
1. 简介
大规模预训练基础模型在计算机视觉领域具有重要意义,因为这些模型能够快速迁移至多种下游任务。本研究提出对比-生成双模态模型(Contrastive Captioner, CoCa),该模型采用极简设计,通过联合优化对比损失与生成损失,实现图像-文本编码器-解码器基础模型的预训练,从而兼具CLIP等对比式模型与SimVLM等生成式模型的能力。
与传统编码器-解码器架构(所有解码层均关注编码器输出)不同,CoCa在前半部分解码层中省略跨模态注意力机制以生成单模态文本表征,后半部分解码层则以级联方式对图像编码器输出进行跨模态注意力计算,最终获得多模态图文表征。该模型在单模态图像-文本嵌入之间施加对比损失,同时在多模态解码器输出端采用自回归文本预测的生成损失。由于共享计算图,两个训练目标能以极低开销高效实现。
CoCa的模型设计其实是ALBEF的延展性工作,只是模型更大,数据集超大,把性能堆的超级好。实验表明,CoCa在零样本迁移或极少量任务适配条件下,于视觉识别(ImageNet、Kinetics400/600/700、Moments-in-Time)、跨模态检索(MSCOCO、Flickr30K、MSR-VTT)、多模态理解(VQA、SNLI-VE、NLVR2)及图像描述生成(MSCOCO、NoCaps)等广泛下游任务中达到最先进性能。特别在ImageNet分类任务中,CoCa取得86.3%的零样本Top-1准确率,冻结编码器微调分类头时达90.6%,完整微调后更以91.0%的Top-1准确率刷新当前最佳记录。
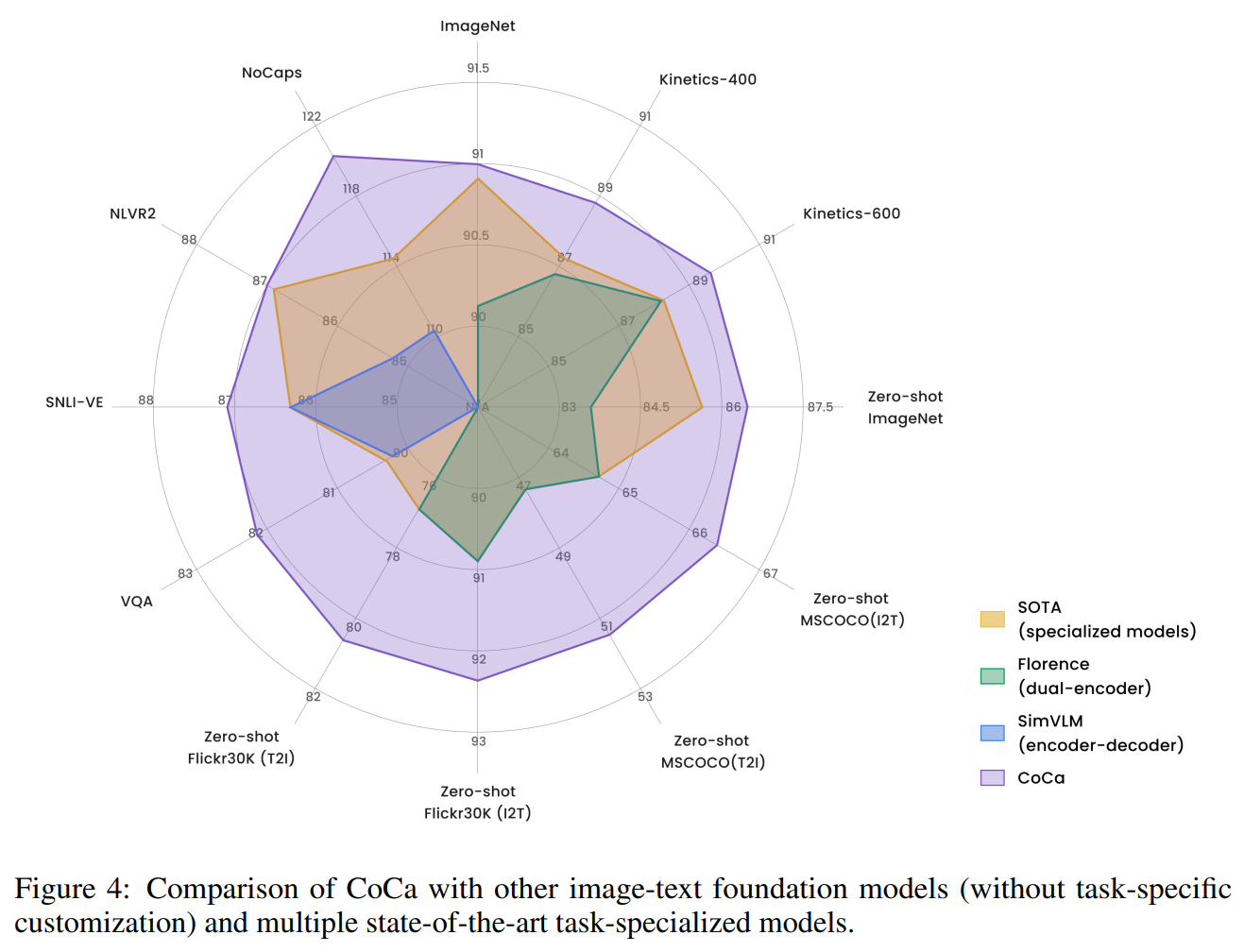
论文中给到了非常直观的一张图。如下所示:
如图4所示,在这个蜘蛛网图中,每个边表征一个数据集(也可以看作一个任务)。黄色阴影是CoCa被提出之前,每个数据集上不同模型能达到的最好的性能(SOTA),紫色则是CoCa能到达的性能,简单说就是吊打图中所有任务的所有SOTA模型。
不过,悄悄的说,我个人感觉这看似恐怖且震撼的性能实际上没有太多贡献,主要是超大训练集支持的...
论文地址:https://arxiv.org/pdf/2205.01917
2. 模型与损失
这张图展示了Contrastive Captioners (CoCa)模型的预训练框架及其应用场景,以及训练所用的损失函数。
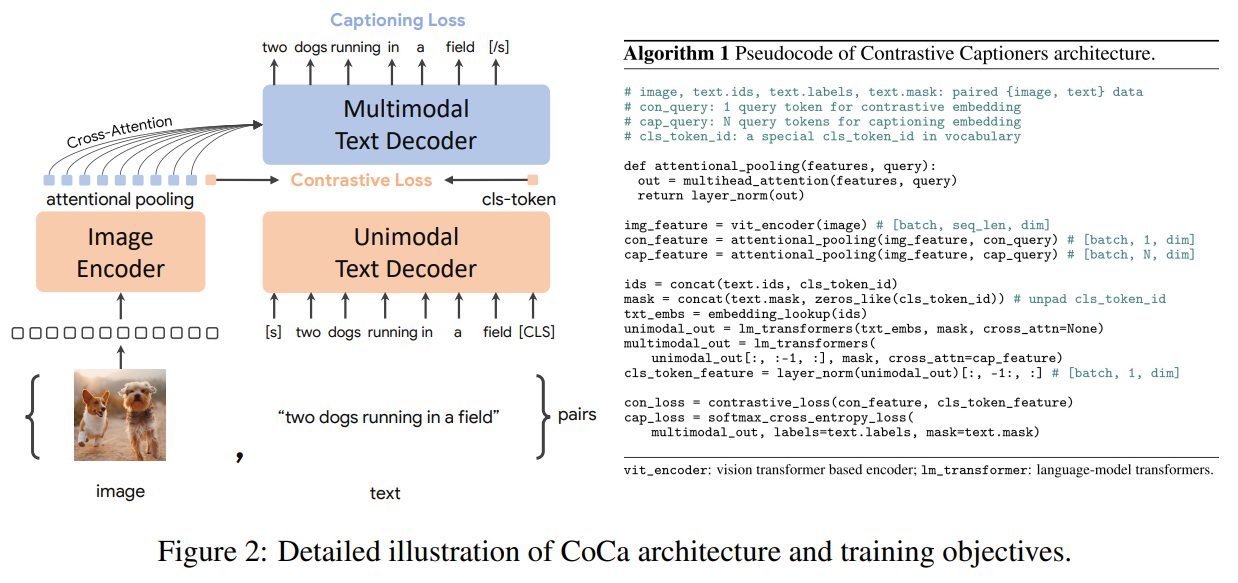
CoCA的模型架构与ALBEF不能说一模一样吧,可以说毫无差别,但在损失函数的选择上是有差异的。具体来说CoCA的损失函数由两部分组成,通过加权联合优化:
1.对比损失(Contrastive Loss)
- 目标:拉近匹配的图像-文本对的特征距离,推开不匹配对。
- 实现方式:
- 计算图像特征 $v_i$ 和文本特征 $t_j$ 的余弦相似度矩阵。
- 采用对称的InfoNCE损失(同CLIP):
$$
\mathcal{L}{\text {cont }}=-\frac{1}{2 N}\left(\sum{i=1}^N \log \frac{e^{s\left(v_i, t_i\right) / \tau}}{\sum_{j=1}^N e^{s\left(v_i, t_j\right) / \tau}}+\sum_{j=1}^N \log \frac{e^{s\left(v_j, t_j\right) / \tau}}{\sum_{i=1}^N e^{s\left(v_i, t_j\right) / \tau}}\right)
$$
-其中 $s(\cdot)$ 为相似度函数,$\tau$ 为温度系数,$N$ 为batch size。
2.生成损失(Captioning Loss)
CoCA的生成损失采用标准的自回归交叉摘损失,具体公式如下:
$$
\mathcal{L}{\text {cap }}=-\sum{t=1}^T \sum_{w \in \mathcal{V}} y_{t, w} \log P\left(w \mid w_{1: t-1}, v\right)
$$
- $T$ :生成文本的最大长度。
- $\mathcal{V}$ :词表集合。
- $y_{t, w}$ :第 $t$ 时刻词 $w$ 的one-hot标签。
- $P\left(w \mid w_{1: t-1}, v\right)$ :基于图像特征 $v$ 和历史词 $w_{1: t-1}$ 的预测概率。
CoCA避免使用ITM(Image-Text Matching)和MLM(Masked Language Modeling)的一个重要原因在于多次前向计算带来的效率瓶颈。ITM需要额外构造负样本对并进行二分类判断,每对图文数据需独立前向计算相似度,显著增加计算开销;而MLM需要对文本随机掩码并逐位置预测,需对同一文本进行多次部分前向传播(掩码位置变化时)。相比之下,CoCA的对比损失(InfoNCE)仅需一次前向计算即可获取整个batch的图文相似度矩阵,生成损失(Captioning)虽需自回归解码,但仅需单向序列建模,避免了MLM的随机掩码带来的计算碎片化。这种设计将多任务计算复杂度从O(N² + T·L)(ITM的负样本对+MLM的掩码位置)降至O(N + T)(N为batch size,T为生成序列长度),更适合端到端的大规模训练。
正是由于生成损失(Captioning)需要自回归建模,CoCA在文本端的特征提取采用了Transformer的Decoder结构而非Encoder。 这一设计的关键区别在于Decoder使用了Masked Multi-Head Attention(MMHA),而非Encoder的标准Multi-Head Attention(MHA)。MMHA通过因果掩码(Causal Mask)强制每个位置仅能关注当前位置及之前的序列信息,从而严格遵循自回归生成的时序依赖(即"预测下一个词仅依赖历史词")。若采用Encoder的MHA(无掩码全局注意力),生成任务会因未来信息泄露导致训练与推理不一致;而对比学习分支在复用同一Decoder时,可临时关闭因果掩码,转为全局注意力以提取完整文本表征。这种灵活切换的注意力机制,既满足了生成任务的自回归约束,又避免了为对比学习单独设计文本编码器的冗余,实现了参数效率与任务性能的平衡。
在文本端使用Decoder而非Encoder可以说是CoCa和ALBEF在模型设计上的唯一区别了。
当模型预训练好以后,可以选用模型的不同部分进行不同的任务处理。例如,选用single-encoder models可以进行图像处理;选用dual-encoder models可以进行图文检索任务;选用encoder-decoder models可以进行生成类任务。如下图:

实验
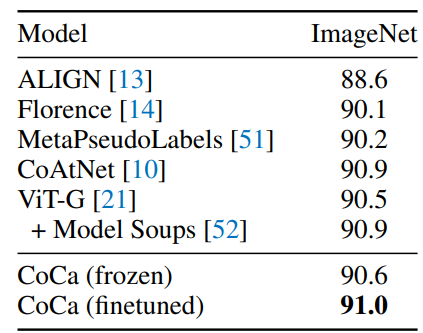
CoCa总的来说是一个卖性能的工作,其效果在简介中的蜘蛛网图4中已经介绍过了。除此之外,预训练后的CoCa在单模态上的性能也非常夸张,例如在ImageNet上可以达到恐怖的91.0的性能。
值得注意的是,CoCa还可以用于视频动作识别。首先,获取视频的多个帧,并将每个帧分别输入到共享图像编码器中,如图 3 所示。对于冻结特征评估或微调,我们在空间和时间特征token的基础上学习一个额外的attention pooling,并使用softmax 交叉熵损失函数。需要注意的是,该池化器只有一个查询token,因此对所有空间和时间标记进行池化计算的开销并不大。对于零样本视频文本检索,我们使用一种更简单的方法,即计算视频 16 帧(帧是从视频中均匀采样的)的平均嵌入。在计算检索指标时,我们还将每个视频的字幕编码为目标嵌入。

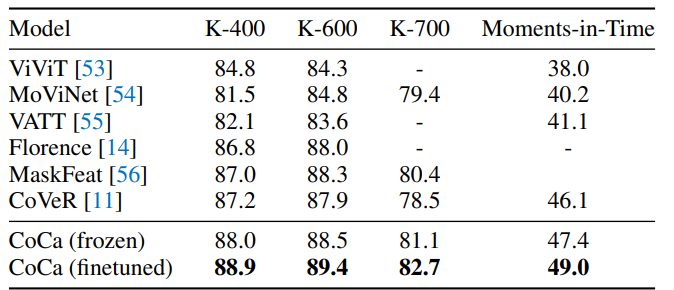
视频任务的效果如上表所示,同样是达到了SOTA的性能。
除此之外,CoCa的作者团队还尝试了其在其他常见任务上的性能,包括zero-shot等能力,消融实验等。原文中有大量的实验结果,详见原论文。.
结论
总的来说,CoCa的卖点除了强大的性能以外,也让大家关注到损失函数选择与计算效率的问题。其舍弃ITM(需负样本对重复计算)和MLM(需随机掩码多步预测)等传统多模态损失,仅保留对比损失(单次前向计算相似度矩阵)和生成损失(自回归解码但无需掩码扰动),可以避免模型在计算损失时需要多次前向计算。因此,CoCa可以在超大的训练集上进行训练。此外,其自身结构也非常简单明了,适合做缩放,因此CoCa团队也在论文中将其做到了有1.2B参数量的大模型,进一步证明了大数据,大模型的重要性。
作者
arwin.yu.98@gmail.com





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1 评论