
1. PaLI:一种联合尺度的多模态模型
大型语言模型(LLM)凭借其强大的扩展能力和灵活的任务接口,已在众多领域展现出卓越性能。而谷歌研究院提出的PaLI(Pathways Language and Image model)将这一成功经验延伸到了多语言,多模态领域,构建了一个能够同时理解图像与文本的通用智能系统。
1.1 模型核心设计
PaLI的创新在于其统一的生成式架构:
- 多模态输入:可同时处理图像和文本数据(例如根据图片生成描述,或回答关于图像的复杂问题)
- 跨语言能力:支持超过100种语言的视觉-语言任务
- 模块化扩展:通过整合预训练的视觉Transformer(ViT)和语言模型,复用已有能力并降低训练成本
研究人员特别发现,视觉与语言模块的协同扩展至关重要。由于传统视觉模型的规模远小于语言模型,团队专门训练了一个40亿参数的巨型ViT(ViT-e),证明了更大容量视觉模型对多模态性能的提升作用。
数据与训练
为训练PaLI,团队构建了迄今规模最大的多模态数据集之一:
- 10亿级图像-文本对,覆盖100+语言
- 多任务预训练混合:包含跨语言对齐、图像描述、视觉问答等多样化任务
1.2 模型架构
在传统AI系统中,不同的任务往往需要不同的模型来处理——例如:
- 图像分类和闭集视觉问答(VQA)需要从固定标签集中预测答案
- 文本生成和图像描述则要求开放式词汇输出
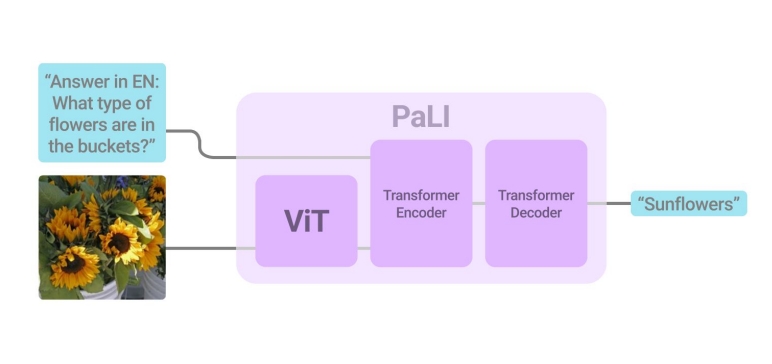
PaLI通过统一的文本生成接口打破了这一界限:
输入:任意图像 + 文本指令
输出:自由格式文本(可适配所有任务)
这种设计灵感来自OFA等前沿工作,但PaLI进一步通过纯提示词(prompt)区分任务类型,无需为不同任务定制模型结构。如下图所示:
PaLI团队训练了截至论文发表时已知的最大的纯视觉Transformer(ViT-e),其核心创新包括:
- 40亿参数规模(是此前ViT-G的2.2倍)
- 双阶段训练策略:
- 第一阶段:使用标准图像裁剪增强
- 第二阶段:关闭增强并降低学习率
- 最终融合两阶段权重("模型汤"技术)
有趣的是,尽管ViT-e在ImageNet分类任务上仅比ViT-G提升有限,但在多模态任务中表现显著更优——例如在COCO图像描述任务中CIDEr指标直接提升3分。这表明视觉模型的扩展对多模态性能的影响远超单模态任务。
PaLI的语言核心基于谷歌的mT5-XXL(130亿参数),这一选择带来两大优势:
- 原生支持101种语言
- 通过混合任务训练防止能力遗忘(在XTREME多语言基准测试中保持原模型水平)
PaLI的实验揭示了一个重要发现:当视觉模型规模突破某个阈值时,多模态任务性能会出现非线性增长。这为未来研究指明方向:
- 开发更大规模的视觉基础模型
- 探索视觉-语言组件的最优比例定律(类似语言模型的Chinchilla定律)
这种"一个模型解决所有问题"的范式,正在重塑多模态AI的发展轨迹——或许不久的将来,我们会看到万亿参数级的视觉-语言统一体诞生。
2. PaLI-X:大力出奇迹
PaLI-X 的四大贡献标志着多模态模型发展的新方向:
- 规模定律验证:视觉+语言组件需协同扩展
- 训练目标创新:混合目标优化学习效率
- 视觉编码器进化:ViT-22B 实现「视觉+OCR」双修
- 通用性突破:单一模型驾驭多样化任务
2.1 视觉+语言组件需协同扩展
作者团队发现,同时扩大 视觉(ViT) 和 语言(mT5) 组件的规模,能持续提升多模态性能,在现有最大规模下(如ViT-22B + 多语言大模型),性能仍未饱和,为未来更大规模的多模态模型训练提供了实证依据,类似「Chinchilla定律」在多模态领域的验证。
2.2 混合目标优化学习效率
结合两种训练目标:
- 前缀补全(Prefix-completion):适合少样本学习(Few-shot)
模型根据输入的部分可见序列(前缀),自动补全后续内容。
训练目标:最大化正确补全序列的概率
输入:图像 + 文本前缀(例如:"这张图片展示了一只____")
输出:生成后续文本(如:"棕色的狗在草地上奔跑")
- 掩码补全(Masked-token completion):提升微调(Fine-tuning)效果
随机遮盖输入文本的部分内容(类似BERT),要求模型预测被遮盖的部分。
输入:图像 + 带掩码的文本(如:"这个[MASK]的价格是$299")
输出:预测被掩码的词(如:"手机")
训练目标:最大化对被遮盖token的正确预测概率
这种混合策略实际上借鉴了:
- 自回归模型(如GPT)的前缀补全优势
- 自编码模型(如BERT)的掩码预测优势
从而实现了「生成能力+理解能力」的双重突破,为多模态模型提供了一种新的训练范式。
作者团队声称,经过调参,模型在「少样本学习」和「微调性能」之间找到更优平衡点,突破传统多模态模型的帕累托前沿(Pareto frontier)。
注:这一概念源自经济学家维尔弗雷多·帕累托,原指资源分配中「无法让任何人更好而不损害他人」的状态。在AI中,我们将其转化为「多目标竞争的平衡艺术」。
2.3 ViT-22B 实现「视觉+OCR」双修
作者团队使用 220亿参数 ViT-22B 同时训练传统图像分类和OCR 标签分类(识别图像中的文本),显著提升需要「图文联合理解」的任务表现(如带文字的VQA、文档分析)。
2.4 通用性突破
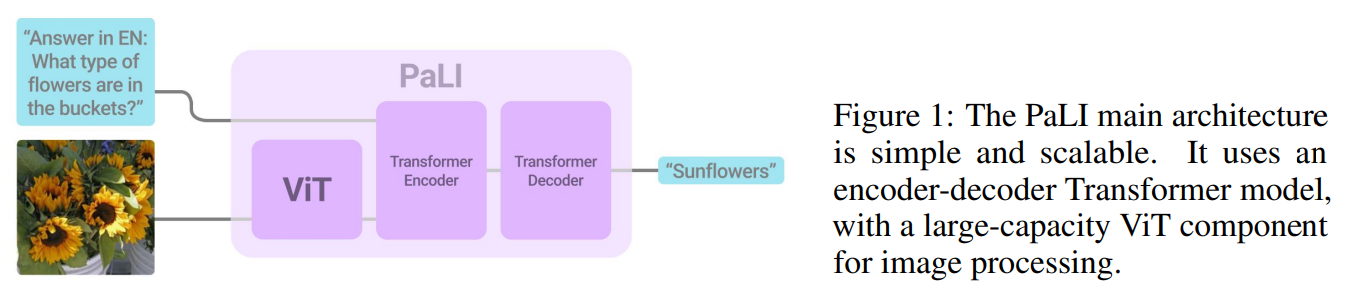
作者展示了PaLI-X的强大性能,在 15+ 基准测试 中刷新SOTA。首次实现 单一模型 同时适应多种任务微调,且无明显性能衰减。最后附上一张PaLI-X和PaLI的性能对比表。
PaLI-3:更小,更快,更强
PaLI-3 研究通过 PaLI 框架 对比了两种视觉预训练范式(分类预训练 vs. 对比学习预训练)。并在多模态理解任务中实现了高效、小体积、强泛化的突破。以下是核心发现的逐项解读:
3.1 视觉预训练范式的关键对比
实验设计:
- 分类预训练 ViT(传统方法,如 ImageNet 监督训练)
- 对比学习预训练 SigLIP(基于图文对齐的对比学习)
结果如下所示:
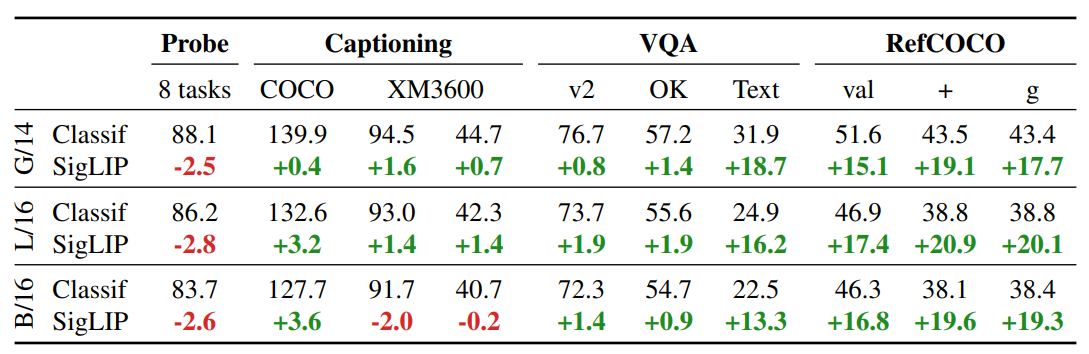
上图表示使用相同的 PaLI 设置,对比预训练模型(“SigLIP”)和分类预训练模型(“Classif”)ViT 图像编码器在各种任务中的性能比较。虽然线性分类小样本探测(第一列)表明 SigLIP 编码器在许多任务中表现较差,但当将其接入 PaLI 并迁移到其他任务中时,尤其是多模态任务,它们表现出明显的改进。
在最复杂、最细致的图像理解任务中,SigLIP 模型的表现远超 Classif 模型。
意义:
验证了对比学习更适合视觉-语言联合建模,因其能捕捉细粒度的图文语义对齐。
3.2 小模型,大性能
突破性成果:
- 在 10+ 视觉-语言基准测试 中刷新 SOTA
- 模型体积仅为当前 SOTA(Chen et al., 2023a)的 1/10
- 视觉文本理解任务 提升尤为显著(如 TextVQA 准确率 +7%)
技术关键:
- PaLI-3 延续了 PaLI 系列的模块化理念,复用已有预训练模型而非从零构建,这种设计减少重复训练成本,同时保留各模块的专精能力,总参数量仅为5B(视觉2B + 语言3B),是同性能模型的1/10体量。
- PaLI-3 的核心创新在于采用 SigLIP(Sigmoid Loss for Language-Image Pre-training) 方法,相比传统 CLIP,使用 Sigmoid 交叉熵替代 Softmax,降低计算复杂度,支持更大批量训练,基于模型自动筛选 WebLI 数据集中40%高质量图文对,提升训练效率。
- 分阶段训练策略:精度与速度的平衡。PaLI-3 的训练分为三个阶段,逐步释放模型潜力:
- 单模态预训练:
- 视觉模块以224×224分辨率进行对比学习,语言模块通过混合降噪任务预训练。
- 冻结视觉编码器,避免多模态训练初期参数动荡。
- 多模态融合:
- 固定视觉编码器,仅训练语言模块与跨模态注意力层,减少计算量。
- 使用 SplitCap 目标增强图文关联性。
- 高分辨率微调:
- 解冻视觉编码器,逐步提升分辨率至1064×1064,捕捉细节(如文档中的小文字)
- 单模态预训练:
- PaLI-3 在后期引入动态分辨率调整:常规任务使用812×812分辨率,文档理解任务升级至1064×1064。这种设计在提升细粒度理解能力的同时,控制计算复杂度。
3.3 零样本视频理解能力
意外发现:
尽管 未使用任何视频数据预训练,模型在多个视频问答基准(如 TVQA、ActivityNet-QA)上仍达到 SOTA。
原因分析:
- SigLIP 的对比学习使模型学会帧级语义抽象
- 多模态联合训练赋予强大的时序推理泛化能力
3.4 多语言跨模态检索新标杆
新模型发布:
- 20亿参数 ViT-G SigLIP
- 训练数据:WebLI(覆盖 100+ 语言的超大规模图文对)
性能表现:
在 36 种语言 的跨模态检索基准(Thapliyal et al., 2022)上全面超越前人工作,尤其对低资源语言(如斯瓦希里语、孟加拉语)提升显著。
作者
arwin.yu.98@gmail.com





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1 评论