
1.引用
这篇论文提出了一种名为 Uni-Perceiver 的通用感知架构,旨在解决当前机器学习任务特定范式的局限性,并模仿生物智能系统的多模态整合与并行处理能力。当前机器学习模型通常针对单一任务独立设计,导致任务间协作效率低且开发新任务的边际成本较高。相比之下,生物系统能够高效整合视觉、听觉等多模态信息,同时处理多种任务。Uni-Perceiver 通过统一建模和共享参数实现了多模态(如图像、文本、音频)和多任务(如分类、检测、生成)的协同处理。其对比如下图1所示:
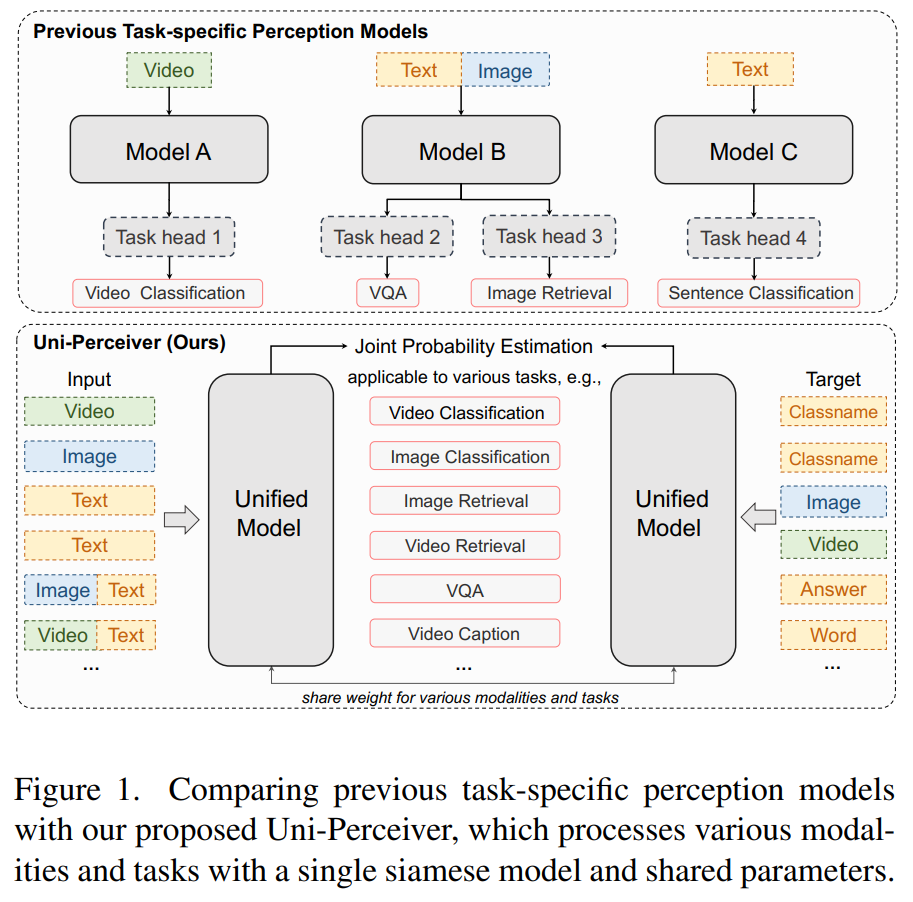
模型层面,Uni-Perceiver 的核心设计包括三个部分:一是 模态无关的Transformer编码器,将不同模态的输入和目标映射到统一表示空间;二是 轻量级模态特定分词器,用于将原始数据转换为模型可处理的token,仅需少量参数适配;三是 任务统一建模,所有任务均被转化为输入与目标的表示相似度计算问题。在预训练阶段,模型通过多种单模态和多模态任务学习通用表示;在下游任务中,它支持零样本推理、少量数据提示调优和全数据微调。实验表明,预训练模型在未见任务上表现合理,而仅用1%下游数据调优即可接近SOTA性能,全微调后甚至能超越现有最佳方法。
这一研究的创新点在于通过统一任务建模和参数共享,显著降低了多任务开发的边际成本,同时提升了模型的泛化能力。Uni-Perceiver 的灵活部署方式(零样本、提示调优、全微调)使其适用于不同资源场景,为构建通用AI系统提供了新思路。未来研究可进一步探索模态统一与任务性能的平衡,以及计算效率的优化。论文作者还开源了代码和预训练权重,推动了通用感知模型的后续发展。总体而言,这项工作在多模态多任务学习领域迈出了重要一步,为高效、通用的机器学习模型设计提供了重要参考。
最后,uni-perceiver是一个系列模型,也包括uni-perceiver,uni-perceiverV2,本博文都会提及。原文链接如下:
- uni-perceiver论文地址:https://openaccess.thecvf.com/content/CVPR2022/papers/Zhu_Uni-Perceiver_Pre-Training_Unified_Architecture_for_Generic_Perception_for_Zero-Shot_and_CVPR_2022_paper.pdf
- uni-perceiver-moe论文地址:https://proceedings.neurips.cc/paper_files/paper/2022/file/11fc8c98b46d4cbdfe8157267228f7d7-Paper-Conference.pdf
- uni-perceiver-v2论文地址:http://openaccess.thecvf.com/content/CVPR2023/papers/Li_Uni-Perceiver_v2_A_Generalist_Model_for_Large-Scale_Vision_and_Vision-Language_CVPR_2023_paper.pdf
2. Uni-Perceiver 模型
不同模态的数据,在送进模型之前要进行Token化,即Embedding。
输入Token化 具体来说:
- 文本:使用BPE分词器(如BERT等模型采用的方式)
- 图像:拆分成图像块(类似ViT的patch划分)
- 视频:按时间帧分块处理
- 每种Token会附带模态类型嵌入(Modality Type Embedding),告诉模型当前输入是文本、图像还是视频。
- 每种Token也会附带位置嵌入(Modality Pos Embedding),帮助attention建模单模态自身的特征。
- 如下图所示:
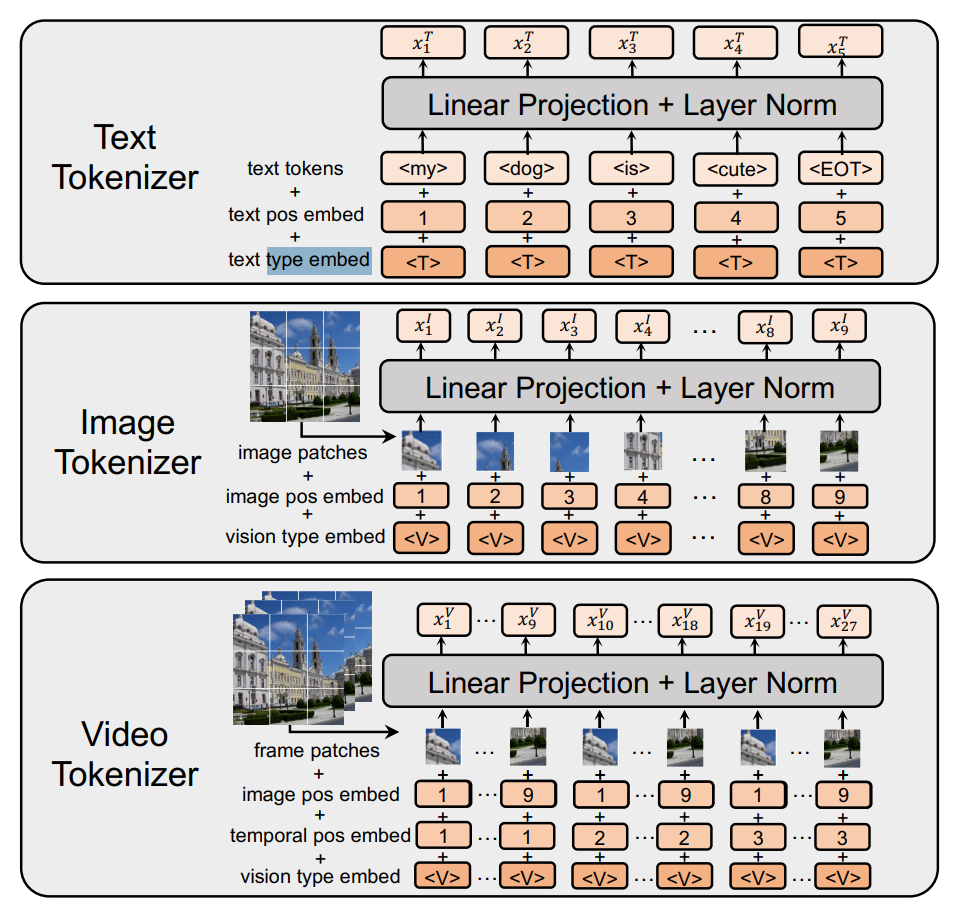
模型的输入序列可以自由组合不同模态的Token,例如:
- 图文任务 →
[<SPE>, 图像Token, 文本Token] - 纯视频任务 →
[<SPE>, 视频Token]
其中<SPE>是一个特殊起始标记,它的输出特征会作为整个输入的全局表示。
所有模态的Token序列都由同一个Transformer模型处理,输出统一语义空间中的特征。不同任务(如分类、检索)通过比较输入和目标的特征相似度来实现(例如:计算最大似然得分)。如下图所示:
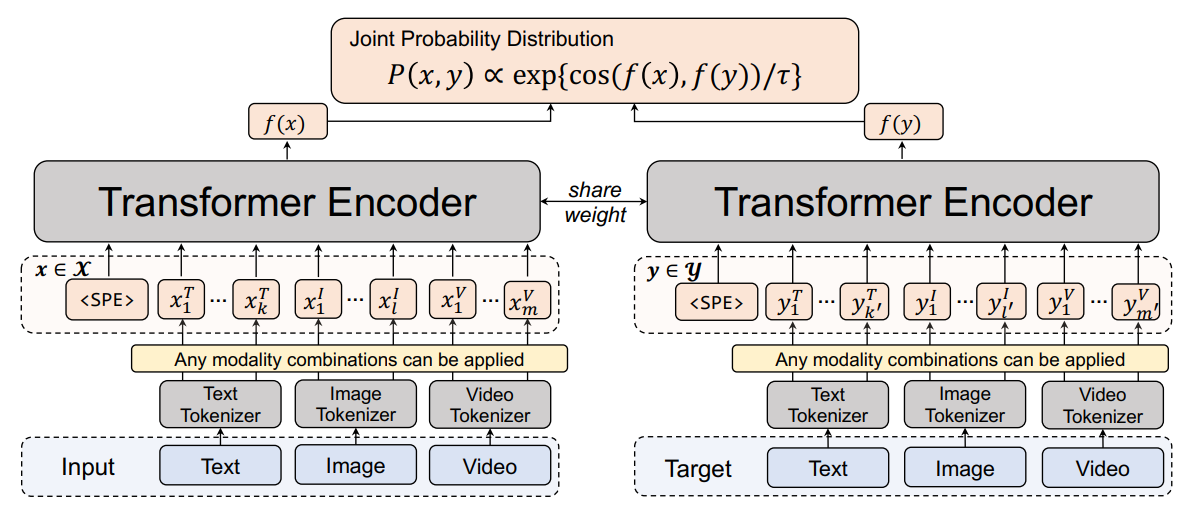
UniPerceiver的核心设计思想——用同一个模型处理不同任务(如分类、检索),且支持文本、图像、视频等多种输入形式。其关键是通过最大化输入与目标的联合概率来统一建模,具体来说,无论什么任务(例如图像分类、视频检索),都可以抽象为:
- 输入(x):一张图、一段文本或视频
- 候选目标(y):可能的答案(如类别标签、描述文本)
模型的目标是找到与输入最匹配的 $\mathbf{y}$ ,公式表示为:
$$
\hat{y}=\arg \max _{y \in \mathcal{Y}} P(x, y)
$$
其中, $\mathrm{P}(\mathrm{x}, \mathrm{y})$ 衡量输入 x 和目标 y 的匹配程度,通过以下方式计算:
- 特征提取:用共享的Transformer编码器( $f(\cdot)$ )将x和y映射到同一语义空间。
- 相似度计算:用余弦相似度比较两者的特征,并通过温度参数 $\tau$(可学习)调整分布平滑度:
$$
P(x, y) \propto \exp (\cos (f(x), f(y)) / \tau)
$$
为了让模型泛化到不同任务,作者用多种任务的数据同时训练(如图文匹配、视频分类等)。预训练的损失函数设计如下:
$$
L=\sum_{i=1}^n \mathbb{E}{{x, y}}\left[-\log \frac{P(x, y)}{\sum{z \in \mathcal{Y}_i} P(x, z)}\right]
$$
-核心思想:对于每个任务的数据,让真实配对( $\mathrm{x}, \mathrm{y}$ )的 $\mathrm{P}(\mathrm{x}, \mathrm{y})$ 远高于其他候选目标 z (类似对比学习)。
-数学含义:最小化该损失,相当于要求模型对正样本的匹配概率尽可能大,负样本尽可能小。
个人认为,Uni-perceiver就是在CLIP工作的基础之上再进了一步,超越CLIP的地方:
- 模态无关:不局限于图文,支持任意组合。
- 任务无关:分类、检索、生成等任务统一建模。
- 目标自由:y可以是任何形式,只要能被Token化。
如果CLIP是“专才”(擅长图文对比),UniPerceiver就是“通才”(什么任务都能插一手)
除此之外,CLIP的双塔结构参数不共享,而Uni-perceiver的双塔结构则是参数共享的。这样做有以下几个好处:
参数效率更高
- CLIP:图像和文本编码器完全分离,参数量随模态增加线性增长(例如新增音频模态需额外训练一个编码器)。
- UniPerceiver:所有模态共用同一套参数,新增模态只需扩展Tokenizer,主干模型保持不变。
→ 更节省显存和训练资源,尤其适合多模态扩展。
模态交互更彻底
- CLIP:图像和文本仅在相似度计算时交互,前期编码过程完全隔离,可能丢失细粒度对齐信息。
- UniPerceiver:输入序列直接混合多模态Token(如
[图像Token][文本Token]),在Transformer的自注意力机制中实时交互。
→ 更适合需要深度融合的任务(例如视频问答需同时理解画面和字幕)。
避免模态偏差
- CLIP的双塔问题:独立编码器可能导致图像和文本特征分布不一致(例如文本特征更稀疏),需额外设计损失函数对齐。
- UniPerceiver的解决方案:强制所有模态通过同一组参数映射到完全共享的语义空间,天然对齐特征分布。
灵活应对非常规任务
- CLIP的局限:难以处理目标不是文本的任务(例如图像→图像检索)。
- UniPerceiver的通用性:
- 目标可以是任意形式(如
y=图像、视频、结构化数据)。 - 甚至支持多模态联合目标(例如输入医学影像,输出
[诊断文本][病变区域图像]的组合)。
- 目标可以是任意形式(如
当然,这种形式也存在它的缺点,我个人认为,因为多任务之间的偏差和数据差异,这种形式大概率存在巨大的训练难度。关于训练的细节,我在论文中并未发现太多的细节,只有下述两句简单的描述。
We pre-train the model with multiple tasks simultaneously. In each iteration, each GPU independently samples a single task and dataset. The gradients of different GPUs are synchronized after the gradient back-propagation.
3. Uni-Perceiver-MoE 模型
Uni-Perceiver-MoE的主要的贡献就是加入了混合专家机制MoE。具体来说,是 条件混合专家(Conditional Mixture-of-Experts, Conditional MoEs) 机制,通过动态路由策略,实现了多模态、多任务场景下的高效计算与任务解耦。
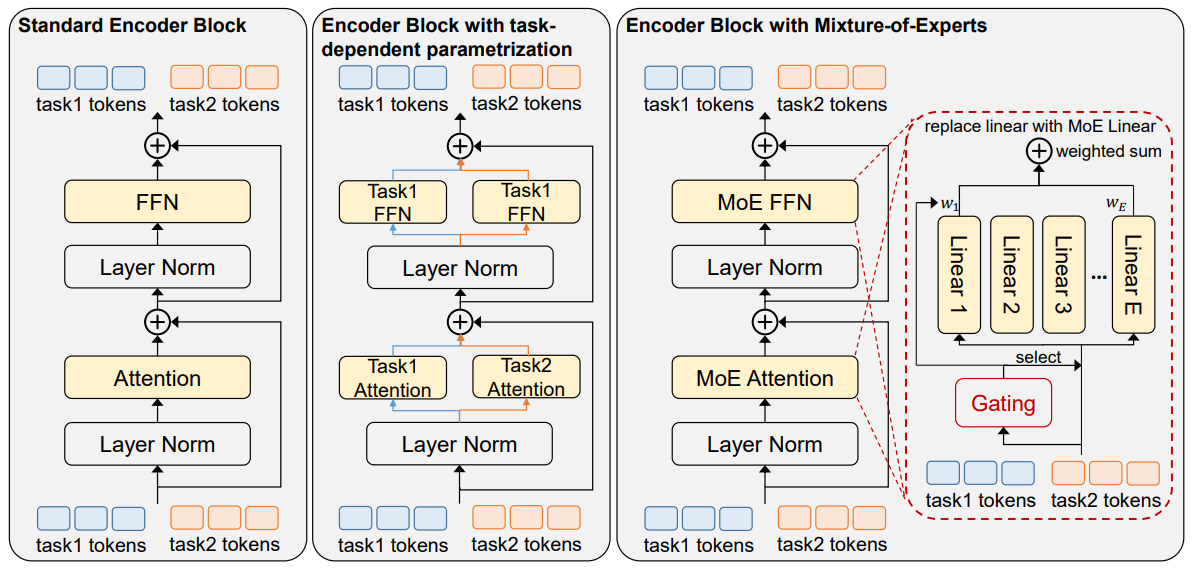
1.Conditional MoEs 的核心机制
1.1基本原型
-输入与路由:
对输入序列中的每个 token $x_i$ ,通过路由函数 $R(\cdot)$ 生成门控决策向量 $\mathcal{G} \in \mathbb{R}^E(E$为专家数量),选择 top-$k$ 个专家激活:
$$
\mathcal{G}=\operatorname{top}_k\left(\operatorname{softmax}\left(\mathbf{W}_g \cdot R\left(x_i\right)+\epsilon\right)\right)
$$
- $\mathbf{W}_g$ :可训练的门控权重矩阵。
$\circ \epsilon$ :噪声项(可能用于增强鲁棒性)。
- 稀疏性:仅 $k \ll E$ 个专家被激活,显著减少计算量。
- 输出计算:
被选中的专家对 $x_i$ 的线性变换结果加权求和:
$$
y_i=\sum_{e=1}^E \mathcal{G}_e \cdot \mathbf{W}_e \cdot x_i
$$
-未被选中的专家( $\mathcal{G}_e=0$ )无需计算。
1.2 路由策略 $R(\cdot)$ 的作用
路由策略是 Conditional MoEs 的关键,决定了如何根据输入条件(如模态、任务、上下文)分配专家。其设计直接影响模型的多任务泛化能力和模态适应性。
2.路由策略的变体
2.1 Token-Level Routing(token级路由)
-策略:直接使用 token 自身的表示作为路由依据:
$$
R_{\text {token }}\left(x_i\right)=x_i
$$
- 特点:
- 类似传统 MoE(如Switch Transformer),仅依赖局部信息。
- 适用于同质化输入(如单一模态文本),但对多任务/多模态可能因任务冲突导致干扰。
2.2 Context-Level Routing(上下文级路由)
-策略:结合 token 表示与全局上下文(通过注意力池化):
$$
R_{\text {context }}\left(x_i\right)=\operatorname{concat}\left(x_i, \operatorname{attnpool}(X)\right)
$$
- 特点:
- 引入序列全局信息,缓解相似 token 在不同任务中的冲突。
- 适合需要长距离依赖的任务(如视频理解)。
2.3 Modality-Level Routing(模态级路由)
-策略:根据 token 的模态类型(如文本、图像)分配专家:
$$
R_{\text {modal }}\left(x_i\right)=\operatorname{embed}\left(\operatorname{id}_{\text {modal }}\left(x_i\right)\right)
$$
- 特点:
- 显式区分模态,类似传统多模态模型的独立编码器。
- 但可能削弱跨模态交互能力。
2.4 Task-Level Routing(任务级路由)
-策略:基于任务 ID 分配专家:
$$
R_{\text {task }}\left(x_i\right)=\operatorname{embed}\left(\operatorname{id}_{\text {task }}\left(x_i\right)\right)
$$
- 特点:
- 同一任务的所有 token 共享专家,彻底避免任务干扰。
- 局限性:无法泛化到新任务(需预定义任务 ID)。
2.5 Attribute Routing(属性路由)
-策略:综合 token 的多种属性(模态、任务类型、因果性等)生成路由:
$$
R_{\mathrm{attr}}\left(x_i\right)=\text { layernorm }\left(\mathbf{W}_{\mathrm{attr}} \cdot \operatorname{attr}\left(x_i\right)\right)
$$
属性为 8 维二进制嵌入(如模态索引、任务类型等),详见下表。

- 特点:
- 平衡任务解耦与泛化能力:既包含任务信息,又避免依赖固定 ID。
- 适合通用模型(Generalist Models),如 Uni-Perceiver 的多任务场景。
上述MoE的不同设计可以从是否依赖数据进行分析,具体来说:
数据依赖(Data-Dependent):
- Token-Level & Context-Level MoEs:路由决策依赖输入数据的具体内容(如 token 表示或上下文)。
- 优点:不损害模型对新任务的泛化能力。
- 缺点:训练和推理时内存消耗高(需加载所有专家),需通过模型并行缓解,但会引入设备间通信开销。此外,忽略任务信息,无法解决任务间干扰(Task Interference)。
数据独立(Data-Independent):
- Modality-Level/Task-Level/Attribute MoEs:路由决策依赖预定义的模态/任务/属性标签,与输入内容无关。
- 优点:
- 内存高效:只需激活与当前模态/任务相关的 top-k 专家。
- 计算优化:可通过参数重参数化(reparameterization)合并专家。
- 缺点:Modality-Level 和 Task-Level依赖预定义任务 ID,难以泛化到新任务。
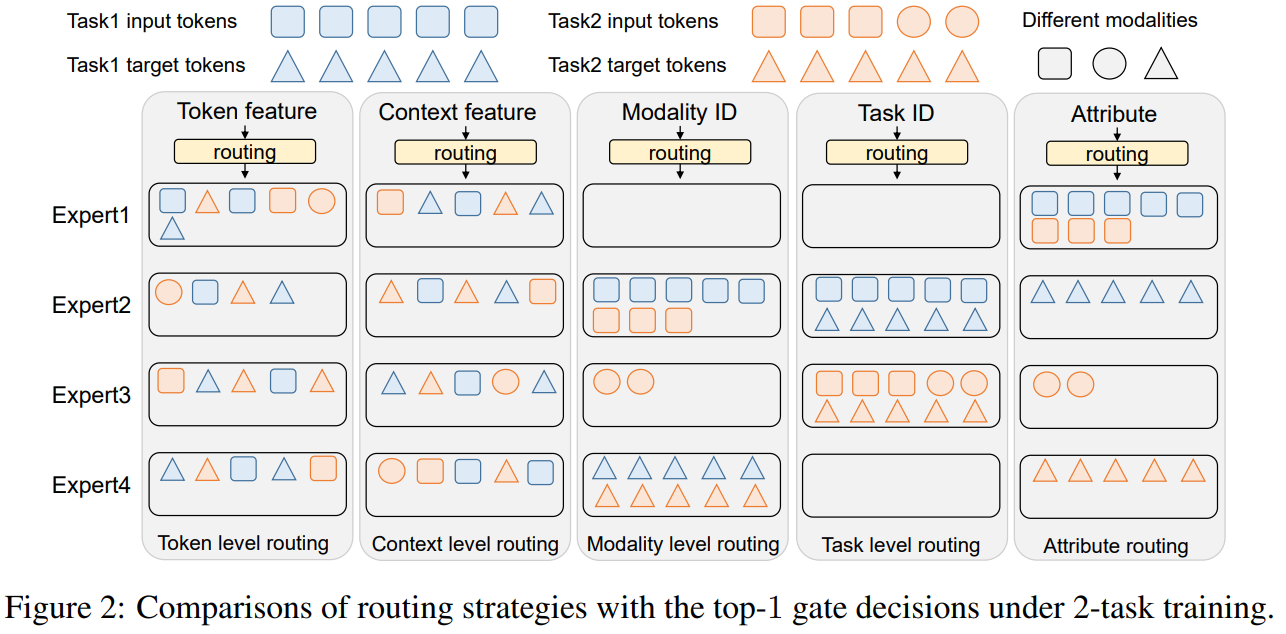
属性路由(Attribute MoEs):通过预定义的属性(如模态、任务类型等)编码任务信息,既缓解任务干扰,又支持新任务迁移(无需修改模型结构),是平衡效率与泛化的最佳选择。文中也展示了不同路由方式的消融实验,结果如下:
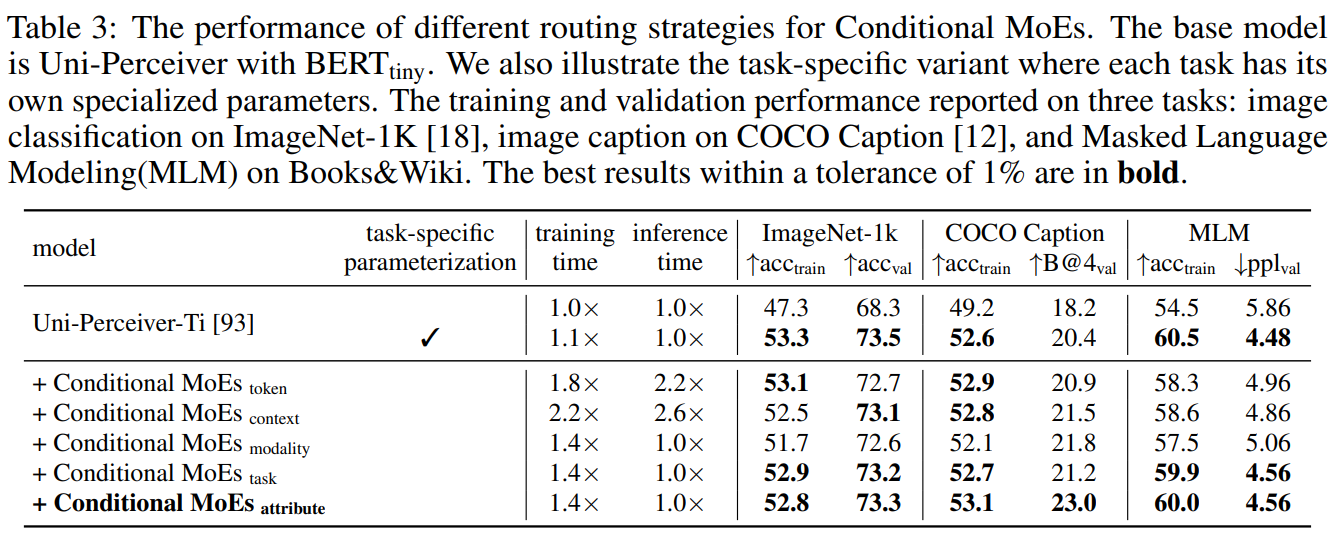
不管是理论上,还是实验上,属性级别路由选择都是最优的。
此外,个人认为,Modality-Level Routing(模态级路由)应该与VLMO工作非常类似。或者说,VLMo 可视为 Modality-Level Routing 的一种极端情况(无动态学习)。若将 Uni-Perceiver-MoE 的 Modality-Level Routing 设置为:
- 门控权重 Wg 固定为模态到专家的硬映射。
- 模态嵌入(
embed(id_modal))为 one-hot 向量。
则退化为 VLMo 的静态模态专家分配。VLMo 是面向视觉-语言任务的专用设计,通过静态分离专家最大化模态特异性,但牺牲了灵活性和扩展性。
若需构建统一的多模态大模型,Uni-Perceiver-MoE 的策略更具优势;若仅需高效的双模态处理(如图文检索),VLMo 的简单性可能更合适。
4. Uni-perceiver v2
UniPerceiver v2作为多模态统一感知框架的升级版本,其核心创新体现在数据表征的细粒度重构与多任务训练的梯度平衡机制两大维度。以下从技术原理与工程实践角度展开分析:
4.1 模型结构
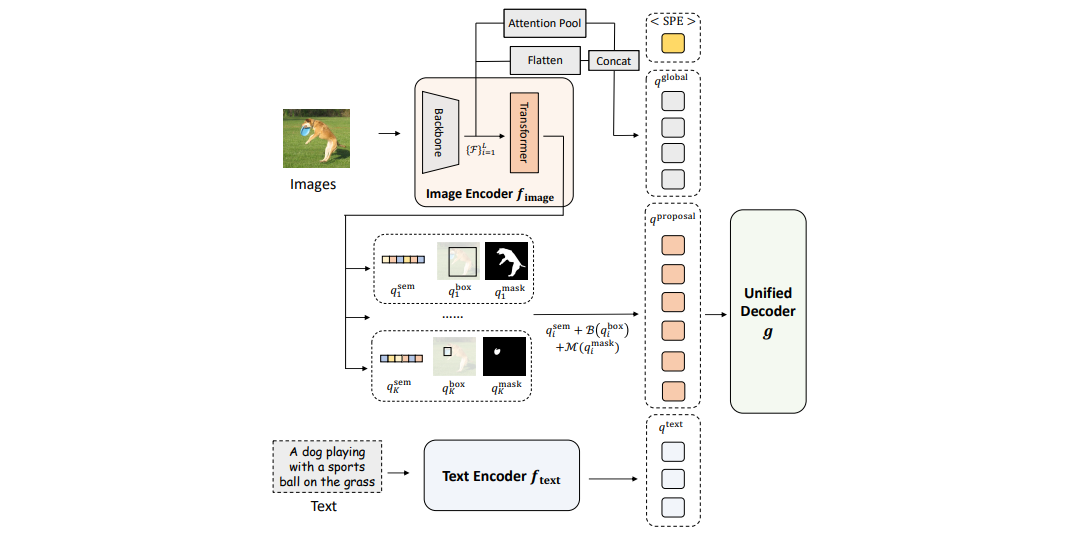
传统视觉编码器倾向于提取全局特征(如CNN的高层语义特征),但在目标检测、实例分割等任务中,空间定位精度与局部语义区分度直接影响模型性能。UniPerceiver v2通过以下双重改进实现特征层级的细粒度解耦,其模型结构如下:

如上图所示,我们主要看看视觉端口的处理,分别有两个子网络构成:Backbone 和 Region Proposal Network(即图中橙色背景的Transformer矩形)。根据原文描述:
主干网络(Backbone)
- 输入处理
输入图像尺寸为H×W,通过ResNet或Swin-Transformer等主干网络提取多尺度特征图,共4个层级(L=4)。各层级特征图尺寸依次为:- Level 0: H/4 × W/4
- Level 1: H/8 × W/8
- Level 2: H/16 × W/16
- Level 3: H/32 × W/32
- 特征调整
- 使用1×1卷积对齐特征图通道维度(隐藏维度d=256)。
- 对Level 3特征额外应用3×3卷积(步长2),生成更小尺寸的Level 4特征图(H/64 × W/64)。
- 全局注意力池化保留前10个显著特征(M0=10)。
Region Proposal Network
- 编码阶段
- 输入为Level 1至Level 4的多尺度特征图。
- 使用可变形Transformer编码器提取编码特征,保留原始空间尺寸和维度。
- 解码与候选生成
- 候选查询构建:
对编码特征图进行逐像素预测,生成目标置信度(objectness score)和边界框,从中选择置信度最高的N=900个特征点作为候选基。 - Transformer解码器:
将候选基与随机初始化的对象查询融合,生成N个候选提议。每个提议包含:- 语义特征(q_sem):256维向量
- 边界框坐标(q_box):4维坐标
- 分割掩码(q_mask):H×W二值掩码(通过多层卷积与上采样生成)
- 候选查询构建:
- 特征融合
将三者融合为最终区域表示:
$$
q_{\text {proposal }}=q_{\text {sem }}+B\left(q_{\text {box }}\right)+M\left(q_{\text {mask }}\right)
$$
- B(•):边界框坐标的位置编码
- M(•):掩码自适应池化至 $28 \times 28$ 尺寸后线性投影
- 根据目标置信度筛选 200个候选,作为最终区域表示以降低计算量。
4.2 训练策略
在Uni-Perceiver v2中,作者提出了一种名为 Task-Balanced Gradient Normalization 的梯度优化策略,用于解决多任务联合训练中的梯度不稳定问题。
在多任务学习中,常见的两种数据采样策略存在缺陷:
- 混合采样(Mixed Sampling):
- 每个训练迭代(iteration)混合所有任务的数据。
- 问题:每个任务的批次大小(batch-size)被迫减小,尤其不利于需要大批次的任务(如图文检索)。
- 非混合采样(Unmixed Sampling):
- 每个迭代仅采样一个任务的数据,可最大化单任务的批次大小。
- 问题:不同任务的梯度方向和量级差异大,导致训练不稳定和性能下降。
Task-Balanced Gradient Normalization 的核心思想是通过 梯度归一化 和 任务补偿系数 平衡不同任务的梯度贡献。以下是公式的逐步拆解:

关键改进点解析:
1.梯度归一化:
- 将当前任务的梯度 $\nabla L_{t, k}$ 除以其范数 $\left|\nabla L_{t, k}\right|$ ,转化为单位向量(方向不变,量级统一为 1 )。
- 作用:消除不同任务梯度量级的差异,避免某些任务主导更新方向。
2.平衡系数 $\omega_k$ :
可手动设定的权重,控制任务 $k$ 的梯度贡献。若所有任务重要性相同,则设 $\omega_k=1$ 。
3.任务补偿系数 $1 / s_k$ :
$s_k$ 是任务 $k$ 的采样概率(如任务A占训练数据的 $20 \%$ ,则 $s_k=0.2$ )。
-作用:对低频任务( $s_k$ 小)的梯度进行放大 $\left(\frac{1}{s_k}>1\right)$ ,避免其梯度被高频任务淹没。
5. 总结
UniPerceiver v2,这是第一个在主要的大规模视觉和视觉语言任务上取得竞争性结果的通用模型。在单模态和多模态任务上进行联合训练后,UniPerceiver v2 在广泛的下游任务上取得了具有竞争力的性能。至于局限性,由于计算资源有限,我们的方法尚未在图像生成任务上得到验证。
作者
arwin.yu.98@gmail.com





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}