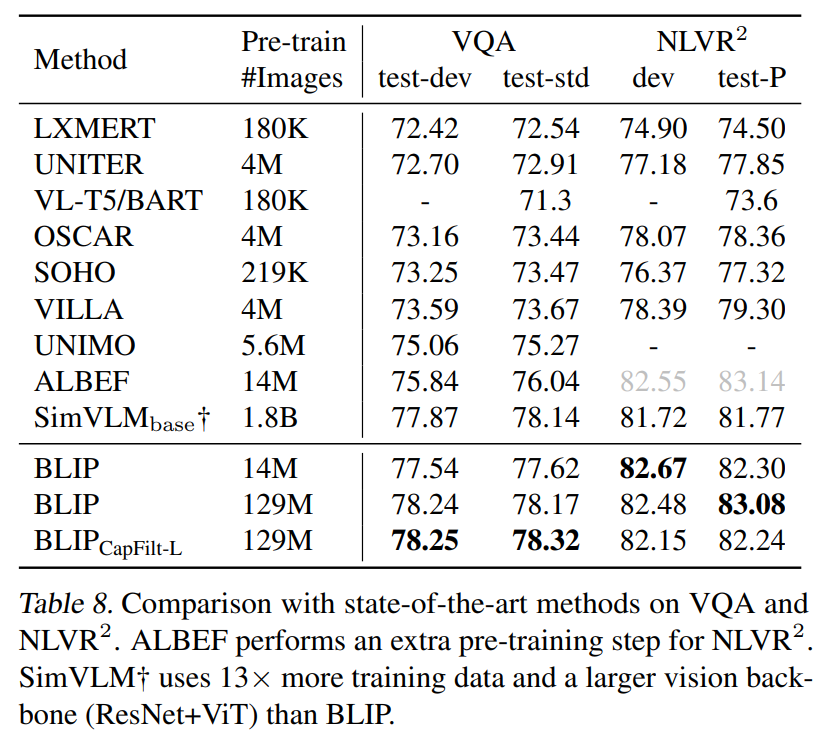
4.4 VQA, NLVR
作者团队也测试了BILP在VQA和NLVR任务上的性能,以证明BILP的图文理解能力:
5. 总结
BLIP这一新型视觉-语言预训练框架通过创新的数据自举策略,从大规模噪声图像-文本对中构建预训练数据集:一方面注入多样化的合成描述,另一方面过滤低质量文本内容,进而训练多模态混合编码器-解码器模型。研究团队同步开源了经过自举处理的数据集,以促进视觉-语言领域的后续探索。
研究者指出三个潜在的性能提升方向:(1) 采用多轮迭代的数据自举流程;(2) 为每张图像生成多条合成描述以进一步扩展预训练语料规模;(3) 通过集成多个异构描述生成器与过滤器的模型组合策略来增强CapFilt机制的有效性。这项研究工作的重要意义在于,它启示后续研究应当同步关注模型架构与数据质量这两个视觉-语言研究的核心要素,为领域发展提供了新的方法论视角。
作者
arwin.yu.98@gmail.com





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1 评论